 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing All-to-X Backdoor Attacks with Optimized Target Class Mapping
Nov 17, 2025



Backdoor attacks pose severe threats to machine learning systems, prompting extensive research in this area. However, most existing work focuses on single-target All-to-One (A2O) attacks, overlooking the more complex All-to-X (A2X) attacks with multiple target classes, which are often assumed to have low attack success rates. In this paper, we first demonstrate that A2X attacks are robust against state-of-the-art defenses. We then propose a novel attack strategy that enhances the success rate of A2X attacks while maintaining robustness by optimizing grouping and target class assignment mechanisms. Our method improves the attack success rate by up to 28%, with average improvements of 6.7%, 16.4%, 14.1% on CIFAR10, CIFAR100, and Tiny-ImageNet, respectively. We anticipate that this study will raise awareness of A2X attacks and stimulate further research in this under-explored area. Our code is available at https://github.com/kazefjj/A2X-backdoor .
Robust Radar HRRP Recognition under Non-uniform Jamming Based on Complex-valued Frequency Attention Network
Nov 16, 2025Complex electromagnetic environments, often containing multiple jammers with different jamming patterns, produce non-uniform jamming power across the frequency spectrum. This spectral non-uniformity directly induces severe distortion in the target's HRRP, consequently compromising the performance and reliability of conventional HRRP-based target recognition methods. This paper proposes a novel, end-to-end trained network for robust radar target recognition. The core of our model is a CFA module that operates directly on the complex spectrum of the received echo. The CFA module learns to generate an adaptive frequency-domain filter, assigning lower weights to bands corrupted by strong jamming while preserving critical target information in cleaner bands. The filtered spectrum is then fed into a classifier backbone for recognition. Experimental results on simulated HRRP data with various jamming combinations demonstrate our method's superiority. Notably, under severe jamming conditions, our model achieves a recognition accuracy nearly 9% higher than traditional model-based approaches, all while introducing negligible computational overhead. This highlights its exceptional performance and robustness in challenging jamming environments.
Learning Time in Static Classifiers
Nov 15, 2025



Real-world visual data rarely presents as isolated, static instances. Instead, it often evolves gradually over time through variations in pose, lighting, object state, or scene context. However, conventional classifiers are typically trained under the assumption of temporal independence, limiting their ability to capture such dynamics. We propose a simple yet effective framework that equips standard feedforward classifiers with temporal reasoning, all without modifying model architectures or introducing recurrent modules. At the heart of our approach is a novel Support-Exemplar-Query (SEQ) learning paradigm, which structures training data into temporally coherent trajectories. These trajectories enable the model to learn class-specific temporal prototypes and align prediction sequences via a differentiable soft-DTW loss. A multi-term objective further promotes semantic consistency and temporal smoothness. By interpreting input sequences as evolving feature trajectories, our method introduces a strong temporal inductive bias through loss design alone. This proves highly effective in both static and temporal tasks: it enhances performance on fine-grained and ultra-fine-grained image classification, and delivers precise, temporally consistent predictions in video anomaly detection. Despite its simplicity, our approach bridges static and temporal learning in a modular and data-efficient manner, requiring only a simple classifier on top of pre-extracted features.
CometNet: Contextual Motif-guided Long-term Time Series Forecasting
Nov 11, 2025



Long-term Time Series Forecasting is crucial across numerous critical domains, yet its accuracy remains fundamentally constrained by the receptive field bottleneck in existing models. Mainstream Transformer- and Multi-layer Perceptron (MLP)-based methods mainly rely on finite look-back windows, limiting their ability to model long-term dependencies and hurting forecasting performance. Naively extending the look-back window proves ineffective, as it not only introduces prohibitive computational complexity, but also drowns vital long-term dependencies in historical noise. To address these challenges, we propose CometNet, a novel Contextual Motif-guided Long-term Time Series Forecasting framework. CometNet first introduces a Contextual Motif Extraction module that identifies recurrent, dominant contextual motifs from complex historical sequences, providing extensive temporal dependencies far exceeding limited look-back windows; Subsequently, a Motif-guided Forecasting module is proposed, which integrates the extracted dominant motifs into forecasting. By dynamically mapping the look-back window to its relevant motifs, CometNet effectively harnesses their contextual information to strengthen long-term forecasting capability. Extensive experimental results on eight real-world datasets have demonstrated that CometNet significantly outperforms current state-of-the-art (SOTA) methods, particularly on extended forecast horizons.
What Makes Reasoning Invalid: Echo Reflection Mitigation for Large Language Models
Nov 09, 2025



Large Language Models (LLMs) have demonstrated remarkable performance across a wide range of reasoning tasks. Recent methods have further improved LLM performance in complex mathematical reasoning. However, when extending these methods beyond the domain of mathematical reasoning to tasks involving complex domain-specific knowledge, we observe a consistent failure of LLMs to generate novel insights during the reflection stage. Instead of conducting genuine cognitive refinement, the model tends to mechanically reiterate earlier reasoning steps without introducing new information or perspectives, a phenomenon referred to as "Echo Reflection". We attribute this behavior to two key defects: (1) Uncontrollable information flow during response generation, which allows premature intermediate thoughts to propagate unchecked and distort final decisions; (2) Insufficient exploration of internal knowledge during reflection, leading to repeating earlier findings rather than generating new cognitive insights. Building on these findings, we proposed a novel reinforcement learning method termed Adaptive Entropy Policy Optimization (AEPO). Specifically, the AEPO framework consists of two major components: (1) Reflection-aware Information Filtration, which quantifies the cognitive information flow and prevents the final answer from being affected by earlier bad cognitive information; (2) Adaptive-Entropy Optimization, which dynamically balances exploration and exploitation across different reasoning stages, promoting both reflective diversity and answer correctness. Extensive experiments demonstrate that AEPO consistently achieves state-of-the-art performance over mainstream reinforcement learning baselines across diverse benchmarks.
A Support-Set Algorithm for Optimization Problems with Nonnegative and Orthogonal Constraints
Nov 05, 2025In this paper, we investigate optimization problems with nonnegative and orthogonal constraints, where any feasible matrix of size $n \times p$ exhibits a sparsity pattern such that each row accommodates at most one nonzero entry. Our analysis demonstrates that, by fixing the support set, the global solution of the minimization subproblem for the proximal linearization of the objective function can be computed in closed form with at most $n$ nonzero entries. Exploiting this structural property offers a powerful avenue for dramatically enhancing computational efficiency. Guided by this insight, we propose a support-set algorithm preserving strictly the feasibility of iterates. A central ingredient is a strategically devised update scheme for support sets that adjusts the placement of nonzero entries. We establish the global convergence of the support-set algorithm to a first-order stationary point, and show that its iteration complexity required to reach an $\epsilon$-approximate first-order stationary point is $O (\epsilon^{-2})$. Numerical results are strongly in favor of our algorithm in real-world applications, including nonnegative PCA, clustering, and community detection.
Inverse Knowledge Search over Verifiable Reasoning: Synthesizing a Scientific Encyclopedia from a Long Chains-of-Thought Knowledge Base
Oct 30, 2025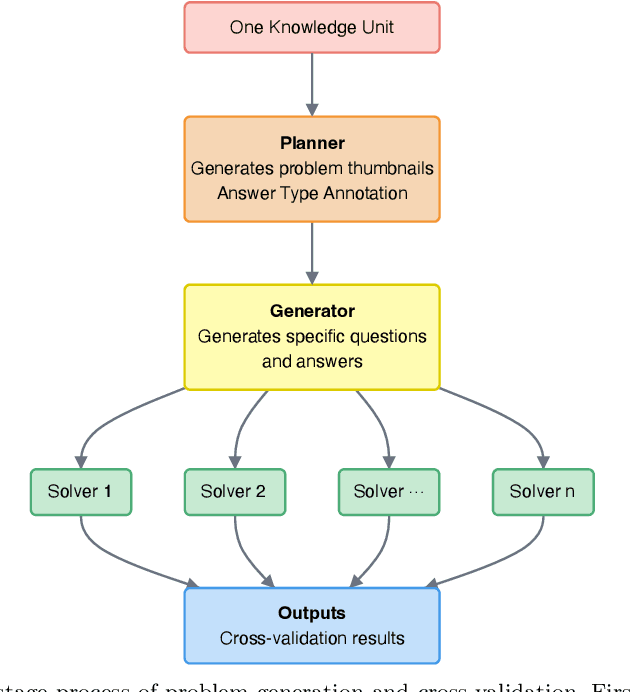
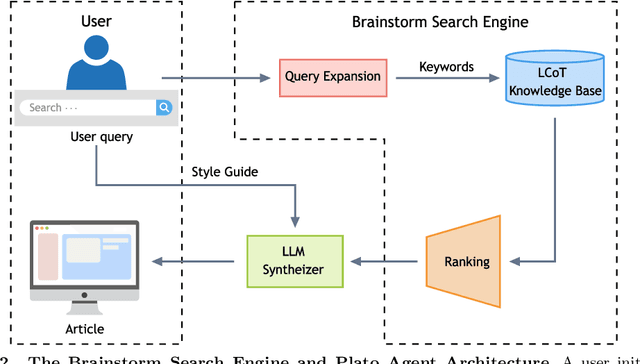
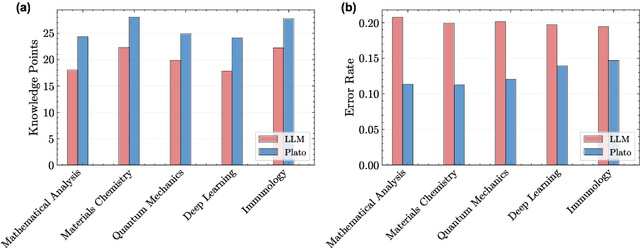
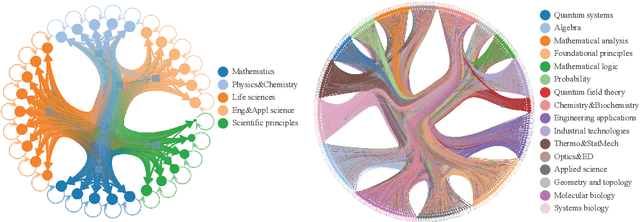
Most scientific materials compress reasoning, presenting conclusions while omitting the derivational chains that justify them. This compression hinders verification by lacking explicit, step-wise justifications and inhibits cross-domain links by collapsing the very pathways that establish the logical and causal connections between concepts. We introduce a scalable framework that decompresses scientific reasoning, constructing a verifiable Long Chain-of-Thought (LCoT) knowledge base and projecting it into an emergent encyclopedia, SciencePedia. Our pipeline operationalizes an endpoint-driven, reductionist strategy: a Socratic agent, guided by a curriculum of around 200 courses, generates approximately 3 million first-principles questions. To ensure high fidelity, multiple independent solver models generate LCoTs, which are then rigorously filtered by prompt sanitization and cross-model answer consensus, retaining only those with verifiable endpoints. This verified corpus powers the Brainstorm Search Engine, which performs inverse knowledge search -- retrieving diverse, first-principles derivations that culminate in a target concept. This engine, in turn, feeds the Plato synthesizer, which narrates these verified chains into coherent articles. The initial SciencePedia comprises approximately 200,000 fine-grained entries spanning mathematics, physics, chemistry, biology, engineering, and computation. In evaluations across six disciplines, Plato-synthesized articles (conditioned on retrieved LCoTs) exhibit substantially higher knowledge-point density and significantly lower factual error rates than an equally-prompted baseline without retrieval (as judged by an external LLM). Built on this verifiable LCoT knowledge base, this reasoning-centric approach enables trustworthy, cross-domain scientific synthesis at scale and establishes the foundation for an ever-expanding encyclopedia.
A Review of Longitudinal Radiology Report Generation: Dataset Composition, Methods, and Performance Evaluation
Oct 14, 2025Chest Xray imaging is a widely used diagnostic tool in modern medicine, and its high utilization creates substantial workloads for radiologists. To alleviate this burden, vision language models are increasingly applied to automate Chest Xray radiology report generation (CXRRRG), aiming for clinically accurate descriptions while reducing manual effort. Conventional approaches, however, typically rely on single images, failing to capture the longitudinal context necessary for producing clinically faithful comparison statements. Recently, growing attention has been directed toward incorporating longitudinal data into CXR RRG, enabling models to leverage historical studies in ways that mirror radiologists diagnostic workflows. Nevertheless, existing surveys primarily address single image CXRRRG and offer limited guidance for longitudinal settings, leaving researchers without a systematic framework for model design. To address this gap, this survey provides the first comprehensive review of longitudinal radiology report generation (LRRG). Specifically, we examine dataset construction strategies, report generation architectures alongside longitudinally tailored designs, and evaluation protocols encompassing both longitudinal specific measures and widely used benchmarks. We further summarize LRRG methods performance, alongside analyses of different ablation studies, which collectively highlight the critical role of longitudinal information and architectural design choices in improving model performance. Finally, we summarize five major limitations of current research and outline promising directions for future development, aiming to lay a foundation for advancing this emerging field.
KAIROS: Unified Training for Universal Non-Autoregressive Time Series Forecasting
Oct 02, 2025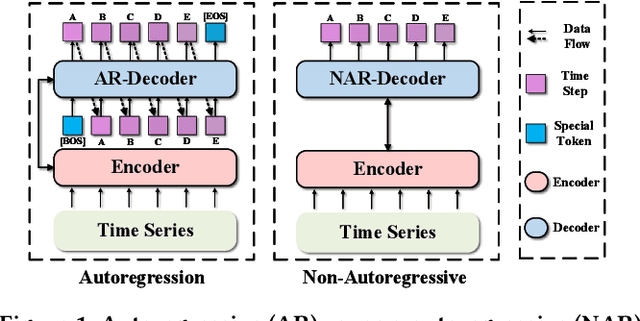

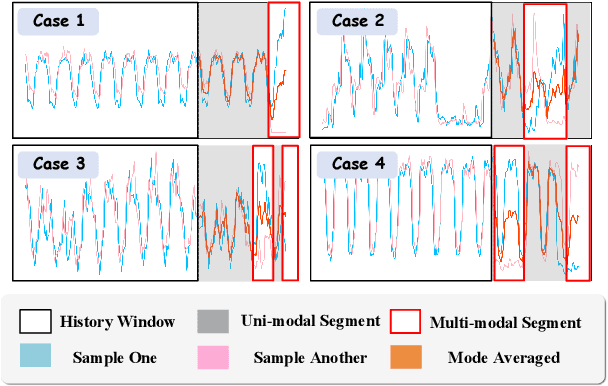
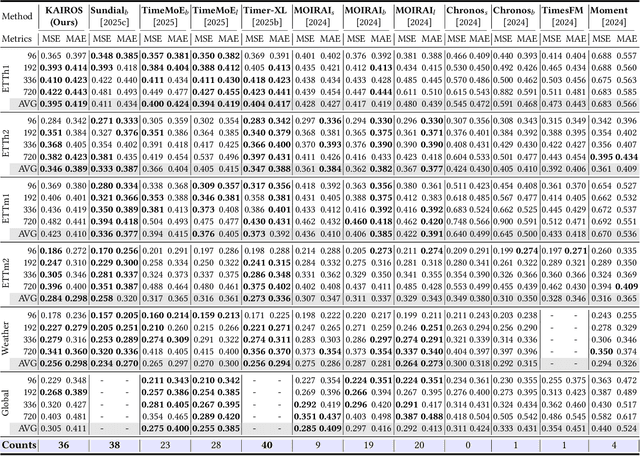
In the World Wide Web, reliable time series forecasts provide the forward-looking signals that drive resource planning, cache placement, and anomaly response, enabling platforms to operate efficiently as user behavior and content distributions evolve. Compared with other domains, time series forecasting for Web applications requires much faster responsiveness to support real-time decision making. We present KAIROS, a non-autoregressive time series forecasting framework that directly models segment-level multi-peak distributions. Unlike autoregressive approaches, KAIROS avoids error accumulation and achieves just-in-time inference, while improving over existing non-autoregressive models that collapse to over-smoothed predictions. Trained on the large-scale corpus, KAIROS demonstrates strong zero-shot generalization on six widely used benchmarks, delivering forecasting performance comparable to state-of-the-art foundation models with similar scale, at a fraction of their inference cost. Beyond empirical results, KAIROS highlights the importance of non-autoregressive design as a scalable paradigm for foundation models in time series.
Adaptive LoRA Experts Allocation and Selection for Federated Fine-Tuning
Sep 18, 2025Large Language Models (LLMs) have demonstrated impressive capabilities across various tasks, but fine-tuning them for domain-specific applications often requires substantial domain-specific data that may be distributed across multiple organizations. Federated Learning (FL) offers a privacy-preserving solution, but faces challenges with computational constraints when applied to LLMs. Low-Rank Adaptation (LoRA) has emerged as a parameter-efficient fine-tuning approach, though a single LoRA module often struggles with heterogeneous data across diverse domains. This paper addresses two critical challenges in federated LoRA fine-tuning: 1. determining the optimal number and allocation of LoRA experts across heterogeneous clients, and 2. enabling clients to selectively utilize these experts based on their specific data characteristics. We propose FedLEASE (Federated adaptive LoRA Expert Allocation and SElection), a novel framework that adaptively clusters clients based on representation similarity to allocate and train domain-specific LoRA experts. It also introduces an adaptive top-$M$ Mixture-of-Experts mechanism that allows each client to select the optimal number of utilized experts. Our extensive experiments on diverse benchmark datasets demonstrate that FedLEASE significantly outperforms existing federated fine-tuning approaches in heterogeneous client settings while maintaining communication efficiency.