 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrbax: Distributed Checkpointing with JAX
May 26, 2026In a landscape of high-performance distributed ML systems, JAX has emerged as a framework of choice. However, JAX's modular design philosophy leaves it without a standardized checkpointing solution. In this paper, we introduce Orbax, a modular, JAX-native checkpointing library that abstracts the complexities of distributed accelerator systems while also providing flexibility for user-friendly checkpoint manipulations throughout the ML model lifecycle. We demonstrate performance exceeding comparable PyTorch competitors by up to 3.5$\times$ for saving and 2$\times$ for loading. The library is available at https://github.com/google/orbax.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Structured Model Pruning of Convolutional Networks on Tensor Processing Units
Jul 21, 2021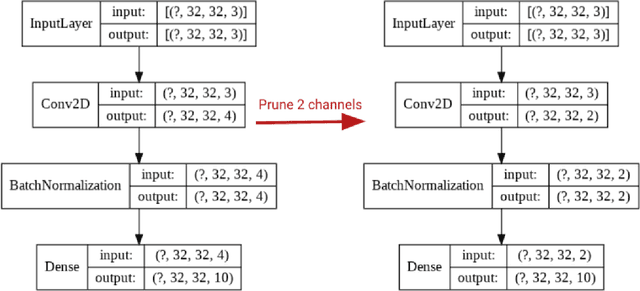
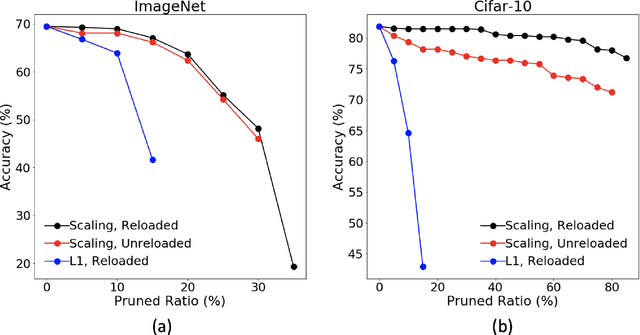
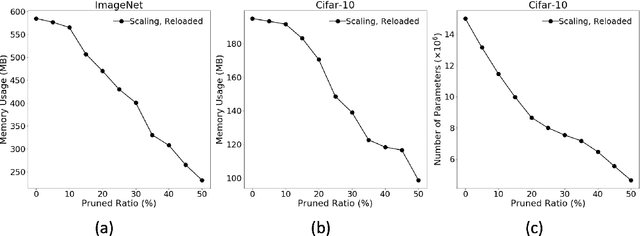
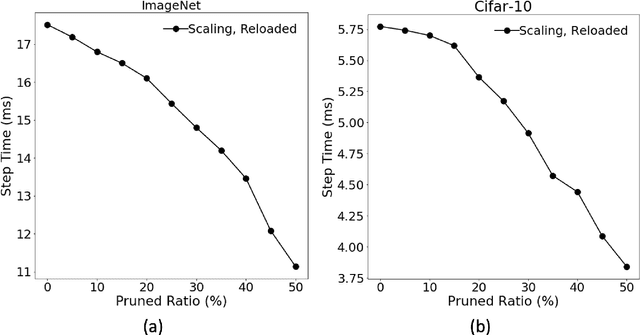
The deployment of convolutional neural networks is often hindered by high computational and storage requirements. Structured model pruning is a promising approach to alleviate these requirements. Using the VGG-16 model as an example, we measure the accuracy-efficiency trade-off for various structured model pruning methods and datasets (CIFAR-10 and ImageNet) on Tensor Processing Units (TPUs). To measure the actual performance of models, we develop a structured model pruning library for TensorFlow2 to modify models in place (instead of adding mask layers). We show that structured model pruning can significantly improve model memory usage and speed on TPUs without losing accuracy, especially for small datasets (e.g., CIFAR-10).
Ranking Neural Checkpoints
Nov 23, 2020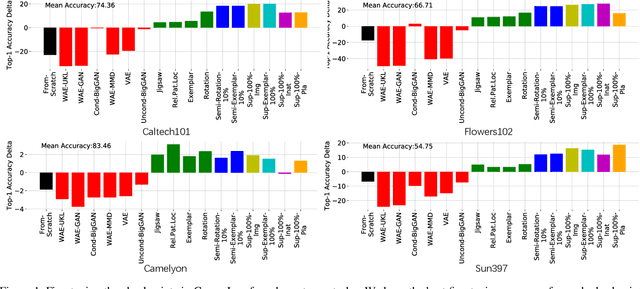
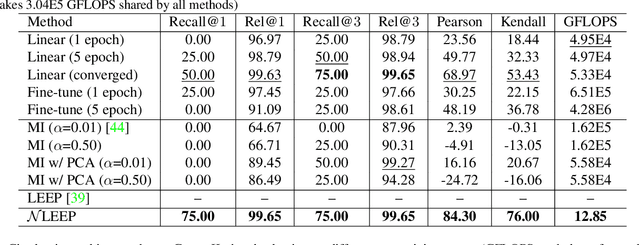
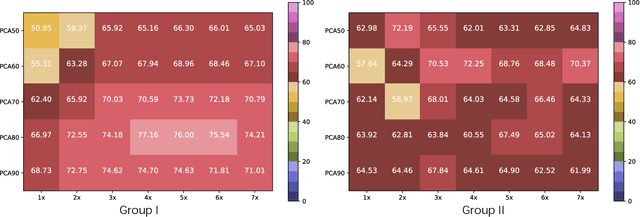
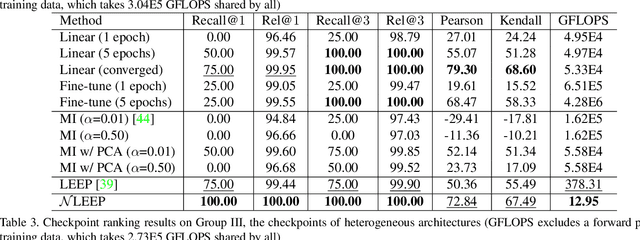
This paper is concerned with ranking many pre-trained deep neural networks (DNNs), called checkpoints, for the transfer learning to a downstream task. Thanks to the broad use of DNNs, we may easily collect hundreds of checkpoints from various sources. Which of them transfers the best to our downstream task of interest? Striving to answer this question thoroughly, we establish a neural checkpoint ranking benchmark (NeuCRaB) and study some intuitive ranking measures. These measures are generic, applying to the checkpoints of different output types without knowing how the checkpoints are pre-trained on which dataset. They also incur low computation cost, making them practically meaningful. Our results suggest that the linear separability of the features extracted by the checkpoints is a strong indicator of transferability. We also arrive at a new ranking measure, NLEEP, which gives rise to the best performance in the experiments.