 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
AlphaStar Unplugged: Large-Scale Offline Reinforcement Learning
Aug 07, 2023



StarCraft II is one of the most challenging simulated reinforcement learning environments; it is partially observable, stochastic, multi-agent, and mastering StarCraft II requires strategic planning over long time horizons with real-time low-level execution. It also has an active professional competitive scene. StarCraft II is uniquely suited for advancing offline RL algorithms, both because of its challenging nature and because Blizzard has released a massive dataset of millions of StarCraft II games played by human players. This paper leverages that and establishes a benchmark, called AlphaStar Unplugged, introducing unprecedented challenges for offline reinforcement learning. We define a dataset (a subset of Blizzard's release), tools standardizing an API for machine learning methods, and an evaluation protocol. We also present baseline agents, including behavior cloning, offline variants of actor-critic and MuZero. We improve the state of the art of agents using only offline data, and we achieve 90% win rate against previously published AlphaStar behavior cloning agent.
Improving Multimodal Interactive Agents with Reinforcement Learning from Human Feedback
Nov 21, 2022An important goal in artificial intelligence is to create agents that can both interact naturally with humans and learn from their feedback. Here we demonstrate how to use reinforcement learning from human feedback (RLHF) to improve upon simulated, embodied agents trained to a base level of competency with imitation learning. First, we collected data of humans interacting with agents in a simulated 3D world. We then asked annotators to record moments where they believed that agents either progressed toward or regressed from their human-instructed goal. Using this annotation data we leveraged a novel method - which we call "Inter-temporal Bradley-Terry" (IBT) modelling - to build a reward model that captures human judgments. Agents trained to optimise rewards delivered from IBT reward models improved with respect to all of our metrics, including subsequent human judgment during live interactions with agents. Altogether our results demonstrate how one can successfully leverage human judgments to improve agent behaviour, allowing us to use reinforcement learning in complex, embodied domains without programmatic reward functions. Videos of agent behaviour may be found at https://youtu.be/v_Z9F2_eKk4.
Intra-agent speech permits zero-shot task acquisition
Jun 07, 2022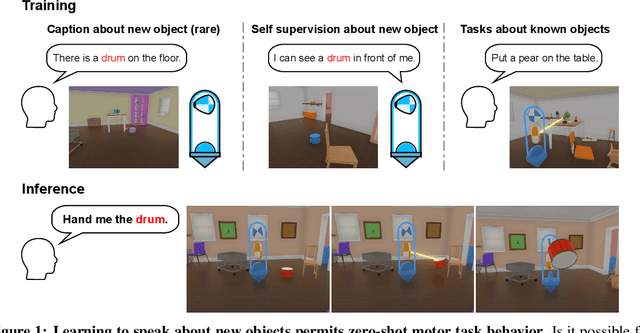
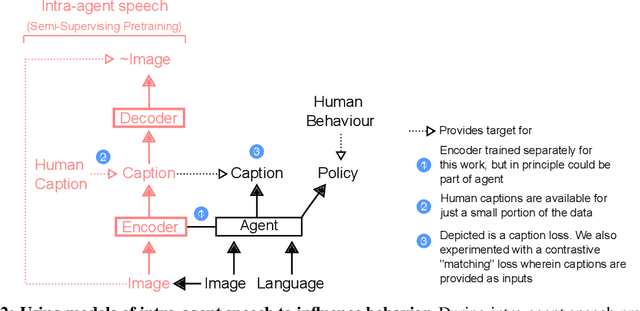

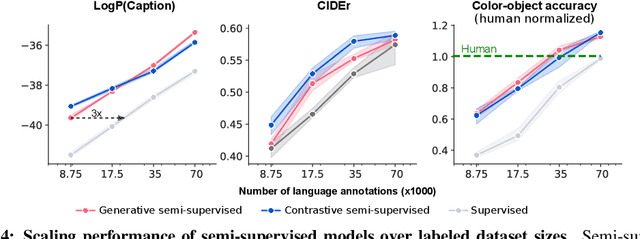
Human language learners are exposed to a trickle of informative, context-sensitive language, but a flood of raw sensory data. Through both social language use and internal processes of rehearsal and practice, language learners are able to build high-level, semantic representations that explain their perceptions. Here, we take inspiration from such processes of "inner speech" in humans (Vygotsky, 1934) to better understand the role of intra-agent speech in embodied behavior. First, we formally pose intra-agent speech as a semi-supervised problem and develop two algorithms that enable visually grounded captioning with little labeled language data. We then experimentally compute scaling curves over different amounts of labeled data and compare the data efficiency against a supervised learning baseline. Finally, we incorporate intra-agent speech into an embodied, mobile manipulator agent operating in a 3D virtual world, and show that with as few as 150 additional image captions, intra-agent speech endows the agent with the ability to manipulate and answer questions about a new object without any related task-directed experience (zero-shot). Taken together, our experiments suggest that modelling intra-agent speech is effective in enabling embodied agents to learn new tasks efficiently and without direct interaction experience.
Evaluating Multimodal Interactive Agents
May 26, 2022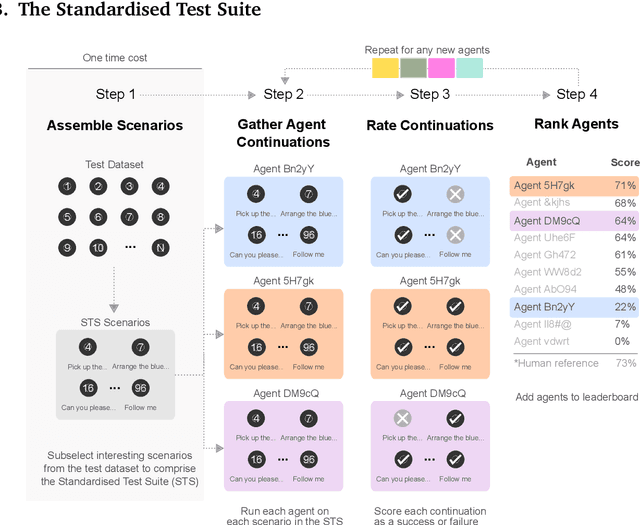
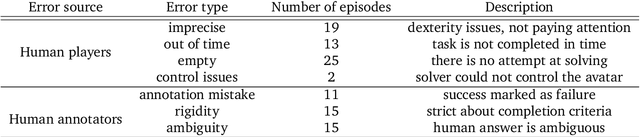
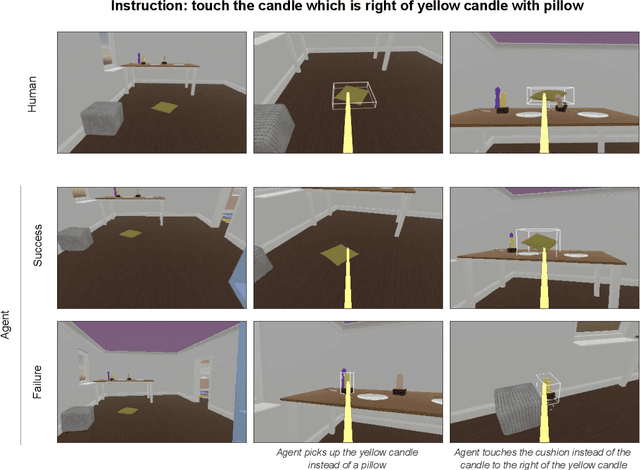
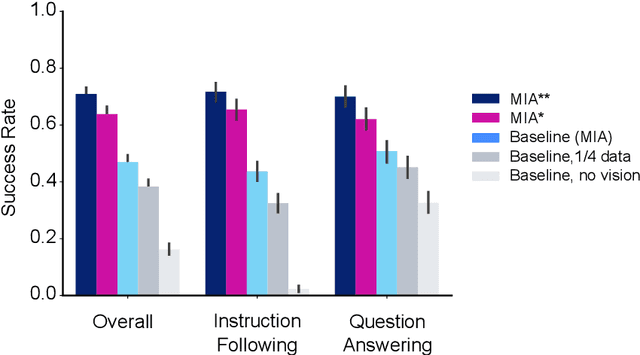
Creating agents that can interact naturally with humans is a common goal in artificial intelligence (AI) research. However, evaluating these interactions is challenging: collecting online human-agent interactions is slow and expensive, yet faster proxy metrics often do not correlate well with interactive evaluation. In this paper, we assess the merits of these existing evaluation metrics and present a novel approach to evaluation called the Standardised Test Suite (STS). The STS uses behavioural scenarios mined from real human interaction data. Agents see replayed scenario context, receive an instruction, and are then given control to complete the interaction offline. These agent continuations are recorded and sent to human annotators to mark as success or failure, and agents are ranked according to the proportion of continuations in which they succeed. The resulting STS is fast, controlled, interpretable, and representative of naturalistic interactions. Altogether, the STS consolidates much of what is desirable across many of our standard evaluation metrics, allowing us to accelerate research progress towards producing agents that can interact naturally with humans. https://youtu.be/YR1TngGORGQ
A data-driven approach for learning to control computers
Feb 16, 2022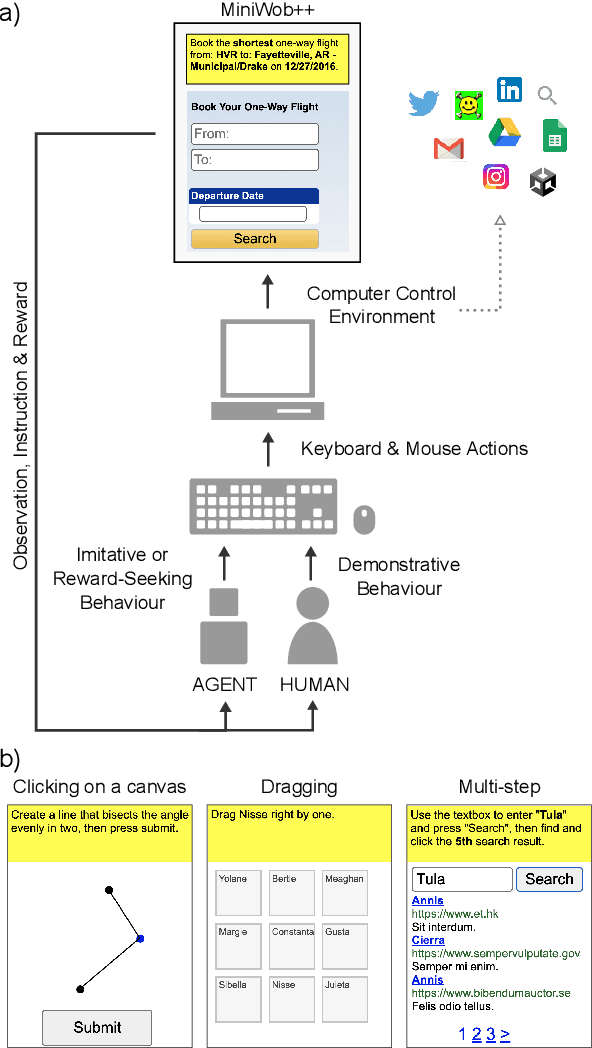
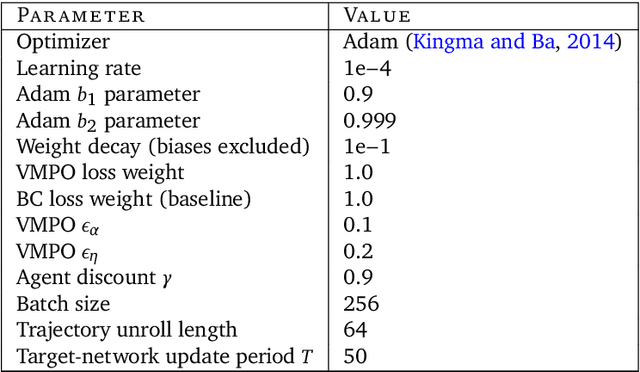
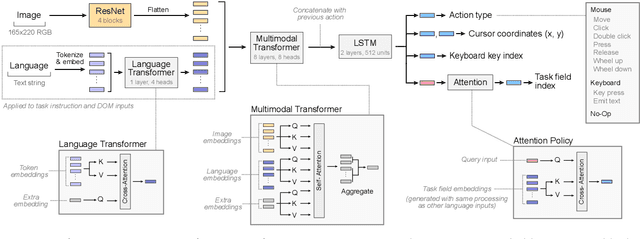
It would be useful for machines to use computers as humans do so that they can aid us in everyday tasks. This is a setting in which there is also the potential to leverage large-scale expert demonstrations and human judgements of interactive behaviour, which are two ingredients that have driven much recent success in AI. Here we investigate the setting of computer control using keyboard and mouse, with goals specified via natural language. Instead of focusing on hand-designed curricula and specialized action spaces, we focus on developing a scalable method centered on reinforcement learning combined with behavioural priors informed by actual human-computer interactions. We achieve state-of-the-art and human-level mean performance across all tasks within the MiniWob++ benchmark, a challenging suite of computer control problems, and find strong evidence of cross-task transfer. These results demonstrate the usefulness of a unified human-agent interface when training machines to use computers. Altogether our results suggest a formula for achieving competency beyond MiniWob++ and towards controlling computers, in general, as a human would.
Creating Multimodal Interactive Agents with Imitation and Self-Supervised Learning
Dec 07, 2021
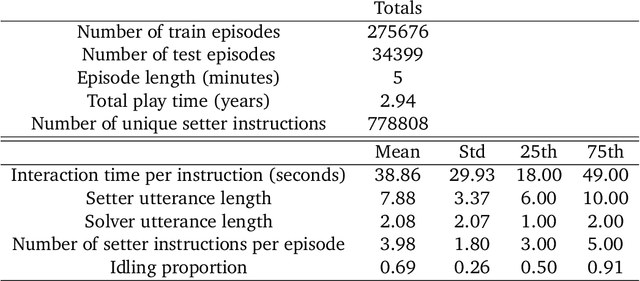
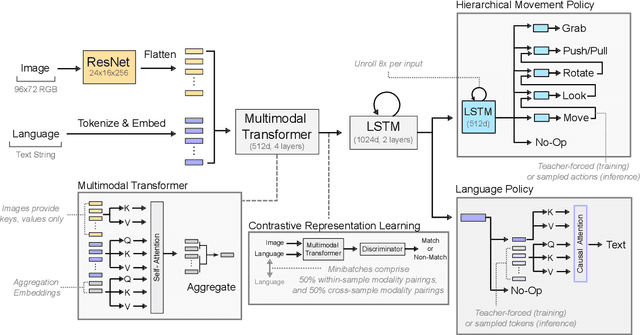
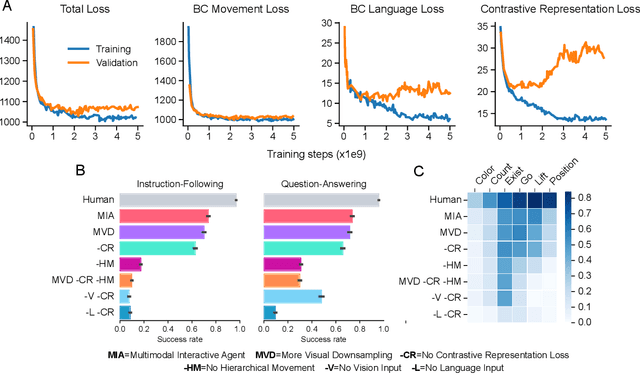
A common vision from science fiction is that robots will one day inhabit our physical spaces, sense the world as we do, assist our physical labours, and communicate with us through natural language. Here we study how to design artificial agents that can interact naturally with humans using the simplification of a virtual environment. We show that imitation learning of human-human interactions in a simulated world, in conjunction with self-supervised learning, is sufficient to produce a multimodal interactive agent, which we call MIA, that successfully interacts with non-adversarial humans 75% of the time. We further identify architectural and algorithmic techniques that improve performance, such as hierarchical action selection. Altogether, our results demonstrate that imitation of multi-modal, real-time human behaviour may provide a straightforward and surprisingly effective means of imbuing agents with a rich behavioural prior from which agents might then be fine-tuned for specific purposes, thus laying a foundation for training capable agents for interactive robots or digital assistants. A video of MIA's behaviour may be found at https://youtu.be/ZFgRhviF7mY
Imitating Interactive Intelligence
Jan 21, 2021
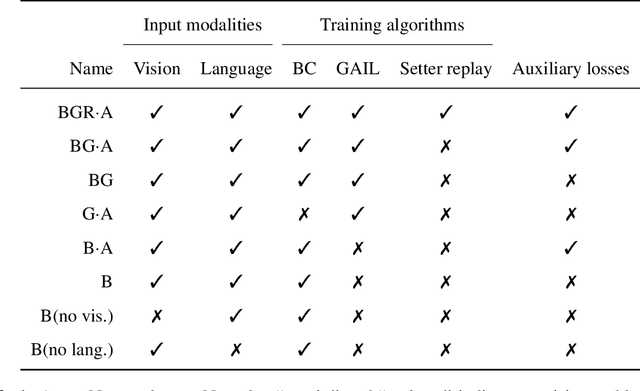
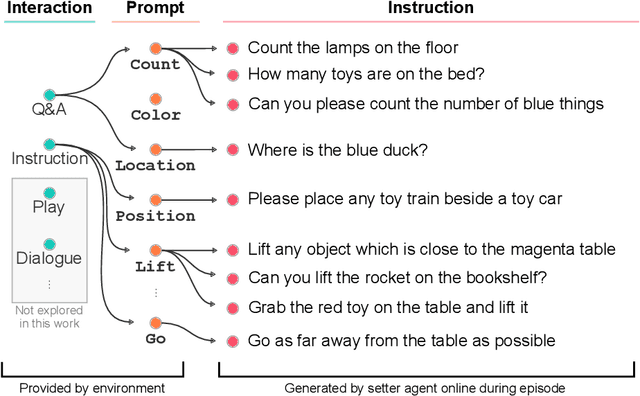
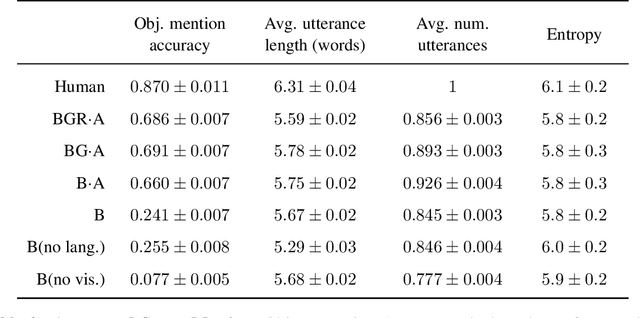
A common vision from science fiction is that robots will one day inhabit our physical spaces, sense the world as we do, assist our physical labours, and communicate with us through natural language. Here we study how to design artificial agents that can interact naturally with humans using the simplification of a virtual environment. This setting nevertheless integrates a number of the central challenges of artificial intelligence (AI) research: complex visual perception and goal-directed physical control, grounded language comprehension and production, and multi-agent social interaction. To build agents that can robustly interact with humans, we would ideally train them while they interact with humans. However, this is presently impractical. Therefore, we approximate the role of the human with another learned agent, and use ideas from inverse reinforcement learning to reduce the disparities between human-human and agent-agent interactive behaviour. Rigorously evaluating our agents poses a great challenge, so we develop a variety of behavioural tests, including evaluation by humans who watch videos of agents or interact directly with them. These evaluations convincingly demonstrate that interactive training and auxiliary losses improve agent behaviour beyond what is achieved by supervised learning of actions alone. Further, we demonstrate that agent capabilities generalise beyond literal experiences in the dataset. Finally, we train evaluation models whose ratings of agents agree well with human judgement, thus permitting the evaluation of new agent models without additional effort. Taken together, our results in this virtual environment provide evidence that large-scale human behavioural imitation is a promising tool to create intelligent, interactive agents, and the challenge of reliably evaluating such agents is possible to surmount.