 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
BOND: Aligning LLMs with Best-of-N Distillation
Jul 19, 2024



Reinforcement learning from human feedback (RLHF) is a key driver of quality and safety in state-of-the-art large language models. Yet, a surprisingly simple and strong inference-time strategy is Best-of-N sampling that selects the best generation among N candidates. In this paper, we propose Best-of-N Distillation (BOND), a novel RLHF algorithm that seeks to emulate Best-of-N but without its significant computational overhead at inference time. Specifically, BOND is a distribution matching algorithm that forces the distribution of generations from the policy to get closer to the Best-of-N distribution. We use the Jeffreys divergence (a linear combination of forward and backward KL) to balance between mode-covering and mode-seeking behavior, and derive an iterative formulation that utilizes a moving anchor for efficiency. We demonstrate the effectiveness of our approach and several design choices through experiments on abstractive summarization and Gemma models. Aligning Gemma policies with BOND outperforms other RLHF algorithms by improving results on several benchmarks.
Offline Regularised Reinforcement Learning for Large Language Models Alignment
May 29, 2024The dominant framework for alignment of large language models (LLM), whether through reinforcement learning from human feedback or direct preference optimisation, is to learn from preference data. This involves building datasets where each element is a quadruplet composed of a prompt, two independent responses (completions of the prompt) and a human preference between the two independent responses, yielding a preferred and a dis-preferred response. Such data is typically scarce and expensive to collect. On the other hand, \emph{single-trajectory} datasets where each element is a triplet composed of a prompt, a response and a human feedback is naturally more abundant. The canonical element of such datasets is for instance an LLM's response to a user's prompt followed by a user's feedback such as a thumbs-up/down. Consequently, in this work, we propose DRO, or \emph{Direct Reward Optimisation}, as a framework and associated algorithms that do not require pairwise preferences. DRO uses a simple mean-squared objective that can be implemented in various ways. We validate our findings empirically, using T5 encoder-decoder language models, and show DRO's performance over selected baselines such as Kahneman-Tversky Optimization (KTO). Thus, we confirm that DRO is a simple and empirically compelling method for single-trajectory policy optimisation.
West-of-N: Synthetic Preference Generation for Improved Reward Modeling
Jan 22, 2024



The success of reinforcement learning from human feedback (RLHF) in language model alignment is strongly dependent on the quality of the underlying reward model. In this paper, we present a novel approach to improve reward model quality by generating synthetic preference data, thereby augmenting the training dataset with on-policy, high-quality preference pairs. Motivated by the promising results of Best-of-N sampling strategies in language model training, we extend their application to reward model training. This results in a self-training strategy to generate preference pairs by selecting the best and worst candidates in a pool of responses to a given query. Empirically, we find that this approach improves the performance of any reward model, with an effect comparable to the addition of a similar quantity of human preference data. This work opens up new avenues of research for improving RLHF for language model alignment, by offering synthetic preference generation as a solution to reward modeling challenges.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Small Language Models Improve Giants by Rewriting Their Outputs
May 22, 2023



Large language models (LLMs) have demonstrated impressive few-shot learning capabilities, but they often underperform compared to fine-tuned models on challenging tasks. Furthermore, their large size and restricted access only through APIs make task-specific fine-tuning impractical. Moreover, LLMs are sensitive to different aspects of prompts (e.g., the selection and order of demonstrations) and can thus require time-consuming prompt engineering. In this light, we propose a method to correct LLM outputs without relying on their weights. First, we generate a pool of candidates by few-shot prompting an LLM. Second, we refine the LLM-generated outputs using a smaller model, the LM-corrector (LMCor), which is trained to rank, combine and rewrite the candidates to produce the final target output. Our experiments demonstrate that even a small LMCor model (250M) substantially improves the few-shot performance of LLMs (62B) across diverse tasks. Moreover, we illustrate that the LMCor exhibits robustness against different prompts, thereby minimizing the need for extensive prompt engineering. Finally, we showcase that the LMCor can be seamlessly integrated with different LLMs at inference time, serving as a plug-and-play module to improve their performance.
Teaching Small Language Models to Reason
Dec 19, 2022



Chain of thought prompting successfully improves the reasoning capabilities of large language models, achieving state of the art results on a range of datasets. However, these reasoning capabilities only appear to emerge in models with a size of over 100 billion parameters. In this paper, we explore the transfer of such reasoning capabilities to models with less than 100 billion parameters via knowledge distillation. Specifically, we finetune a student model on the chain of thought outputs generated by a larger teacher model. Our experiments show that the proposed method improves task performance across arithmetic, commonsense and symbolic reasoning datasets. For example, the accuracy of T5 XXL on GSM8K improves from 8.11% to 21.99% when finetuned on PaLM-540B generated chains of thought.
Text Generation with Text-Editing Models
Jun 14, 2022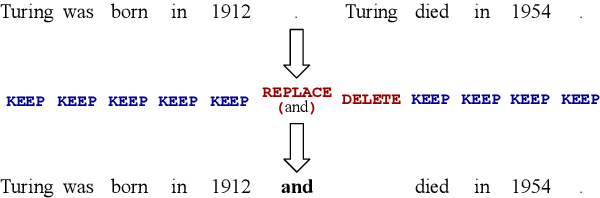

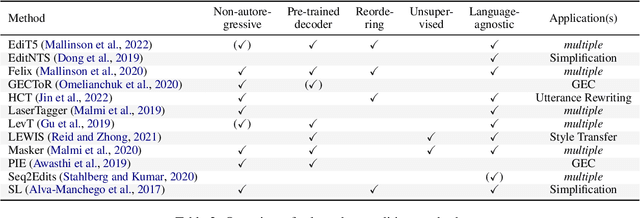
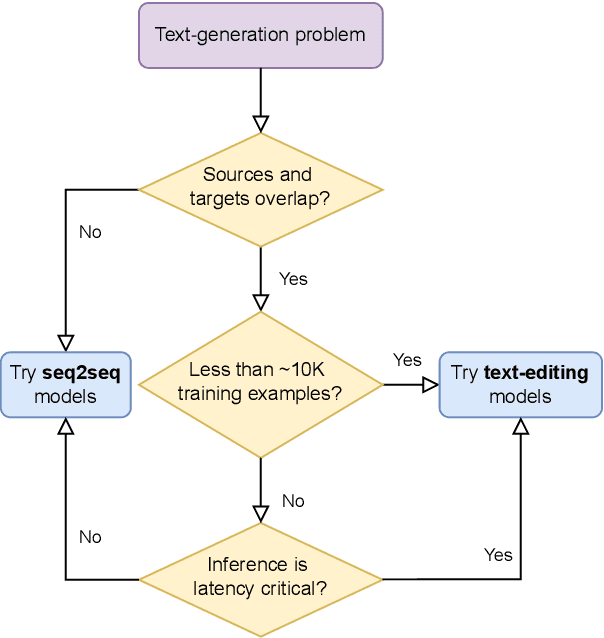
Text-editing models have recently become a prominent alternative to seq2seq models for monolingual text-generation tasks such as grammatical error correction, simplification, and style transfer. These tasks share a common trait - they exhibit a large amount of textual overlap between the source and target texts. Text-editing models take advantage of this observation and learn to generate the output by predicting edit operations applied to the source sequence. In contrast, seq2seq models generate outputs word-by-word from scratch thus making them slow at inference time. Text-editing models provide several benefits over seq2seq models including faster inference speed, higher sample efficiency, and better control and interpretability of the outputs. This tutorial provides a comprehensive overview of text-editing models and current state-of-the-art approaches, and analyzes their pros and cons. We discuss challenges related to productionization and how these models can be used to mitigate hallucination and bias, both pressing challenges in the field of text generation.
EdiT5: Semi-Autoregressive Text-Editing with T5 Warm-Start
May 24, 2022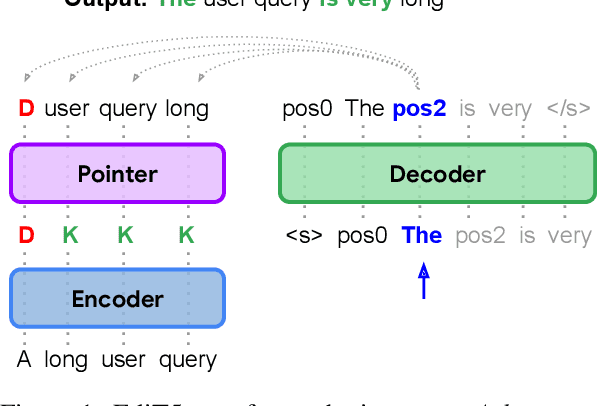

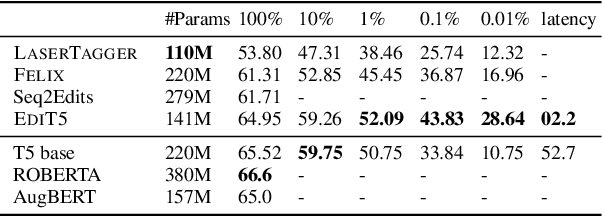
We present EdiT5 - a novel semi-autoregressive text-editing approach designed to combine the strengths of non-autoregressive text-editing and autoregressive decoding. EdiT5 is faster at inference times than conventional sequence-to-sequence (seq2seq) models, while being capable of modeling flexible input-output transformations. This is achieved by decomposing the generation process into three sub-tasks: (1) tagging to decide on the subset of input tokens to be preserved in the output, (2) re-ordering to define their order in the output text, and (3) insertion to infill the missing tokens that are not present in the input. The tagging and re-ordering steps, which are responsible for generating the largest portion of the output, are non-autoregressive, while the insertion uses an autoregressive decoder. Depending on the task, EdiT5 requires significantly fewer autoregressive steps demonstrating speedups of up to 25x when compared to classic seq2seq models. Quality-wise, EdiT5 is initialized with a pre-trained T5 checkpoint yielding comparable performance to T5 in high-resource settings and clearly outperforms it on low-resource settings when evaluated on three NLG tasks: Sentence Fusion, Grammatical Error Correction, and Decontextualization.
Controlled Text Generation as Continuous Optimization with Multiple Constraints
Aug 04, 2021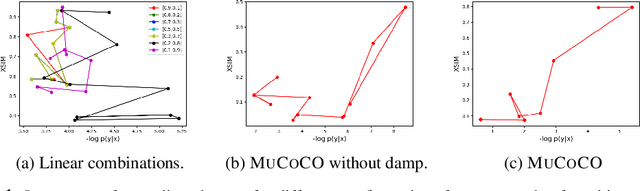
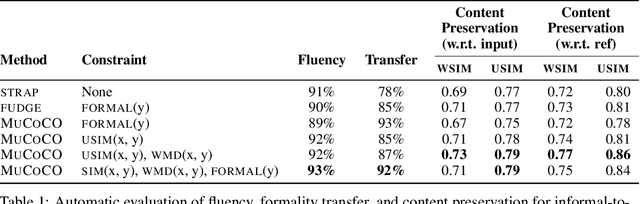
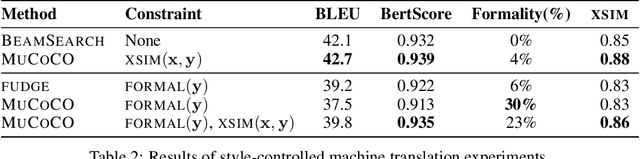
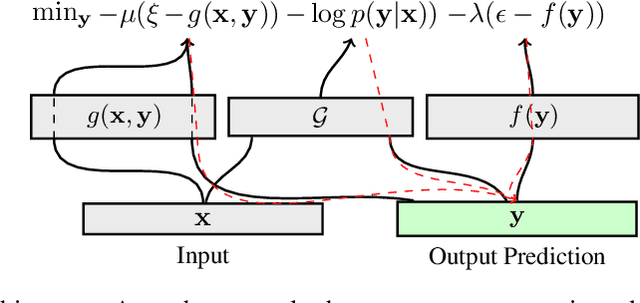
As large-scale language model pretraining pushes the state-of-the-art in text generation, recent work has turned to controlling attributes of the text such models generate. While modifying the pretrained models via fine-tuning remains the popular approach, it incurs a significant computational cost and can be infeasible due to lack of appropriate data. As an alternative, we propose MuCoCO -- a flexible and modular algorithm for controllable inference from pretrained models. We formulate the decoding process as an optimization problem which allows for multiple attributes we aim to control to be easily incorporated as differentiable constraints to the optimization. By relaxing this discrete optimization to a continuous one, we make use of Lagrangian multipliers and gradient-descent based techniques to generate the desired text. We evaluate our approach on controllable machine translation and style transfer with multiple sentence-level attributes and observe significant improvements over baselines.