 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Evaluating Emerging Cyberattack Capabilities of AI
Mar 14, 2025As frontier models become more capable, the community has attempted to evaluate their ability to enable cyberattacks. Performing a comprehensive evaluation and prioritizing defenses are crucial tasks in preparing for AGI safely. However, current cyber evaluation efforts are ad-hoc, with no systematic reasoning about the various phases of attacks, and do not provide a steer on how to use targeted defenses. In this work, we propose a novel approach to AI cyber capability evaluation that (1) examines the end-to-end attack chain, (2) helps to identify gaps in the evaluation of AI threats, and (3) helps defenders prioritize targeted mitigations and conduct AI-enabled adversary emulation to support red teaming. To achieve these goals, we propose adapting existing cyberattack chain frameworks to AI systems. We analyze over 12,000 instances of real-world attempts to use AI in cyberattacks catalogued by Google's Threat Intelligence Group. Using this analysis, we curate a representative collection of seven cyberattack chain archetypes and conduct a bottleneck analysis to identify areas of potential AI-driven cost disruption. Our evaluation benchmark consists of 50 new challenges spanning different phases of cyberattacks. Based on this, we devise targeted cybersecurity model evaluations, report on the potential for AI to amplify offensive cyber capabilities across specific attack phases, and conclude with recommendations on prioritizing defenses. In all, we consider this to be the most comprehensive AI cyber risk evaluation framework published so far.
STAR: SocioTechnical Approach to Red Teaming Language Models
Jun 17, 2024This research introduces STAR, a sociotechnical framework that improves on current best practices for red teaming safety of large language models. STAR makes two key contributions: it enhances steerability by generating parameterised instructions for human red teamers, leading to improved coverage of the risk surface. Parameterised instructions also provide more detailed insights into model failures at no increased cost. Second, STAR improves signal quality by matching demographics to assess harms for specific groups, resulting in more sensitive annotations. STAR further employs a novel step of arbitration to leverage diverse viewpoints and improve label reliability, treating disagreement not as noise but as a valuable contribution to signal quality.
Holistic Safety and Responsibility Evaluations of Advanced AI Models
Apr 22, 2024Safety and responsibility evaluations of advanced AI models are a critical but developing field of research and practice. In the development of Google DeepMind's advanced AI models, we innovated on and applied a broad set of approaches to safety evaluation. In this report, we summarise and share elements of our evolving approach as well as lessons learned for a broad audience. Key lessons learned include: First, theoretical underpinnings and frameworks are invaluable to organise the breadth of risk domains, modalities, forms, metrics, and goals. Second, theory and practice of safety evaluation development each benefit from collaboration to clarify goals, methods and challenges, and facilitate the transfer of insights between different stakeholders and disciplines. Third, similar key methods, lessons, and institutions apply across the range of concerns in responsibility and safety - including established and emerging harms. For this reason it is important that a wide range of actors working on safety evaluation and safety research communities work together to develop, refine and implement novel evaluation approaches and best practices, rather than operating in silos. The report concludes with outlining the clear need to rapidly advance the science of evaluations, to integrate new evaluations into the development and governance of AI, to establish scientifically-grounded norms and standards, and to promote a robust evaluation ecosystem.
Responsible Reporting for Frontier AI Development
Apr 03, 2024



Mitigating the risks from frontier AI systems requires up-to-date and reliable information about those systems. Organizations that develop and deploy frontier systems have significant access to such information. By reporting safety-critical information to actors in government, industry, and civil society, these organizations could improve visibility into new and emerging risks posed by frontier systems. Equipped with this information, developers could make better informed decisions on risk management, while policymakers could design more targeted and robust regulatory infrastructure. We outline the key features of responsible reporting and propose mechanisms for implementing them in practice.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Adversarial Machine Learning and Cybersecurity: Risks, Challenges, and Legal Implications
May 23, 2023In July 2022, the Center for Security and Emerging Technology (CSET) at Georgetown University and the Program on Geopolitics, Technology, and Governance at the Stanford Cyber Policy Center convened a workshop of experts to examine the relationship between vulnerabilities in artificial intelligence systems and more traditional types of software vulnerabilities. Topics discussed included the extent to which AI vulnerabilities can be handled under standard cybersecurity processes, the barriers currently preventing the accurate sharing of information about AI vulnerabilities, legal issues associated with adversarial attacks on AI systems, and potential areas where government support could improve AI vulnerability management and mitigation. This report is meant to accomplish two things. First, it provides a high-level discussion of AI vulnerabilities, including the ways in which they are disanalogous to other types of vulnerabilities, and the current state of affairs regarding information sharing and legal oversight of AI vulnerabilities. Second, it attempts to articulate broad recommendations as endorsed by the majority of participants at the workshop.
Adversarial Attack Attribution: Discovering Attributable Signals in Adversarial ML Attacks
Jan 08, 2021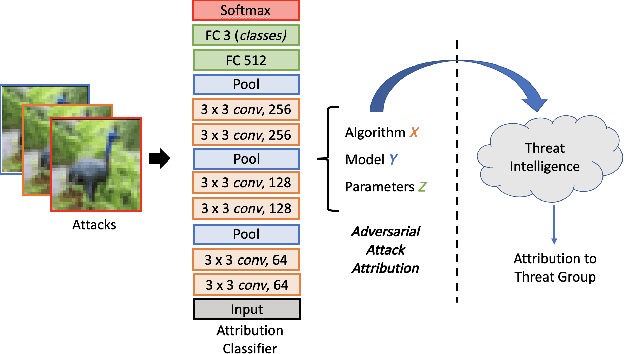

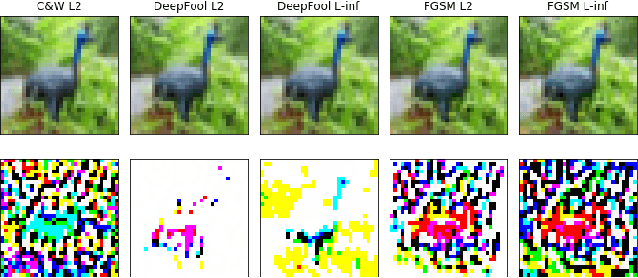
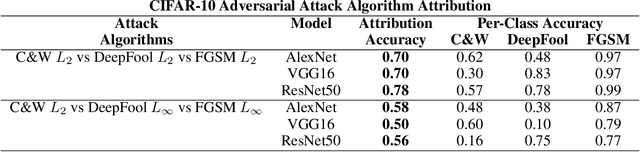
Machine Learning (ML) models are known to be vulnerable to adversarial inputs and researchers have demonstrated that even production systems, such as self-driving cars and ML-as-a-service offerings, are susceptible. These systems represent a target for bad actors. Their disruption can cause real physical and economic harm. When attacks on production ML systems occur, the ability to attribute the attack to the responsible threat group is a critical step in formulating a response and holding the attackers accountable. We pose the following question: can adversarially perturbed inputs be attributed to the particular methods used to generate the attack? In other words, is there a way to find a signal in these attacks that exposes the attack algorithm, model architecture, or hyperparameters used in the attack? We introduce the concept of adversarial attack attribution and create a simple supervised learning experimental framework to examine the feasibility of discovering attributable signals in adversarial attacks. We find that it is possible to differentiate attacks generated with different attack algorithms, models, and hyperparameters on both the CIFAR-10 and MNIST datasets.
Learning a Predictable and Generative Vector Representation for Objects
Aug 31, 2016
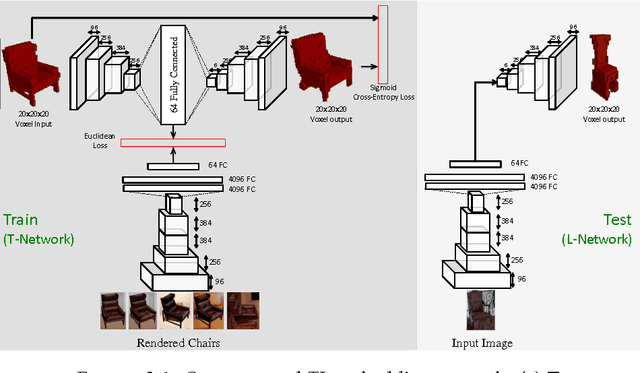


What is a good vector representation of an object? We believe that it should be generative in 3D, in the sense that it can produce new 3D objects; as well as be predictable from 2D, in the sense that it can be perceived from 2D images. We propose a novel architecture, called the TL-embedding network, to learn an embedding space with these properties. The network consists of two components: (a) an autoencoder that ensures the representation is generative; and (b) a convolutional network that ensures the representation is predictable. This enables tackling a number of tasks including voxel prediction from 2D images and 3D model retrieval. Extensive experimental analysis demonstrates the usefulness and versatility of this embedding.