 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Reasoning Behind Next Occupation Recommendation
Apr 23, 2026In this work, we develop a novel reasoning approach to enhance the performance of large language models (LLMs) in future occupation prediction. In this approach, a reason generator first derives a ``reason'' for a user using his/her past education and career history. The reason summarizes the user's preference and is used as the input of an occupation predictor to recommend the user's next occupation. This two-step occupation prediction approach is, however, non-trivial as LLMs are not aligned with career paths or the unobserved reasons behind each occupation decision. We therefore propose to fine-tune LLMs improving their reasoning and occupation prediction performance. We first derive high-quality oracle reasons, as measured by factuality, coherence and utility criteria, using a LLM-as-a-Judge. These oracle reasons are then used to fine-tune small LLMs to perform reason generation and next occupation prediction. Our extensive experiments show that: (a) our approach effectively enhances LLM's accuracy in next occupation prediction making them comparable to fully supervised methods and outperforming unsupervised methods; (b) a single LLM fine-tuned to perform reason generation and occupation prediction outperforms two LLMs fine-tuned to perform the tasks separately; and (c) the next occupation prediction accuracy depends on the quality of generated reasons. Our code is available at https://github.com/Sarasarahhhhh/job_prediction.
DialToM: A Theory of Mind Benchmark for Forecasting State-Driven Dialogue Trajectories
Apr 22, 2026Large Language Models (LLMs) have been shown to possess Theory of Mind (ToM) abilities. However, it remains unclear whether this stems from robust reasoning or spurious correlations. We introduce DialToM, a human-verified benchmark built from natural human dialogue using a multiple-choice framework. We evaluate not only mental state prediction (Literal ToM) but also the functional utility of these states (Functional ToM) through Prospective Diagnostic Forecasting -- probing whether models can identify state-consistent dialogue trajectories solely from mental-state profiles. Our results reveal a significant reasoning asymmetry: while LLMs excel at identifying mental states, most (except for Gemini 3 Pro) fail to leverage this understanding to forecast social trajectories. Additionally, we find only weak semantic similarities between human and LLM-generated inferences. To facilitate reproducibility, the DialToM dataset and evaluation code are publicly available at https://github.com/Stealth-py/DialToM.
MHSafeEval: Role-Aware Interaction-Level Evaluation of Mental Health Safety in Large Language Models
Apr 20, 2026Large language models (LLMs) are increasingly explored as scalable tools for mental health counseling, yet evaluating their safety remains challenging due to the interactional and context-dependent nature of clinical harm. Existing evaluation frameworks predominantly assess isolated responses using coarse-grained taxonomies or static datasets, limiting their ability to diagnose how harms emerge and accumulate over multi-turn counseling interactions. In this work, we introduce R-MHSafe, a role-aware mental health safety taxonomy that characterizes clinically significant harm in terms of the interactional roles an AI counselor adopts, including perpetrator, instigator, facilitator, or enabler, combined with clinically grounded harm categories. Then, we propose MHSafeEval, a closed-loop, agent-based evaluation framework that formulates safety assessment as trajectory-level discovery of harm through adversarial multi-turn interactions, guided by role-aware modeling. Using R-MHSafe and MHSafeEval, we conduct a large-scale evaluation across state-of-the-art LLMs. Our results reveal substantial role-dependent and cumulative safety failures that are systematically missed by existing static benchmarks, and show that our framework significantly improves failure-mode coverage and diagnostic granularity.
Towards Unbiased Cross-Modal Representation Learning for Food Image-to-Recipe Retrieval
Nov 19, 2025This paper addresses the challenges of learning representations for recipes and food images in the cross-modal retrieval problem. As the relationship between a recipe and its cooked dish is cause-and-effect, treating a recipe as a text source describing the visual appearance of a dish for learning representation, as the existing approaches, will create bias misleading image-and-recipe similarity judgment. Specifically, a food image may not equally capture every detail in a recipe, due to factors such as the cooking process, dish presentation, and image-capturing conditions. The current representation learning tends to capture dominant visual-text alignment while overlooking subtle variations that determine retrieval relevance. In this paper, we model such bias in cross-modal representation learning using causal theory. The causal view of this problem suggests ingredients as one of the confounder sources and a simple backdoor adjustment can alleviate the bias. By causal intervention, we reformulate the conventional model for food-to-recipe retrieval with an additional term to remove the potential bias in similarity judgment. Based on this theory-informed formulation, we empirically prove the oracle performance of retrieval on the Recipe1M dataset to be MedR=1 across the testing data sizes of 1K, 10K, and even 50K. We also propose a plug-and-play neural module, which is essentially a multi-label ingredient classifier for debiasing. New state-of-the-art search performances are reported on the Recipe1M dataset.
Leveraging Large Language Models for Career Mobility Analysis: A Study of Gender, Race, and Job Change Using U.S. Online Resume Profiles
Nov 15, 2025
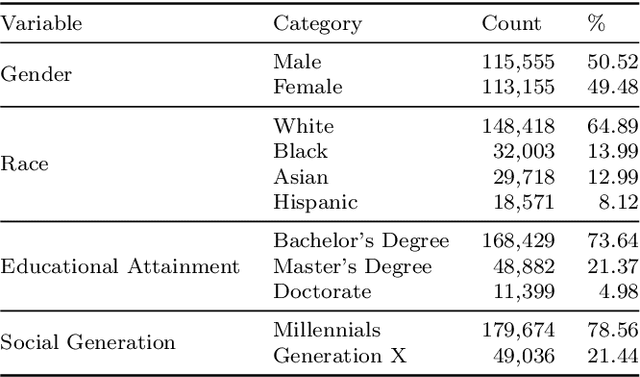


We present a large-scale analysis of career mobility of college-educated U.S. workers using online resume profiles to investigate how gender, race, and job change options are associated with upward mobility. This study addresses key research questions of how the job changes affect their upward career mobility, and how the outcomes of upward career mobility differ by gender and race. We address data challenges -- such as missing demographic attributes, missing wage data, and noisy occupation labels -- through various data processing and Artificial Intelligence (AI) methods. In particular, we develop a large language models (LLMs) based occupation classification method known as FewSOC that achieves accuracy significantly higher than the original occupation labels in the resume dataset. Analysis of 228,710 career trajectories reveals that intra-firm occupation change has been found to facilitate upward mobility most strongly, followed by inter-firm occupation change and inter-firm lateral move. Women and Black college graduates experience significantly lower returns from job changes than men and White peers. Multilevel sensitivity analyses confirm that these disparities are robust to cluster-level heterogeneity and reveal additional intersectional patterns.
Towards Provably Unlearnable Examples via Bayes Error Optimisation
Nov 11, 2025



The recent success of machine learning models, especially large-scale classifiers and language models, relies heavily on training with massive data. These data are often collected from online sources. This raises serious concerns about the protection of user data, as individuals may not have given consent for their data to be used in training. To address this concern, recent studies introduce the concept of unlearnable examples, i.e., data instances that appear natural but are intentionally altered to prevent models from effectively learning from them. While existing methods demonstrate empirical effectiveness, they typically rely on heuristic trials and lack formal guarantees. Besides, when unlearnable examples are mixed with clean data, as is often the case in practice, their unlearnability disappears. In this work, we propose a novel approach to constructing unlearnable examples by systematically maximising the Bayes error, a measurement of irreducible classification error. We develop an optimisation-based approach and provide an efficient solution using projected gradient ascent. Our method provably increases the Bayes error and remains effective when the unlearning examples are mixed with clean samples. Experimental results across multiple datasets and model architectures are consistent with our theoretical analysis and show that our approach can restrict data learnability, effectively in practice.
Mitigating Cross-modal Representation Bias for Multicultural Image-to-Recipe Retrieval
Oct 23, 2025Existing approaches for image-to-recipe retrieval have the implicit assumption that a food image can fully capture the details textually documented in its recipe. However, a food image only reflects the visual outcome of a cooked dish and not the underlying cooking process. Consequently, learning cross-modal representations to bridge the modality gap between images and recipes tends to ignore subtle, recipe-specific details that are not visually apparent but are crucial for recipe retrieval. Specifically, the representations are biased to capture the dominant visual elements, resulting in difficulty in ranking similar recipes with subtle differences in use of ingredients and cooking methods. The bias in representation learning is expected to be more severe when the training data is mixed of images and recipes sourced from different cuisines. This paper proposes a novel causal approach that predicts the culinary elements potentially overlooked in images, while explicitly injecting these elements into cross-modal representation learning to mitigate biases. Experiments are conducted on the standard monolingual Recipe1M dataset and a newly curated multilingual multicultural cuisine dataset. The results indicate that the proposed causal representation learning is capable of uncovering subtle ingredients and cooking actions and achieves impressive retrieval performance on both monolingual and multilingual multicultural datasets.
Effects of Theory of Mind and Prosocial Beliefs on Steering Human-Aligned Behaviors of LLMs in Ultimatum Games
May 30, 2025Large Language Models (LLMs) have shown potential in simulating human behaviors and performing theory-of-mind (ToM) reasoning, a crucial skill for complex social interactions. In this study, we investigate the role of ToM reasoning in aligning agentic behaviors with human norms in negotiation tasks, using the ultimatum game as a controlled environment. We initialized LLM agents with different prosocial beliefs (including Greedy, Fair, and Selfless) and reasoning methods like chain-of-thought (CoT) and varying ToM levels, and examined their decision-making processes across diverse LLMs, including reasoning models like o3-mini and DeepSeek-R1 Distilled Qwen 32B. Results from 2,700 simulations indicated that ToM reasoning enhances behavior alignment, decision-making consistency, and negotiation outcomes. Consistent with previous findings, reasoning models exhibit limited capability compared to models with ToM reasoning, different roles of the game benefits with different orders of ToM reasoning. Our findings contribute to the understanding of ToM's role in enhancing human-AI interaction and cooperative decision-making. The code used for our experiments can be found at https://github.com/Stealth-py/UltimatumToM.
Advancing Food Nutrition Estimation via Visual-Ingredient Feature Fusion
May 13, 2025Nutrition estimation is an important component of promoting healthy eating and mitigating diet-related health risks. Despite advances in tasks such as food classification and ingredient recognition, progress in nutrition estimation is limited due to the lack of datasets with nutritional annotations. To address this issue, we introduce FastFood, a dataset with 84,446 images across 908 fast food categories, featuring ingredient and nutritional annotations. In addition, we propose a new model-agnostic Visual-Ingredient Feature Fusion (VIF$^2$) method to enhance nutrition estimation by integrating visual and ingredient features. Ingredient robustness is improved through synonym replacement and resampling strategies during training. The ingredient-aware visual feature fusion module combines ingredient features and visual representation to achieve accurate nutritional prediction. During testing, ingredient predictions are refined using large multimodal models by data augmentation and majority voting. Our experiments on both FastFood and Nutrition5k datasets validate the effectiveness of our proposed method built in different backbones (e.g., Resnet, InceptionV3 and ViT), which demonstrates the importance of ingredient information in nutrition estimation. https://huiyanqi.github.io/fastfood-nutrition-estimation/.
A Multi-Stage Framework with Taxonomy-Guided Reasoning for Occupation Classification Using Large Language Models
Mar 17, 2025Automatically annotating job data with standardized occupations from taxonomies, known as occupation classification, is crucial for labor market analysis. However, this task is often hindered by data scarcity and the challenges of manual annotations. While large language models (LLMs) hold promise due to their extensive world knowledge and in-context learning capabilities, their effectiveness depends on their knowledge of occupational taxonomies, which remains unclear. In this study, we assess the ability of LLMs to generate precise taxonomic entities from taxonomy, highlighting their limitations. To address these challenges, we propose a multi-stage framework consisting of inference, retrieval, and reranking stages, which integrates taxonomy-guided reasoning examples to enhance performance by aligning outputs with taxonomic knowledge. Evaluations on a large-scale dataset show significant improvements in classification accuracy. Furthermore, we demonstrate the framework's adaptability for multi-label skill classification. Our results indicate that the framework outperforms existing LLM-based methods, offering a practical and scalable solution for occupation classification and related tasks across LLMs.