 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Perception Inspired Representation Learning for Trustworthy Image Quality Assessment
Apr 30, 2024



Despite great success in modeling visual perception, deep neural network based image quality assessment (IQA) still remains unreliable in real-world applications due to its vulnerability to adversarial perturbations and the inexplicit black-box structure. In this paper, we propose to build a trustworthy IQA model via Causal Perception inspired Representation Learning (CPRL), and a score reflection attack method for IQA model. More specifically, we assume that each image is composed of Causal Perception Representation (CPR) and non-causal perception representation (N-CPR). CPR serves as the causation of the subjective quality label, which is invariant to the imperceptible adversarial perturbations. Inversely, N-CPR presents spurious associations with the subjective quality label, which may significantly change with the adversarial perturbations. To extract the CPR from each input image, we develop a soft ranking based channel-wise activation function to mediate the causally sufficient (beneficial for high prediction accuracy) and necessary (beneficial for high robustness) deep features, and based on intervention employ minimax game to optimize. Experiments on four benchmark databases show that the proposed CPRL method outperforms many state-of-the-art adversarial defense methods and provides explicit model interpretation.
Beyond MOS: Subjective Image Quality Score Preprocessing Method Based on Perceptual Similarity
Apr 30, 2024



Image quality assessment often relies on raw opinion scores provided by subjects in subjective experiments, which can be noisy and unreliable. To address this issue, postprocessing procedures such as ITU-R BT.500, ITU-T P.910, and ITU-T P.913 have been standardized to clean up the original opinion scores. These methods use annotator-based statistical priors, but they do not take into account extensive information about the image itself, which limits their performance in less annotated scenarios. Generally speaking, image quality datasets usually contain similar scenes or distortions, and it is inevitable for subjects to compare images to score a reasonable score when scoring. Therefore, In this paper, we proposed Subjective Image Quality Score Preprocessing Method perceptual similarity Subjective Preprocessing (PSP), which exploit the perceptual similarity between images to alleviate subjective bias in less annotated scenarios. Specifically, we model subjective scoring as a conditional probability model based on perceptual similarity with previously scored images, called subconscious reference scoring. The reference images are stored by a neighbor dictionary, which is obtained by a normalized vector dot-product based nearest neighbor search of the images' perceptual depth features. Then the preprocessed score is updated by the exponential moving average (EMA) of the subconscious reference scoring, called similarity regularized EMA. Our experiments on multiple datasets (LIVE, TID2013, CID2013) show that this method can effectively remove the bias of the subjective scores. Additionally, Experiments prove that the Preprocesed dataset can improve the performance of downstream IQA tasks very well.
Perceptual Constancy Constrained Single Opinion Score Calibration for Image Quality Assessment
Apr 30, 2024



In this paper, we propose a highly efficient method to estimate an image's mean opinion score (MOS) from a single opinion score (SOS). Assuming that each SOS is the observed sample of a normal distribution and the MOS is its unknown expectation, the MOS inference is formulated as a maximum likelihood estimation problem, where the perceptual correlation of pairwise images is considered in modeling the likelihood of SOS. More specifically, by means of the quality-aware representations learned from the self-supervised backbone, we introduce a learnable relative quality measure to predict the MOS difference between two images. Then, the current image's maximum likelihood estimation towards MOS is represented by the sum of another reference image's estimated MOS and their relative quality. Ideally, no matter which image is selected as the reference, the MOS of the current image should remain unchanged, which is termed perceptual cons tancy constrained calibration (PC3). Finally, we alternatively optimize the relative quality measure's parameter and the current image's estimated MOS via backpropagation and Newton's method respectively. Experiments show that the proposed method is efficient in calibrating the biased SOS and significantly improves IQA model learning when only SOSs are available.
Learning with Noisy Low-Cost MOS for Image Quality Assessment via Dual-Bias Calibration
Nov 27, 2023



Learning based image quality assessment (IQA) models have obtained impressive performance with the help of reliable subjective quality labels, where mean opinion score (MOS) is the most popular choice. However, in view of the subjective bias of individual annotators, the labor-abundant MOS (LA-MOS) typically requires a large collection of opinion scores from multiple annotators for each image, which significantly increases the learning cost. In this paper, we aim to learn robust IQA models from low-cost MOS (LC-MOS), which only requires very few opinion scores or even a single opinion score for each image. More specifically, we consider the LC-MOS as the noisy observation of LA-MOS and enforce the IQA model learned from LC-MOS to approach the unbiased estimation of LA-MOS. In this way, we represent the subjective bias between LC-MOS and LA-MOS, and the model bias between IQA predictions learned from LC-MOS and LA-MOS (i.e., dual-bias) as two latent variables with unknown parameters. By means of the expectation-maximization based alternating optimization, we can jointly estimate the parameters of the dual-bias, which suppresses the misleading of LC-MOS via a gated dual-bias calibration (GDBC) module. To the best of our knowledge, this is the first exploration of robust IQA model learning from noisy low-cost labels. Theoretical analysis and extensive experiments on four popular IQA datasets show that the proposed method is robust toward different bias rates and annotation numbers and significantly outperforms the other learning based IQA models when only LC-MOS is available. Furthermore, we also achieve comparable performance with respect to the other models learned with LA-MOS.
Language bias in Visual Question Answering: A Survey and Taxonomy
Nov 16, 2021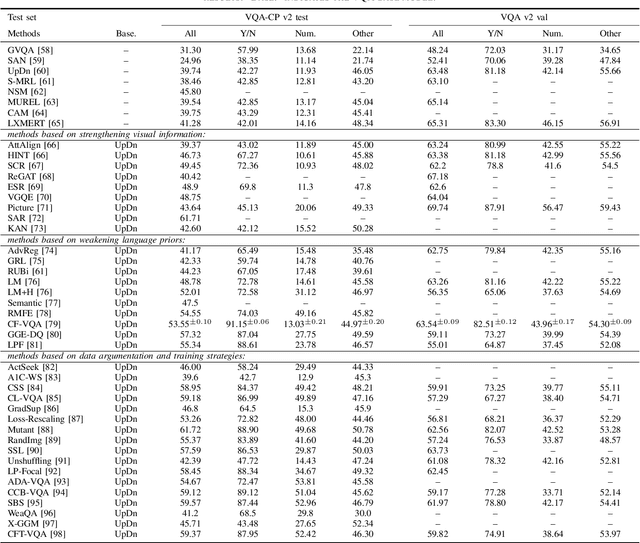
Visual question answering (VQA) is a challenging task, which has attracted more and more attention in the field of computer vision and natural language processing. However, the current visual question answering has the problem of language bias, which reduces the robustness of the model and has an adverse impact on the practical application of visual question answering. In this paper, we conduct a comprehensive review and analysis of this field for the first time, and classify the existing methods according to three categories, including enhancing visual information, weakening language priors, data enhancement and training strategies. At the same time, the relevant representative methods are introduced, summarized and analyzed in turn. The causes of language bias are revealed and classified. Secondly, this paper introduces the datasets mainly used for testing, and reports the experimental results of various existing methods. Finally, we discuss the possible future research directions in this field.