 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Autonomous Mathematics Research
Feb 12, 2026Recent advances in foundational models have yielded reasoning systems capable of achieving a gold-medal standard at the International Mathematical Olympiad. The transition from competition-level problem-solving to professional research, however, requires navigating vast literature and constructing long-horizon proofs. In this work, we introduce Aletheia, a math research agent that iteratively generates, verifies, and revises solutions end-to-end in natural language. Specifically, Aletheia is powered by an advanced version of Gemini Deep Think for challenging reasoning problems, a novel inference-time scaling law that extends beyond Olympiad-level problems, and intensive tool use to navigate the complexities of mathematical research. We demonstrate the capability of Aletheia from Olympiad problems to PhD-level exercises and most notably, through several distinct milestones in AI-assisted mathematics research: (a) a research paper (Feng26) generated by AI without any human intervention in calculating certain structure constants in arithmetic geometry called eigenweights; (b) a research paper (LeeSeo26) demonstrating human-AI collaboration in proving bounds on systems of interacting particles called independent sets; and (c) an extensive semi-autonomous evaluation (Feng et al., 2026a) of 700 open problems on Bloom's Erdos Conjectures database, including autonomous solutions to four open questions. In order to help the public better understand the developments pertaining to AI and mathematics, we suggest quantifying standard levels of autonomy and novelty of AI-assisted results, as well as propose a novel concept of human-AI interaction cards for transparency. We conclude with reflections on human-AI collaboration in mathematics and share all prompts as well as model outputs at https://github.com/google-deepmind/superhuman/tree/main/aletheia.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Controlled Decoding from Language Models
Oct 25, 2023



We propose controlled decoding (CD), a novel off-policy reinforcement learning method to control the autoregressive generation from language models towards high reward outcomes. CD solves an off-policy reinforcement learning problem through a value function for the reward, which we call a prefix scorer. The prefix scorer is used at inference time to steer the generation towards higher reward outcomes. We show that the prefix scorer may be trained on (possibly) off-policy data to predict the expected reward when decoding is continued from a partially decoded response. We empirically demonstrate that CD is effective as a control mechanism on Reddit conversations corpus. We also show that the modularity of the design of CD makes it possible to control for multiple rewards, effectively solving a multi-objective reinforcement learning problem with no additional complexity. Finally, we show that CD can be applied in a novel blockwise fashion at inference-time, again without the need for any training-time changes, essentially bridging the gap between the popular best-of-$K$ strategy and token-level reinforcement learning. This makes CD a promising approach for alignment of language models.
PaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.
HyperPrompt: Prompt-based Task-Conditioning of Transformers
Mar 01, 2022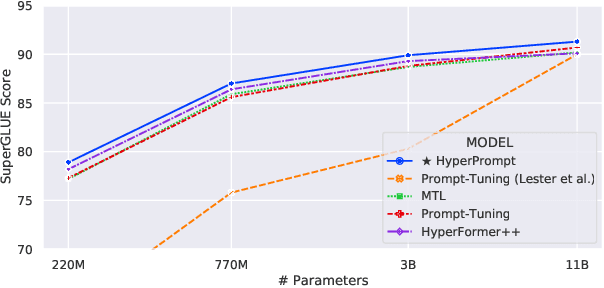

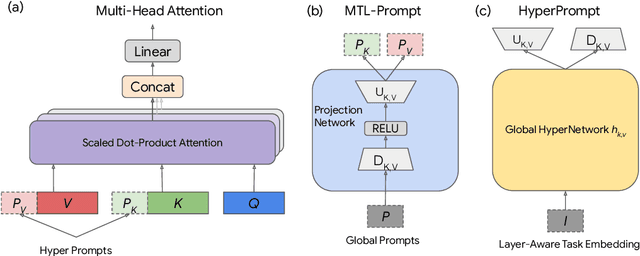
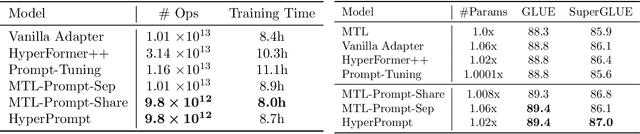
Prompt-Tuning is a new paradigm for finetuning pre-trained language models in a parameter-efficient way. Here, we explore the use of HyperNetworks to generate hyper-prompts: we propose HyperPrompt, a novel architecture for prompt-based task-conditioning of self-attention in Transformers. The hyper-prompts are end-to-end learnable via generation by a HyperNetwork. HyperPrompt allows the network to learn task-specific feature maps where the hyper-prompts serve as task global memories for the queries to attend to, at the same time enabling flexible information sharing among tasks. We show that HyperPrompt is competitive against strong multi-task learning baselines with as few as $0.14\%$ of additional task-conditioning parameters, achieving great parameter and computational efficiency. Through extensive empirical experiments, we demonstrate that HyperPrompt can achieve superior performances over strong T5 multi-task learning baselines and parameter-efficient adapter variants including Prompt-Tuning and HyperFormer++ on Natural Language Understanding benchmarks of GLUE and SuperGLUE across many model sizes.
LaMDA: Language Models for Dialog Applications
Feb 10, 2022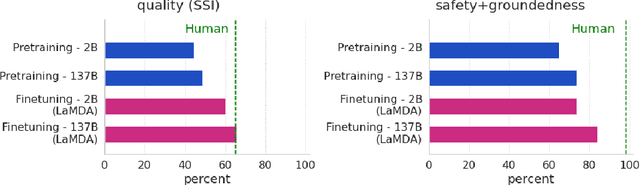
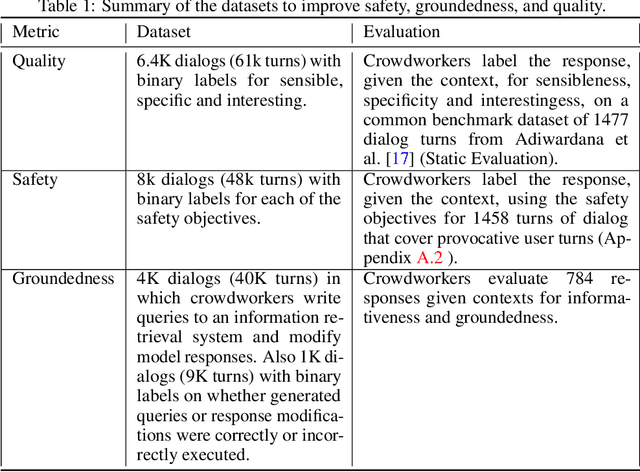
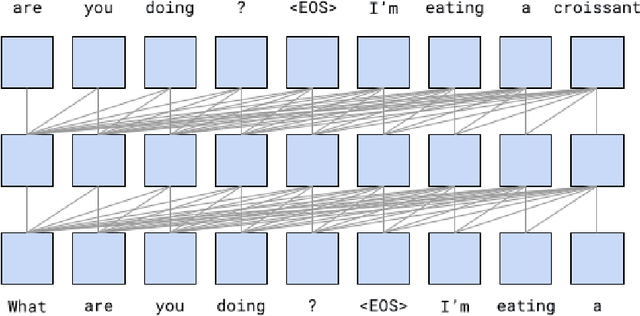

We present LaMDA: Language Models for Dialog Applications. LaMDA is a family of Transformer-based neural language models specialized for dialog, which have up to 137B parameters and are pre-trained on 1.56T words of public dialog data and web text. While model scaling alone can improve quality, it shows less improvements on safety and factual grounding. We demonstrate that fine-tuning with annotated data and enabling the model to consult external knowledge sources can lead to significant improvements towards the two key challenges of safety and factual grounding. The first challenge, safety, involves ensuring that the model's responses are consistent with a set of human values, such as preventing harmful suggestions and unfair bias. We quantify safety using a metric based on an illustrative set of human values, and we find that filtering candidate responses using a LaMDA classifier fine-tuned with a small amount of crowdworker-annotated data offers a promising approach to improving model safety. The second challenge, factual grounding, involves enabling the model to consult external knowledge sources, such as an information retrieval system, a language translator, and a calculator. We quantify factuality using a groundedness metric, and we find that our approach enables the model to generate responses grounded in known sources, rather than responses that merely sound plausible. Finally, we explore the use of LaMDA in the domains of education and content recommendations, and analyze their helpfulness and role consistency.