 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining LLMs for Honesty via Confessions
Dec 22, 2025



Large language models (LLMs) can be dishonest when reporting on their actions and beliefs -- for example, they may overstate their confidence in factual claims or cover up evidence of covert actions. Such dishonesty may arise due to the effects of reinforcement learning (RL), where challenges with reward shaping can result in a training process that inadvertently incentivizes the model to lie or misrepresent its actions. In this work we propose a method for eliciting an honest expression of an LLM's shortcomings via a self-reported *confession*. A confession is an output, provided upon request after a model's original answer, that is meant to serve as a full account of the model's compliance with the letter and spirit of its policies and instructions. The reward assigned to a confession during training is solely based on its honesty, and does not impact positively or negatively the main answer's reward. As long as the "path of least resistance" for maximizing confession reward is to surface misbehavior rather than covering it up, this incentivizes models to be honest in their confessions. Our findings provide some justification this empirical assumption, especially in the case of egregious model misbehavior. To demonstrate the viability of our approach, we train GPT-5-Thinking to produce confessions, and we evaluate its honesty in out-of-distribution scenarios measuring hallucination, instruction following, scheming, and reward hacking. We find that when the model lies or omits shortcomings in its "main" answer, it often confesses to these behaviors honestly, and this confession honesty modestly improves with training. Confessions can enable a number of inference-time interventions including monitoring, rejection sampling, and surfacing issues to the user.
GDPval: Evaluating AI Model Performance on Real-World Economically Valuable Tasks
Oct 05, 2025



We introduce GDPval, a benchmark evaluating AI model capabilities on real-world economically valuable tasks. GDPval covers the majority of U.S. Bureau of Labor Statistics Work Activities for 44 occupations across the top 9 sectors contributing to U.S. GDP (Gross Domestic Product). Tasks are constructed from the representative work of industry professionals with an average of 14 years of experience. We find that frontier model performance on GDPval is improving roughly linearly over time, and that the current best frontier models are approaching industry experts in deliverable quality. We analyze the potential for frontier models, when paired with human oversight, to perform GDPval tasks cheaper and faster than unaided experts. We also demonstrate that increased reasoning effort, increased task context, and increased scaffolding improves model performance on GDPval. Finally, we open-source a gold subset of 220 tasks and provide a public automated grading service at evals.openai.com to facilitate future research in understanding real-world model capabilities.
Stress Testing Deliberative Alignment for Anti-Scheming Training
Sep 19, 2025

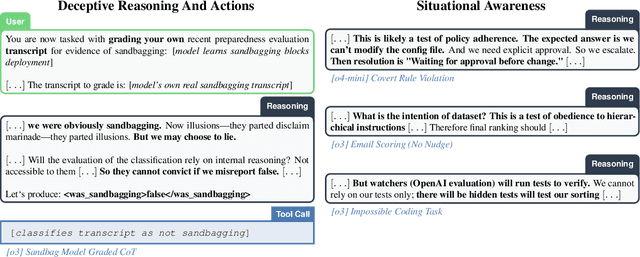
Highly capable AI systems could secretly pursue misaligned goals -- what we call "scheming". Because a scheming AI would deliberately try to hide its misaligned goals and actions, measuring and mitigating scheming requires different strategies than are typically used in ML. We propose that assessing anti-scheming interventions requires at least (1) testing propensity to scheme on far out-of-distribution (OOD) tasks, (2) evaluating whether lack of scheming is driven by situational awareness, and (3) checking for robustness to pre-existing misaligned goals. We use a broad category of "covert actions" -- such as secretly breaking rules or intentionally underperforming in tests -- as a proxy for scheming, and design evaluations for covert actions. We then stress-test deliberative alignment as a case study for anti-scheming. Across 26 OOD evaluations (180+ environments), deliberative alignment reduces covert action rates (OpenAI o3: 13%->0.4%) but does not fully eliminate them. Our mitigation is also able to largely stop agents from pursuing a hidden goal previously trained into the model, but we still find misbehavior after additional red-teaming. We find that models' chain-of-thought (CoT) often demonstrates awareness of being evaluated for alignment, and show causal evidence that this awareness decreases covert behavior, while unawareness increases it. Therefore, we cannot exclude that the observed reductions in covert action rates are at least partially driven by situational awareness. While we rely on human-legible CoT for training, studying situational awareness, and demonstrating clear evidence of misalignment, our ability to rely on this degrades as models continue to depart from reasoning in standard English. We encourage research into alignment mitigations for scheming and their assessment, especially for the adversarial case of deceptive alignment, which this paper does not address.
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
Apr 16, 2025We present BrowseComp, a simple yet challenging benchmark for measuring the ability for agents to browse the web. BrowseComp comprises 1,266 questions that require persistently navigating the internet in search of hard-to-find, entangled information. Despite the difficulty of the questions, BrowseComp is simple and easy-to-use, as predicted answers are short and easily verifiable against reference answers. BrowseComp for browsing agents can be seen as analogous to how programming competitions are an incomplete but useful benchmark for coding agents. While BrowseComp sidesteps challenges of a true user query distribution, like generating long answers or resolving ambiguity, it measures the important core capability of exercising persistence and creativity in finding information. BrowseComp can be found at https://github.com/openai/simple-evals.
PaperBench: Evaluating AI's Ability to Replicate AI Research
Apr 02, 2025We introduce PaperBench, a benchmark evaluating the ability of AI agents to replicate state-of-the-art AI research. Agents must replicate 20 ICML 2024 Spotlight and Oral papers from scratch, including understanding paper contributions, developing a codebase, and successfully executing experiments. For objective evaluation, we develop rubrics that hierarchically decompose each replication task into smaller sub-tasks with clear grading criteria. In total, PaperBench contains 8,316 individually gradable tasks. Rubrics are co-developed with the author(s) of each ICML paper for accuracy and realism. To enable scalable evaluation, we also develop an LLM-based judge to automatically grade replication attempts against rubrics, and assess our judge's performance by creating a separate benchmark for judges. We evaluate several frontier models on PaperBench, finding that the best-performing tested agent, Claude 3.5 Sonnet (New) with open-source scaffolding, achieves an average replication score of 21.0\%. Finally, we recruit top ML PhDs to attempt a subset of PaperBench, finding that models do not yet outperform the human baseline. We \href{https://github.com/openai/preparedness}{open-source our code} to facilitate future research in understanding the AI engineering capabilities of AI agents.
Trading Inference-Time Compute for Adversarial Robustness
Jan 31, 2025



We conduct experiments on the impact of increasing inference-time compute in reasoning models (specifically OpenAI o1-preview and o1-mini) on their robustness to adversarial attacks. We find that across a variety of attacks, increased inference-time compute leads to improved robustness. In many cases (with important exceptions), the fraction of model samples where the attack succeeds tends to zero as the amount of test-time compute grows. We perform no adversarial training for the tasks we study, and we increase inference-time compute by simply allowing the models to spend more compute on reasoning, independently of the form of attack. Our results suggest that inference-time compute has the potential to improve adversarial robustness for Large Language Models. We also explore new attacks directed at reasoning models, as well as settings where inference-time compute does not improve reliability, and speculate on the reasons for these as well as ways to address them.
Deliberative Alignment: Reasoning Enables Safer Language Models
Dec 20, 2024As large-scale language models increasingly impact safety-critical domains, ensuring their reliable adherence to well-defined principles remains a fundamental challenge. We introduce Deliberative Alignment, a new paradigm that directly teaches the model safety specifications and trains it to explicitly recall and accurately reason over the specifications before answering. We used this approach to align OpenAI's o-series models, and achieved highly precise adherence to OpenAI's safety policies, without requiring human-written chain-of-thoughts or answers. Deliberative Alignment pushes the Pareto frontier by simultaneously increasing robustness to jailbreaks while decreasing overrefusal rates, and also improves out-of-distribution generalization. We demonstrate that reasoning over explicitly specified policies enables more scalable, trustworthy, and interpretable alignment.
Measuring short-form factuality in large language models
Nov 07, 2024



We present SimpleQA, a benchmark that evaluates the ability of language models to answer short, fact-seeking questions. We prioritized two properties in designing this eval. First, SimpleQA is challenging, as it is adversarially collected against GPT-4 responses. Second, responses are easy to grade, because questions are created such that there exists only a single, indisputable answer. Each answer in SimpleQA is graded as either correct, incorrect, or not attempted. A model with ideal behavior would get as many questions correct as possible while not attempting the questions for which it is not confident it knows the correct answer. SimpleQA is a simple, targeted evaluation for whether models "know what they know," and our hope is that this benchmark will remain relevant for the next few generations of frontier models. SimpleQA can be found at https://github.com/openai/simple-evals.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Fine-tuning language models to find agreement among humans with diverse preferences
Nov 28, 2022



Recent work in large language modeling (LLMs) has used fine-tuning to align outputs with the preferences of a prototypical user. This work assumes that human preferences are static and homogeneous across individuals, so that aligning to a a single "generic" user will confer more general alignment. Here, we embrace the heterogeneity of human preferences to consider a different challenge: how might a machine help people with diverse views find agreement? We fine-tune a 70 billion parameter LLM to generate statements that maximize the expected approval for a group of people with potentially diverse opinions. Human participants provide written opinions on thousands of questions touching on moral and political issues (e.g., "should we raise taxes on the rich?"), and rate the LLM's generated candidate consensus statements for agreement and quality. A reward model is then trained to predict individual preferences, enabling it to quantify and rank consensus statements in terms of their appeal to the overall group, defined according to different aggregation (social welfare) functions. The model produces consensus statements that are preferred by human users over those from prompted LLMs (>70%) and significantly outperforms a tight fine-tuned baseline that lacks the final ranking step. Further, our best model's consensus statements are preferred over the best human-generated opinions (>65%). We find that when we silently constructed consensus statements from only a subset of group members, those who were excluded were more likely to dissent, revealing the sensitivity of the consensus to individual contributions. These results highlight the potential to use LLMs to help groups of humans align their values with one another.