 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeType-Compliant Adaptation Cascades: Adapting Programmatic LM Workflows to Data
Aug 25, 2025Reliably composing Large Language Models (LLMs) for complex, multi-step workflows remains a significant challenge. The dominant paradigm-optimizing discrete prompts in a pipeline-is notoriously brittle and struggles to enforce the formal compliance required for structured tasks. We introduce Type-Compliant Adaptation Cascades (TACs), a framework that recasts workflow adaptation as learning typed probabilistic programs. TACs treats the entire workflow, which is composed of parameter-efficiently adapted LLMs and deterministic logic, as an unnormalized joint distribution. This enables principled, gradient-based training even with latent intermediate structures. We provide theoretical justification for our tractable optimization objective, proving that the optimization bias vanishes as the model learns type compliance. Empirically, TACs significantly outperforms state-of-the-art prompt-optimization baselines. Gains are particularly pronounced on structured tasks, improving MGSM-SymPy from $57.1\%$ to $75.9\%$ for a 27B model, MGSM from $1.6\%$ to $27.3\%$ for a 7B model. TACs offers a robust and theoretically grounded paradigm for developing reliable, task-compliant LLM systems.
Best Practices and Lessons Learned on Synthetic Data for Language Models
Apr 11, 2024
The success of AI models relies on the availability of large, diverse, and high-quality datasets, which can be challenging to obtain due to data scarcity, privacy concerns, and high costs. Synthetic data has emerged as a promising solution by generating artificial data that mimics real-world patterns. This paper provides an overview of synthetic data research, discussing its applications, challenges, and future directions. We present empirical evidence from prior art to demonstrate its effectiveness and highlight the importance of ensuring its factuality, fidelity, and unbiasedness. We emphasize the need for responsible use of synthetic data to build more powerful, inclusive, and trustworthy language models.
Long-form factuality in large language models
Apr 03, 2024



Large language models (LLMs) often generate content that contains factual errors when responding to fact-seeking prompts on open-ended topics. To benchmark a model's long-form factuality in open domains, we first use GPT-4 to generate LongFact, a prompt set comprising thousands of questions spanning 38 topics. We then propose that LLM agents can be used as automated evaluators for long-form factuality through a method which we call Search-Augmented Factuality Evaluator (SAFE). SAFE utilizes an LLM to break down a long-form response into a set of individual facts and to evaluate the accuracy of each fact using a multi-step reasoning process comprising sending search queries to Google Search and determining whether a fact is supported by the search results. Furthermore, we propose extending F1 score as an aggregated metric for long-form factuality. To do so, we balance the percentage of supported facts in a response (precision) with the percentage of provided facts relative to a hyperparameter representing a user's preferred response length (recall). Empirically, we demonstrate that LLM agents can outperform crowdsourced human annotators - on a set of ~16k individual facts, SAFE agrees with crowdsourced human annotators 72% of the time, and on a random subset of 100 disagreement cases, SAFE wins 76% of the time. At the same time, SAFE is more than 20 times cheaper than human annotators. We also benchmark thirteen language models on LongFact across four model families (Gemini, GPT, Claude, and PaLM-2), finding that larger language models generally achieve better long-form factuality. LongFact, SAFE, and all experimental code are available at https://github.com/google-deepmind/long-form-factuality.
OmniPred: Language Models as Universal Regressors
Mar 04, 2024Over the broad landscape of experimental design, regression has been a powerful tool to accurately predict the outcome metrics of a system or model given a set of parameters, but has been traditionally restricted to methods which are only applicable to a specific task. In this paper, we propose OmniPred, a framework for training language models as universal end-to-end regressors over $(x,y)$ evaluation data from diverse real world experiments. Using data sourced from Google Vizier, one of the largest blackbox optimization databases in the world, our extensive experiments demonstrate that through only textual representations of mathematical parameters and values, language models are capable of very precise numerical regression, and if given the opportunity to train over multiple tasks, can significantly outperform traditional regression models.
Higher Layers Need More LoRA Experts
Feb 13, 2024



Parameter-efficient tuning (PEFT) techniques like low-rank adaptation (LoRA) offer training efficiency on Large Language Models, but their impact on model performance remains limited. Recent efforts integrate LoRA and Mixture-of-Experts (MoE) to improve the performance of PEFT methods. Despite promising results, research on improving the efficiency of LoRA with MoE is still in its early stages. Recent studies have shown that experts in the MoE architecture have different strengths and also exhibit some redundancy. Does this statement also apply to parameter-efficient MoE? In this paper, we introduce a novel parameter-efficient MoE method, \textit{\textbf{M}oE-L\textbf{o}RA with \textbf{L}ayer-wise Expert \textbf{A}llocation (MoLA)} for Transformer-based models, where each model layer has the flexibility to employ a varying number of LoRA experts. We investigate several architectures with varying layer-wise expert configurations. Experiments on six well-known NLP and commonsense QA benchmarks demonstrate that MoLA achieves equal or superior performance compared to all baselines. We find that allocating more LoRA experts to higher layers further enhances the effectiveness of models with a certain number of experts in total. With much fewer parameters, this allocation strategy outperforms the setting with the same number of experts in every layer. This work can be widely used as a plug-and-play parameter-efficient tuning approach for various applications. The code is available at https://github.com/GCYZSL/MoLA.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Brainformers: Trading Simplicity for Efficiency
May 29, 2023



Transformers are central to recent successes in natural language processing and computer vision. Transformers have a mostly uniform backbone where layers alternate between feed-forward and self-attention in order to build a deep network. Here we investigate this design choice and find that more complex blocks that have different permutations of layer primitives can be more efficient. Using this insight, we develop a complex block, named Brainformer, that consists of a diverse sets of layers such as sparsely gated feed-forward layers, dense feed-forward layers, attention layers, and various forms of layer normalization and activation functions. Brainformer consistently outperforms the state-of-the-art dense and sparse Transformers, in terms of both quality and efficiency. A Brainformer model with 8 billion activated parameters per token demonstrates 2x faster training convergence and 5x faster step time compared to its GLaM counterpart. In downstream task evaluation, Brainformer also demonstrates a 3% higher SuperGLUE score with fine-tuning compared to GLaM with a similar number of activated parameters. Finally, Brainformer largely outperforms a Primer dense model derived with NAS with similar computation per token on fewshot evaluations.
LayerNAS: Neural Architecture Search in Polynomial Complexity
Apr 23, 2023Neural Architecture Search (NAS) has become a popular method for discovering effective model architectures, especially for target hardware. As such, NAS methods that find optimal architectures under constraints are essential. In our paper, we propose LayerNAS to address the challenge of multi-objective NAS by transforming it into a combinatorial optimization problem, which effectively constrains the search complexity to be polynomial. For a model architecture with $L$ layers, we perform layerwise-search for each layer, selecting from a set of search options $\mathbb{S}$. LayerNAS groups model candidates based on one objective, such as model size or latency, and searches for the optimal model based on another objective, thereby splitting the cost and reward elements of the search. This approach limits the search complexity to $ O(H \cdot |\mathbb{S}| \cdot L) $, where $H$ is a constant set in LayerNAS. Our experiments show that LayerNAS is able to consistently discover superior models across a variety of search spaces in comparison to strong baselines, including search spaces derived from NATS-Bench, MobileNetV2 and MobileNetV3.
PyGlove: Efficiently Exchanging ML Ideas as Code
Feb 03, 2023



The increasing complexity and scale of machine learning (ML) has led to the need for more efficient collaboration among multiple teams. For example, when a research team invents a new architecture like "ResNet," it is desirable for multiple engineering teams to adopt it. However, the effort required for each team to study and understand the invention does not scale well with the number of teams or inventions. In this paper, we present an extension of our PyGlove library to easily and scalably share ML ideas. PyGlove represents ideas as symbolic rule-based patches, enabling researchers to write down the rules for models they have not seen. For example, an inventor can write rules that will "add skip-connections." This permits a network effect among teams: at once, any team can issue patches to all other teams. Such a network effect allows users to quickly surmount the cost of adopting PyGlove by writing less code quicker, providing a benefit that scales with time. We describe the new paradigm of organizing ML through symbolic patches and compare it to existing approaches. We also perform a case study of a large codebase where PyGlove led to an 80% reduction in the number of lines of code.
DeepFusion: Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection
Mar 15, 2022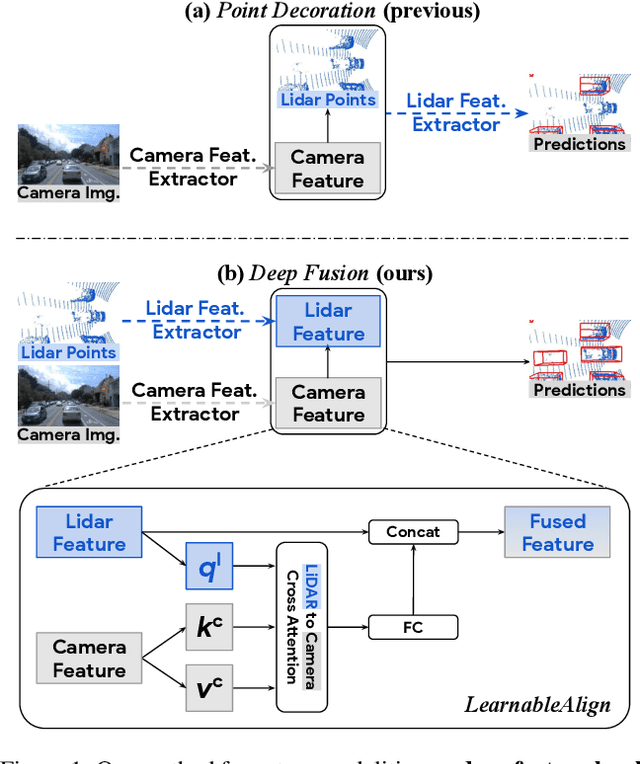
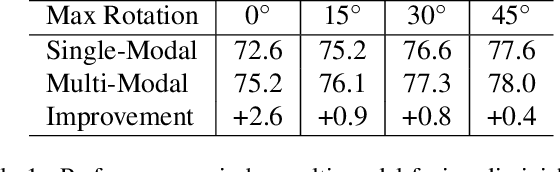
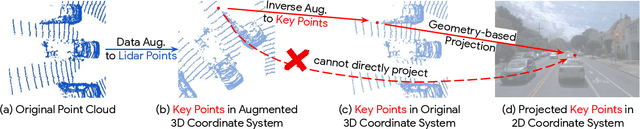
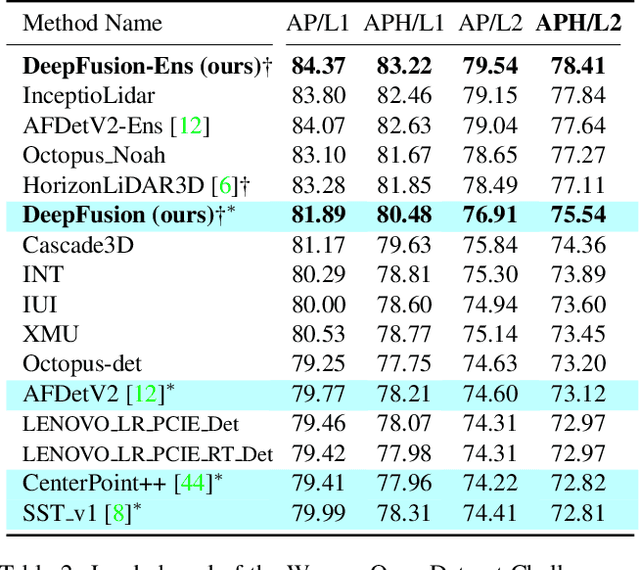
Lidars and cameras are critical sensors that provide complementary information for 3D detection in autonomous driving. While prevalent multi-modal methods simply decorate raw lidar point clouds with camera features and feed them directly to existing 3D detection models, our study shows that fusing camera features with deep lidar features instead of raw points, can lead to better performance. However, as those features are often augmented and aggregated, a key challenge in fusion is how to effectively align the transformed features from two modalities. In this paper, we propose two novel techniques: InverseAug that inverses geometric-related augmentations, e.g., rotation, to enable accurate geometric alignment between lidar points and image pixels, and LearnableAlign that leverages cross-attention to dynamically capture the correlations between image and lidar features during fusion. Based on InverseAug and LearnableAlign, we develop a family of generic multi-modal 3D detection models named DeepFusion, which is more accurate than previous methods. For example, DeepFusion improves PointPillars, CenterPoint, and 3D-MAN baselines on Pedestrian detection for 6.7, 8.9, and 6.2 LEVEL_2 APH, respectively. Notably, our models achieve state-of-the-art performance on Waymo Open Dataset, and show strong model robustness against input corruptions and out-of-distribution data. Code will be publicly available at https://github.com/tensorflow/lingvo/tree/master/lingvo/.