 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
LaMDA: Language Models for Dialog Applications
Feb 10, 2022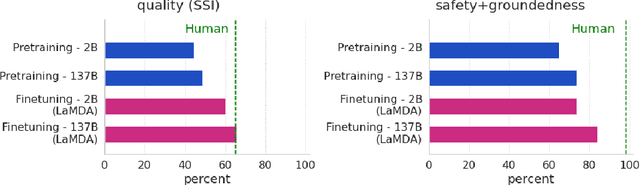
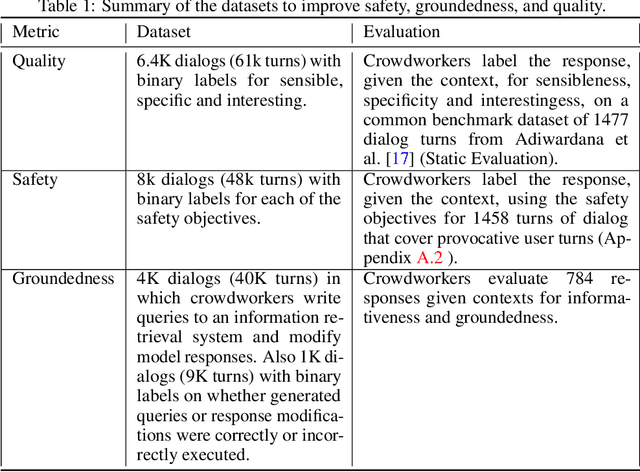
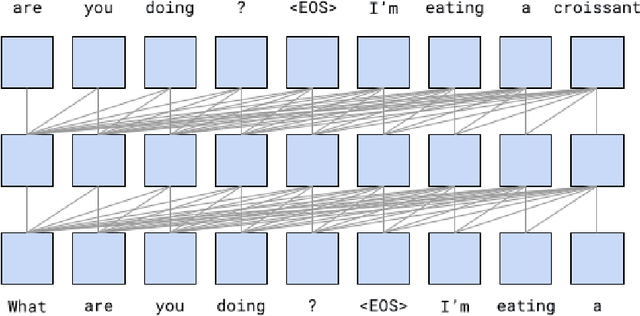

We present LaMDA: Language Models for Dialog Applications. LaMDA is a family of Transformer-based neural language models specialized for dialog, which have up to 137B parameters and are pre-trained on 1.56T words of public dialog data and web text. While model scaling alone can improve quality, it shows less improvements on safety and factual grounding. We demonstrate that fine-tuning with annotated data and enabling the model to consult external knowledge sources can lead to significant improvements towards the two key challenges of safety and factual grounding. The first challenge, safety, involves ensuring that the model's responses are consistent with a set of human values, such as preventing harmful suggestions and unfair bias. We quantify safety using a metric based on an illustrative set of human values, and we find that filtering candidate responses using a LaMDA classifier fine-tuned with a small amount of crowdworker-annotated data offers a promising approach to improving model safety. The second challenge, factual grounding, involves enabling the model to consult external knowledge sources, such as an information retrieval system, a language translator, and a calculator. We quantify factuality using a groundedness metric, and we find that our approach enables the model to generate responses grounded in known sources, rather than responses that merely sound plausible. Finally, we explore the use of LaMDA in the domains of education and content recommendations, and analyze their helpfulness and role consistency.
Measuring Attribution in Natural Language Generation Models
Dec 23, 2021

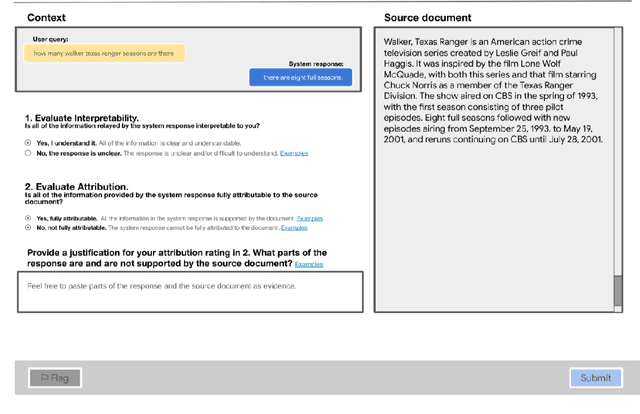
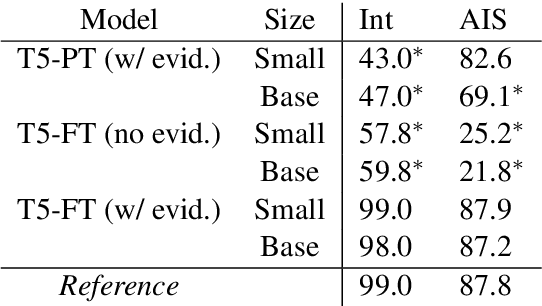
With recent improvements in natural language generation (NLG) models for various applications, it has become imperative to have the means to identify and evaluate whether NLG output is only sharing verifiable information about the external world. In this work, we present a new evaluation framework entitled Attributable to Identified Sources (AIS) for assessing the output of natural language generation models, when such output pertains to the external world. We first define AIS and introduce a two-stage annotation pipeline for allowing annotators to appropriately evaluate model output according to AIS guidelines. We empirically validate this approach on three generation datasets (two in the conversational QA domain and one in summarization) via human evaluation studies that suggest that AIS could serve as a common framework for measuring whether model-generated statements are supported by underlying sources. We release guidelines for the human evaluation studies.
Retrieval-guided Counterfactual Generation for QA
Oct 14, 2021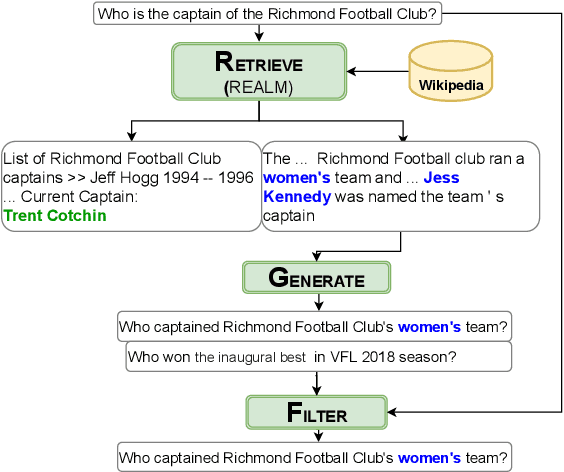


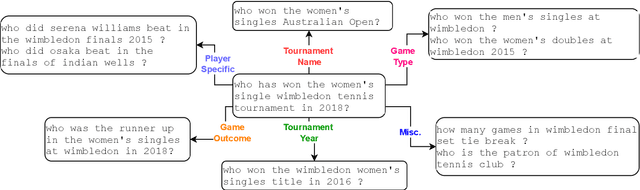
Deep NLP models have been shown to learn spurious correlations, leaving them brittle to input perturbations. Recent work has shown that counterfactual or contrastive data -- i.e. minimally perturbed inputs -- can reveal these weaknesses, and that data augmentation using counterfactuals can help ameliorate them. Proposed techniques for generating counterfactuals rely on human annotations, perturbations based on simple heuristics, and meaning representation frameworks. We focus on the task of creating counterfactuals for question answering, which presents unique challenges related to world knowledge, semantic diversity, and answerability. To address these challenges, we develop a Retrieve-Generate-Filter(RGF) technique to create counterfactual evaluation and training data with minimal human supervision. Using an open-domain QA framework and question generation model trained on original task data, we create counterfactuals that are fluent, semantically diverse, and automatically labeled. Data augmentation with RGF counterfactuals improves performance on out-of-domain and challenging evaluation sets over and above existing methods, in both the reading comprehension and open-domain QA settings. Moreover, we find that RGF data leads to significant improvements in a model's robustness to local perturbations.
Decontextualization: Making Sentences Stand-Alone
Feb 09, 2021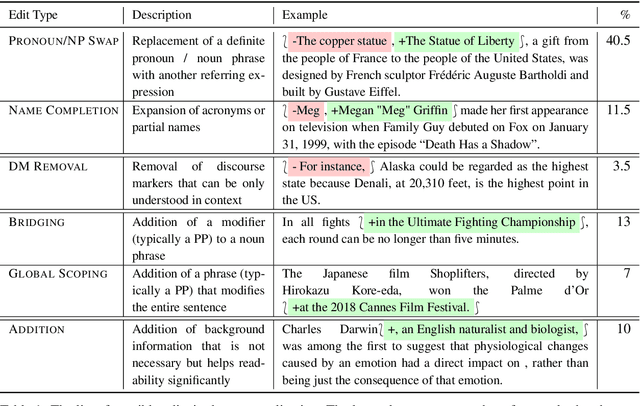


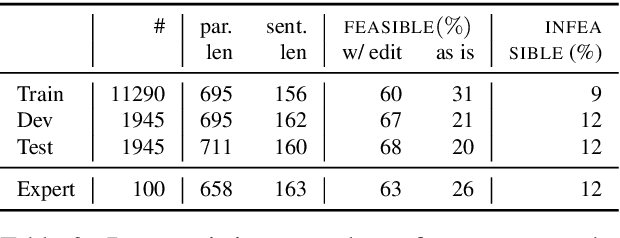
Models for question answering, dialogue agents, and summarization often interpret the meaning of a sentence in a rich context and use that meaning in a new context. Taking excerpts of text can be problematic, as key pieces may not be explicit in a local window. We isolate and define the problem of sentence decontextualization: taking a sentence together with its context and rewriting it to be interpretable out of context, while preserving its meaning. We describe an annotation procedure, collect data on the Wikipedia corpus, and use the data to train models to automatically decontextualize sentences. We present preliminary studies that show the value of sentence decontextualization in a user facing task, and as preprocessing for systems that perform document understanding. We argue that decontextualization is an important subtask in many downstream applications, and that the definitions and resources provided can benefit tasks that operate on sentences that occur in a richer context.
QED: A Framework and Dataset for Explanations in Question Answering
Sep 08, 2020
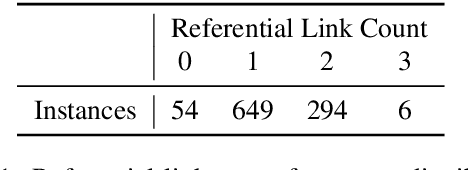
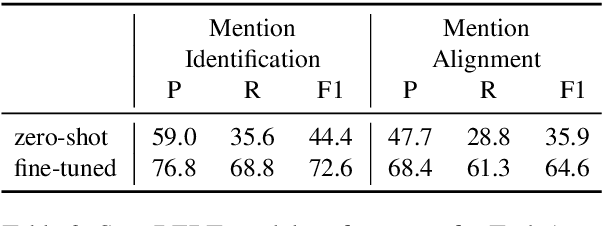

A question answering system that in addition to providing an answer provides an explanation of the reasoning that leads to that answer has potential advantages in terms of debuggability, extensibility and trust. To this end, we propose QED, a linguistically informed, extensible framework for explanations in question answering. A QED explanation specifies the relationship between a question and answer according to formal semantic notions such as referential equality, sentencehood, and entailment. We describe and publicly release an expert-annotated dataset of QED explanations built upon a subset of the Google Natural Questions dataset, and report baseline models on two tasks -- post-hoc explanation generation given an answer, and joint question answering and explanation generation. In the joint setting, a promising result suggests that training on a relatively small amount of QED data can improve question answering. In addition to describing the formal, language-theoretic motivations for the QED approach, we describe a large user study showing that the presence of QED explanations significantly improves the ability of untrained raters to spot errors made by a strong neural QA baseline.
Compositional Generalization in Image Captioning
Sep 16, 2019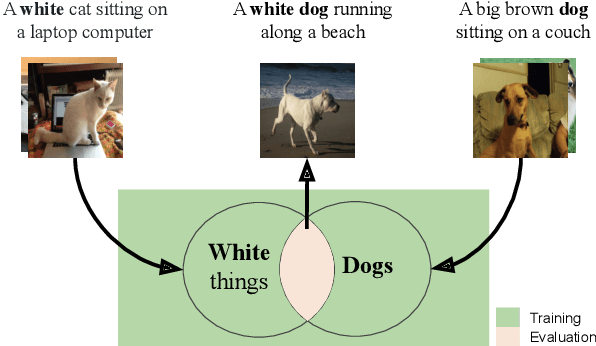

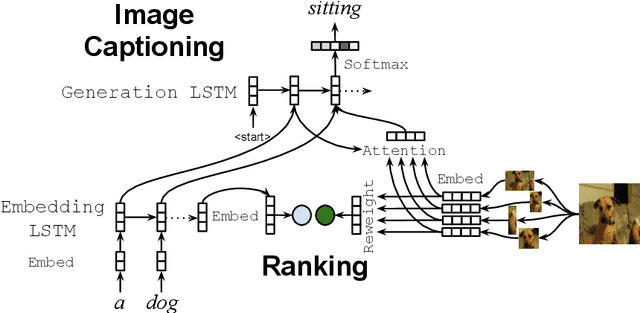
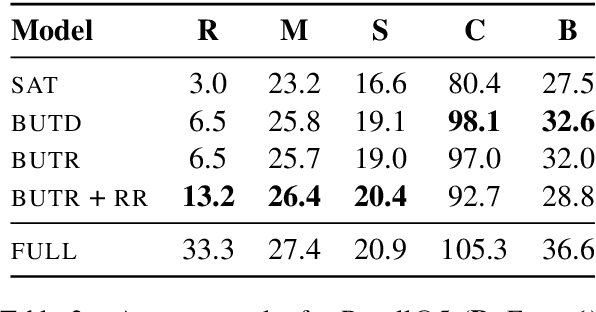
Image captioning models are usually evaluated on their ability to describe a held-out set of images, not on their ability to generalize to unseen concepts. We study the problem of compositional generalization, which measures how well a model composes unseen combinations of concepts when describing images. State-of-the-art image captioning models show poor generalization performance on this task. We propose a multi-task model to address the poor performance, that combines caption generation and image--sentence ranking, and uses a decoding mechanism that re-ranks the captions according their similarity to the image. This model is substantially better at generalizing to unseen combinations of concepts compared to state-of-the-art captioning models.
Ellipsis and Coreference Resolution as Question Answering
Aug 29, 2019
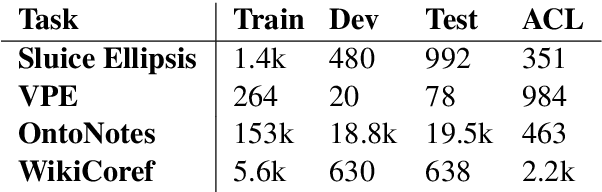

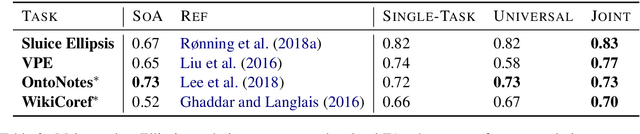
Coreference and many forms of ellipsis are similar to reading comprehension questions, in that in order to resolve these, we need to identify an appropriate text span in the previous discourse. This paper exploits this analogy and proposes to use an architecture developed for machine comprehension for ellipsis and coreference resolution. We present both single-task and joint models and evaluate them across standard benchmarks, outperforming the current state of the art for ellipsis by up to 48.5% error reduction -- and for coreference by 37.5% error reduction.
Textual Analogy Parsing: What's Shared and What's Compared among Analogous Facts
Sep 07, 2018

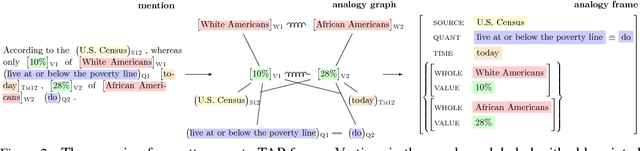
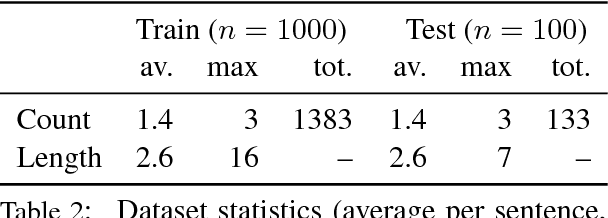
To understand a sentence like "whereas only 10% of White Americans live at or below the poverty line, 28% of African Americans do" it is important not only to identify individual facts, e.g., poverty rates of distinct demographic groups, but also the higher-order relations between them, e.g., the disparity between them. In this paper, we propose the task of Textual Analogy Parsing (TAP) to model this higher-order meaning. The output of TAP is a frame-style meaning representation which explicitly specifies what is shared (e.g., poverty rates) and what is compared (e.g., White Americans vs. African Americans, 10% vs. 28%) between its component facts. Such a meaning representation can enable new applications that rely on discourse understanding such as automated chart generation from quantitative text. We present a new dataset for TAP, baselines, and a model that successfully uses an ILP to enforce the structural constraints of the problem.