 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTEM: Semantic Target Search and Exploration using MAVs in Cluttered Environments
May 30, 2026Autonomous target search is crucial for deploying Micro Aerial Vehicles (MAVs) in emergency response and rescue missions. Existing approaches either focus on 2D semantic navigation in structured environments -- which is less effective in complex 3D settings, or on robotic exploration in cluttered spaces -- which often lacks the semantic reasoning needed for efficient target search. This paper overcomes these limitations by proposing a novel framework that utilizes a semantically-guided viewpoint planner to minimize target search and exploration time in unstructured 3D environments using an MAV. Specifically, we develop a combinatorial planner that generates efficient semantic exploration plans by prioritizing viewpoints that likely lead to the target. To guide the planner towards the target, an active perception pipeline is developed that propagates semantic priorities of observed objects into neighboring frontier voxels for computing semantic information gains of frontier viewpoints. In addition, we demonstrate how LLM-based similarity scores can be leveraged as semantic priority input to our pipeline. Evaluations in two distinct simulation environments show that the proposed method consistently outperforms baselines by quickly finding the target while maintaining reasonable exploration times. Real-world experiments with an MAV further demonstrate the method's ability to handle practical constraints like limited battery life, small sensor range, and semantic uncertainty.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Drone Flocking Optimization using NSGA-II and Principal Component Analysis
May 01, 2022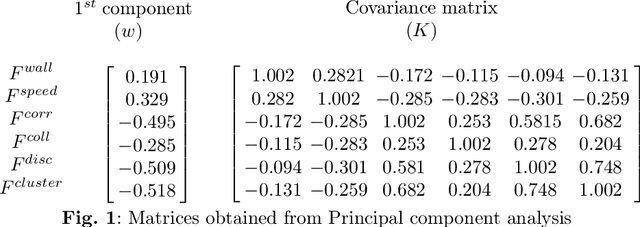
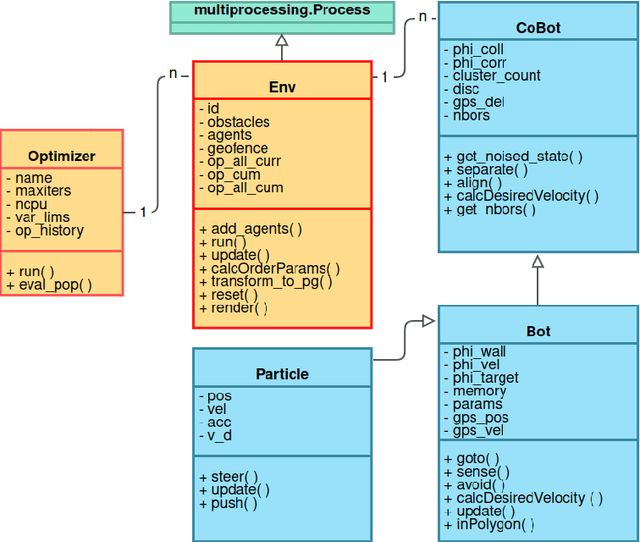
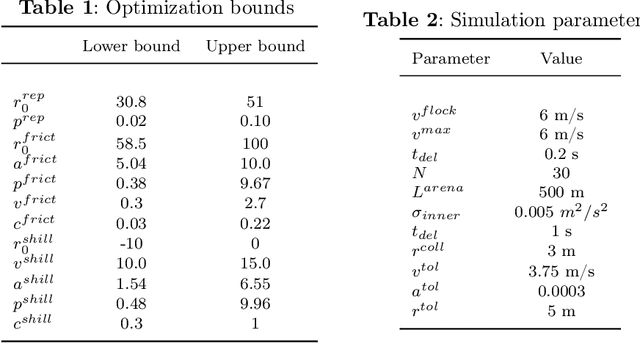

Individual agents in natural systems like flocks of birds or schools of fish display a remarkable ability to coordinate and communicate in local groups and execute a variety of tasks efficiently. Emulating such natural systems into drone swarms to solve problems in defence, agriculture, industry automation and humanitarian relief is an emerging technology. However, flocking of aerial robots while maintaining multiple objectives, like collision avoidance, high speed etc. is still a challenge. In this paper, optimized flocking of drones in a confined environment with multiple conflicting objectives is proposed. The considered objectives are collision avoidance (with each other and the wall), speed, correlation, and communication (connected and disconnected agents). Principal Component Analysis (PCA) is applied for dimensionality reduction, and understanding the collective dynamics of the swarm. The control model is characterised by 12 parameters which are then optimized using a multi-objective solver (NSGA-II). The obtained results are reported and compared with that of the CMA-ES algorithm. The study is particularly useful as the proposed optimizer outputs a Pareto Front representing different types of swarms which can applied to different scenarios in the real world.