 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Memory Augmented Language Models through Mixture of Word Experts
Nov 15, 2023



Scaling up the number of parameters of language models has proven to be an effective approach to improve performance. For dense models, increasing model size proportionally increases the model's computation footprint. In this work, we seek to aggressively decouple learning capacity and FLOPs through Mixture-of-Experts (MoE) style models with large knowledge-rich vocabulary based routing functions and experts. Our proposed approach, dubbed Mixture of Word Experts (MoWE), can be seen as a memory augmented model, where a large set of word-specific experts play the role of a sparse memory. We demonstrate that MoWE performs significantly better than the T5 family of models with similar number of FLOPs in a variety of NLP tasks. Additionally, MoWE outperforms regular MoE models on knowledge intensive tasks and has similar performance to more complex memory augmented approaches that often require to invoke custom mechanisms to search the sparse memory.
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
May 22, 2023



Multi-query attention (MQA), which only uses a single key-value head, drastically speeds up decoder inference. However, MQA can lead to quality degradation, and moreover it may not be desirable to train a separate model just for faster inference. We (1) propose a recipe for uptraining existing multi-head language model checkpoints into models with MQA using 5% of original pre-training compute, and (2) introduce grouped-query attention (GQA), a generalization of multi-query attention which uses an intermediate (more than one, less than number of query heads) number of key-value heads. We show that uptrained GQA achieves quality close to multi-head attention with comparable speed to MQA.
CoLT5: Faster Long-Range Transformers with Conditional Computation
Mar 17, 2023Many natural language processing tasks benefit from long inputs, but processing long documents with Transformers is expensive -- not only due to quadratic attention complexity but also from applying feedforward and projection layers to every token. However, not all tokens are equally important, especially for longer documents. We propose CoLT5, a long-input Transformer model that builds on this intuition by employing conditional computation, devoting more resources to important tokens in both feedforward and attention layers. We show that CoLT5 achieves stronger performance than LongT5 with much faster training and inference, achieving SOTA on the long-input SCROLLS benchmark. Moreover, CoLT5 can effectively and tractably make use of extremely long inputs, showing strong gains up to 64k input length.
Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints
Dec 09, 2022



Training large, deep neural networks to convergence can be prohibitively expensive. As a result, often only a small selection of popular, dense models are reused across different contexts and tasks. Increasingly, sparsely activated models, which seek to decouple model size from computation costs, are becoming an attractive alternative to dense models. Although more efficient in terms of quality and computation cost, sparse models remain data-hungry and costly to train from scratch in the large scale regime. In this work, we propose sparse upcycling -- a simple way to reuse sunk training costs by initializing a sparsely activated Mixture-of-Experts model from a dense checkpoint. We show that sparsely upcycled T5 Base, Large, and XL language models and Vision Transformer Base and Large models, respectively, significantly outperform their dense counterparts on SuperGLUE and ImageNet, using only ~50% of the initial dense pretraining sunk cost. The upcycled models also outperform sparse models trained from scratch on 100% of the initial dense pretraining computation budget.
Sparse Mixers: Combining MoE and Mixing to build a more efficient BERT
May 24, 2022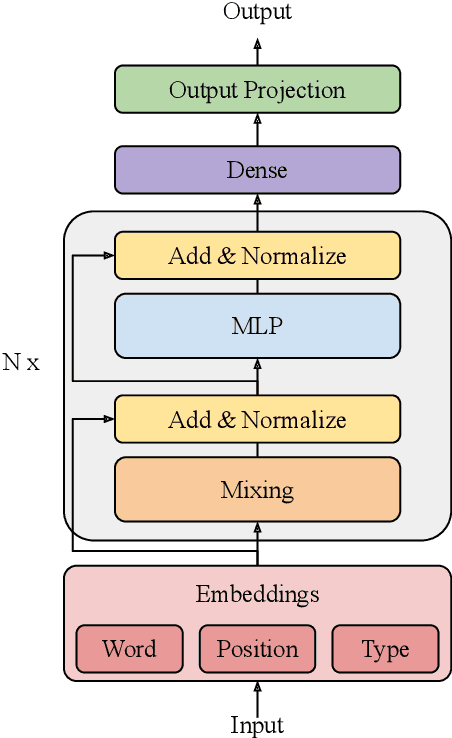
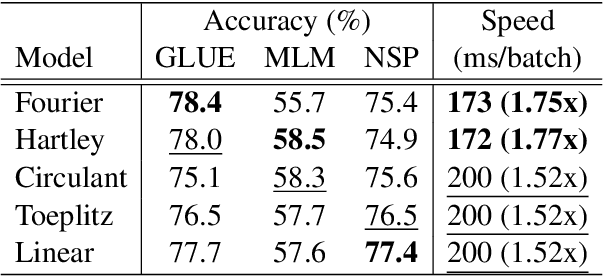
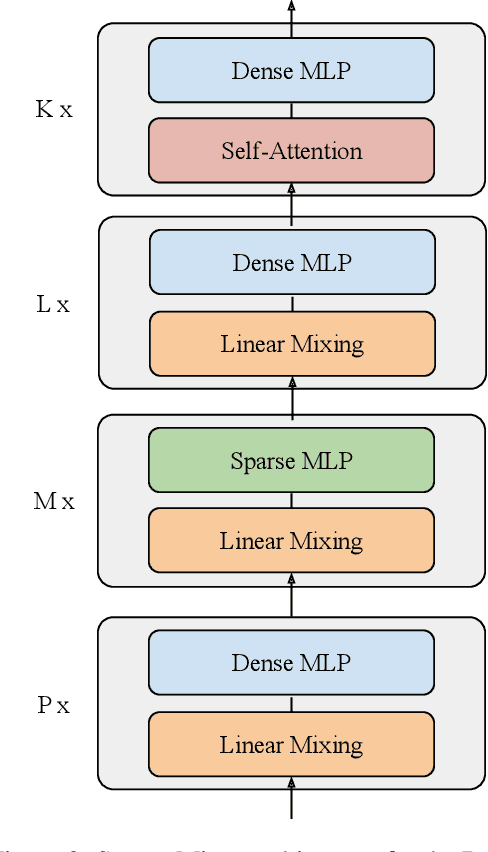
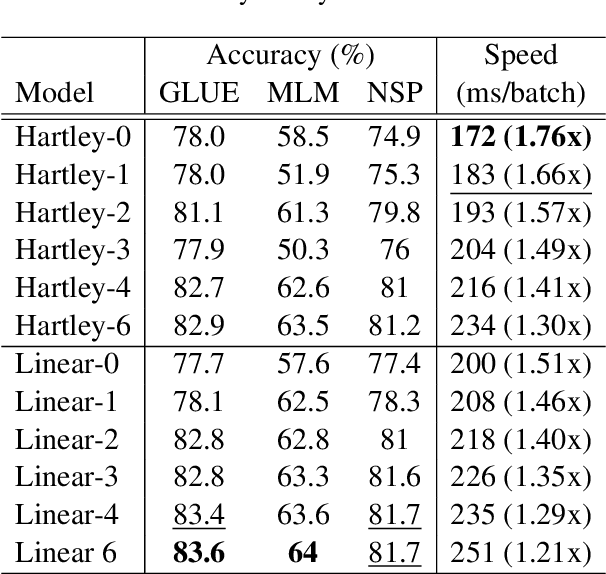
We combine the capacity of sparsely gated Mixture-of-Experts (MoE) with the speed and stability of linear, mixing transformations to design the Sparse Mixer encoder model. The Sparse Mixer slightly outperforms (<1%) BERT on GLUE and SuperGLUE, but more importantly trains 65% faster and runs inference 61% faster. We also present a faster variant, prosaically named Fast Sparse Mixer, that marginally underperforms (<0.2%) BERT on SuperGLUE, but trains and runs nearly twice as fast: 89% faster training and 98% faster inference. We justify the design of these two models by carefully ablating through various mixing mechanisms, MoE configurations and model hyperparameters. The Sparse Mixer overcomes many of the latency and stability concerns of MoE models and offers the prospect of serving sparse student models, without resorting to distilling them to dense variants.
Scaling Up Models and Data with $\texttt{t5x}$ and $\texttt{seqio}$
Mar 31, 2022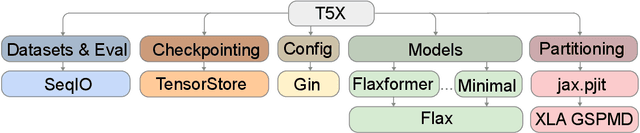
Recent neural network-based language models have benefited greatly from scaling up the size of training datasets and the number of parameters in the models themselves. Scaling can be complicated due to various factors including the need to distribute computation on supercomputer clusters (e.g., TPUs), prevent bottlenecks when infeeding data, and ensure reproducible results. In this work, we present two software libraries that ease these issues: $\texttt{t5x}$ simplifies the process of building and training large language models at scale while maintaining ease of use, and $\texttt{seqio}$ provides a task-based API for simple creation of fast and reproducible training data and evaluation pipelines. These open-source libraries have been used to train models with hundreds of billions of parameters on datasets with multiple terabytes of training data. Along with the libraries, we release configurations and instructions for T5-like encoder-decoder models as well as GPT-like decoder-only architectures. $\texttt{t5x}$ and $\texttt{seqio}$ are open source and available at https://github.com/google-research/t5x and https://github.com/google/seqio, respectively.
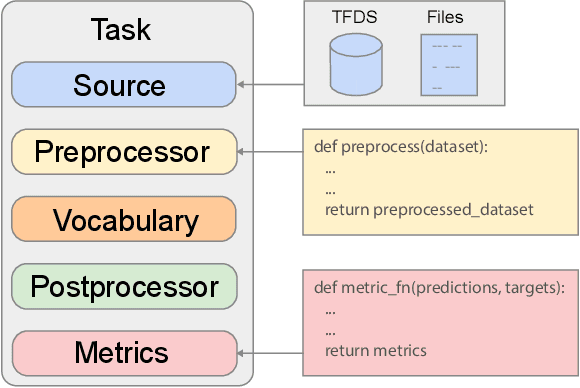
ShopTalk: A System for Conversational Faceted Search
Sep 02, 2021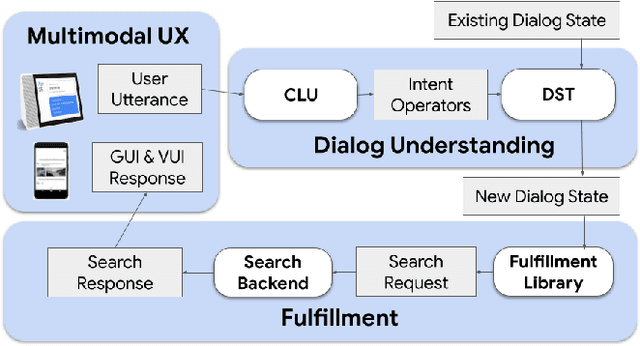


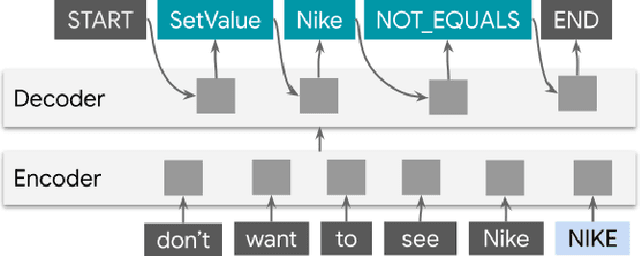
We present ShopTalk, a multi-turn conversational faceted search system for shopping that is designed to handle large and complex schemas that are beyond the scope of state of the art slot-filling systems. ShopTalk decouples dialog management from fulfillment, thereby allowing the dialog understanding system to be domain-agnostic and not tied to the particular shopping application. The dialog understanding system consists of a deep-learned Contextual Language Understanding module, which interprets user utterances, and a primarily rules-based Dialog-State Tracker (DST), which updates the dialog state and formulates search requests intended for the fulfillment engine. The interface between the two modules consists of a minimal set of domain-agnostic "intent operators," which instruct the DST on how to update the dialog state. ShopTalk was deployed in 2020 on the Google Assistant for Shopping searches.
FNet: Mixing Tokens with Fourier Transforms
May 09, 2021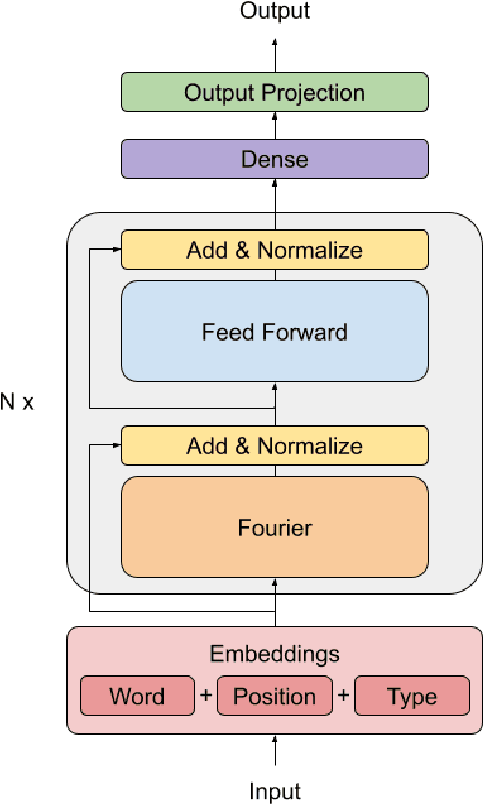

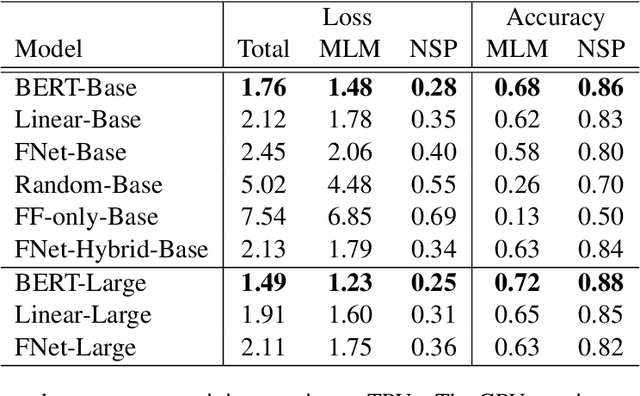
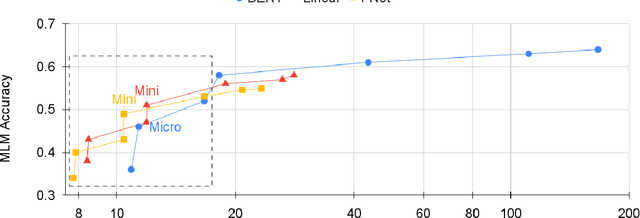
We show that Transformer encoder architectures can be massively sped up, with limited accuracy costs, by replacing the self-attention sublayers with simple linear transformations that "mix" input tokens. These linear transformations, along with simple nonlinearities in feed-forward layers, are sufficient to model semantic relationships in several text classification tasks. Perhaps most surprisingly, we find that replacing the self-attention sublayer in a Transformer encoder with a standard, unparameterized Fourier Transform achieves 92% of the accuracy of BERT on the GLUE benchmark, but pre-trains and runs up to seven times faster on GPUs and twice as fast on TPUs. The resulting model, which we name FNet, scales very efficiently to long inputs, matching the accuracy of the most accurate "efficient" Transformers on the Long Range Arena benchmark, but training and running faster across all sequence lengths on GPUs and relatively shorter sequence lengths on TPUs. Finally, FNet has a light memory footprint and is particularly efficient at smaller model sizes: for a fixed speed and accuracy budget, small FNet models outperform Transformer counterparts.