 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Towards Truly Zero-shot Compositional Visual Reasoning with LLMs as Programmers
Jan 03, 2024



Visual reasoning is dominated by end-to-end neural networks scaled to billions of model parameters and training examples. However, even the largest models struggle with compositional reasoning, generalization, fine-grained spatial and temporal reasoning, and counting. Visual reasoning with large language models (LLMs) as controllers can, in principle, address these limitations by decomposing the task and solving subtasks by orchestrating a set of (visual) tools. Recently, these models achieved great performance on tasks such as compositional visual question answering, visual grounding, and video temporal reasoning. Nevertheless, in their current form, these models heavily rely on human engineering of in-context examples in the prompt, which are often dataset- and task-specific and require significant labor by highly skilled programmers. In this work, we present a framework that mitigates these issues by introducing spatially and temporally abstract routines and by leveraging a small number of labeled examples to automatically generate in-context examples, thereby avoiding human-created in-context examples. On a number of visual reasoning tasks, we show that our framework leads to consistent gains in performance, makes LLMs as controllers setup more robust, and removes the need for human engineering of in-context examples.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
VCT: A Video Compression Transformer
Jun 15, 2022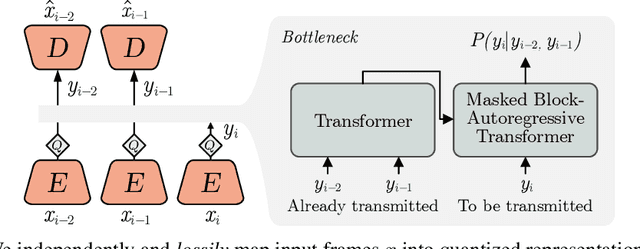

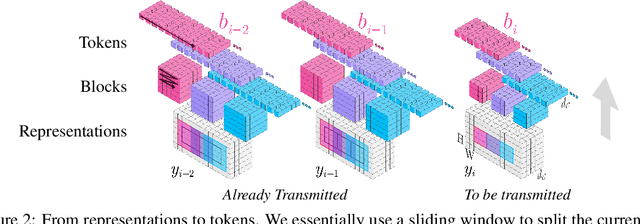
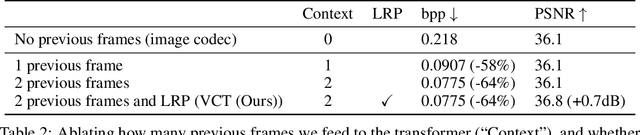
We show how transformers can be used to vastly simplify neural video compression. Previous methods have been relying on an increasing number of architectural biases and priors, including motion prediction and warping operations, resulting in complex models. Instead, we independently map input frames to representations and use a transformer to model their dependencies, letting it predict the distribution of future representations given the past. The resulting video compression transformer outperforms previous methods on standard video compression data sets. Experiments on synthetic data show that our model learns to handle complex motion patterns such as panning, blurring and fading purely from data. Our approach is easy to implement, and we release code to facilitate future research.
The 2019 DAVIS Challenge on VOS: Unsupervised Multi-Object Segmentation
May 02, 2019

We present the 2019 DAVIS Challenge on Video Object Segmentation, the third edition of the DAVIS Challenge series, a public competition designed for the task of Video Object Segmentation (VOS). In addition to the original semi-supervised track and the interactive track introduced in the previous edition, a new unsupervised multi-object track will be featured this year. In the newly introduced track, participants are asked to provide non-overlapping object proposals on each image, along with an identifier linking them between frames (i.e. video object proposals), without any test-time human supervision (no scribbles or masks provided on the test video). In order to do so, we have re-annotated the train and val sets of DAVIS 2017 in a concise way that facilitates the unsupervised track, and created new test-dev and test-challenge sets for the competition. Definitions, rules, and evaluation metrics for the unsupervised track are described in detail in this paper.
Fast video object segmentation with Spatio-Temporal GANs
Mar 28, 2019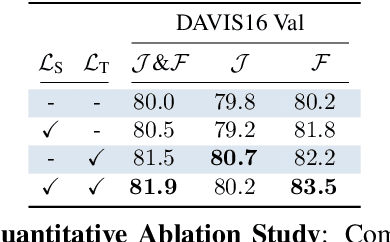
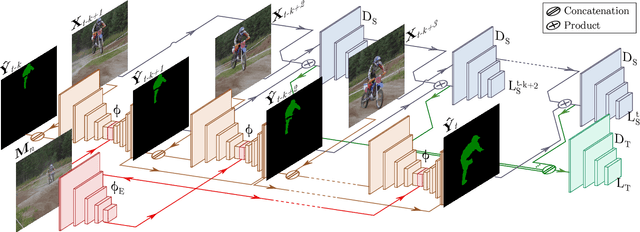

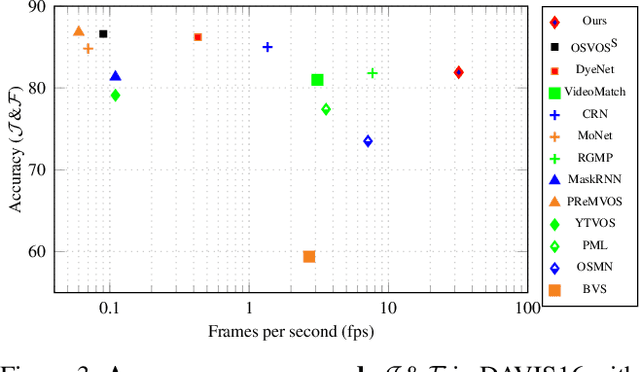
Learning descriptive spatio-temporal object models from data is paramount for the task of semi-supervised video object segmentation. Most existing approaches mainly rely on models that estimate the segmentation mask based on a reference mask at the first frame (aided sometimes by optical flow or the previous mask). These models, however, are prone to fail under rapid appearance changes or occlusions due to their limitations in modelling the temporal component. On the other hand, very recently, other approaches learned long-term features using a convolutional LSTM to leverage the information from all previous video frames. Even though these models achieve better temporal representations, they still have to be fine-tuned for every new video sequence. In this paper, we present an intermediate solution and devise a novel GAN architecture, FaSTGAN, to learn spatio-temporal object models over finite temporal windows. To achieve this, we concentrate all the heavy computational load to the training phase with two critics that enforce spatial and temporal mask consistency over the last K frames. Then at test time, we only use a relatively light regressor, which reduces the inference time considerably. As a result, our approach combines a high resiliency to sudden geometric and photometric object changes with efficiency at test time (no need for fine-tuning nor post-processing). We demonstrate that the accuracy of our method is on par with state-of-the-art techniques on the challenging YouTube-VOS and DAVIS datasets, while running at 32 fps, about 4x faster than the closest competitor.
Iterative Deep Learning for Road Topology Extraction
Aug 28, 2018
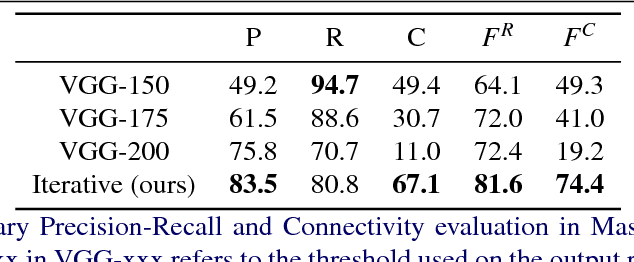

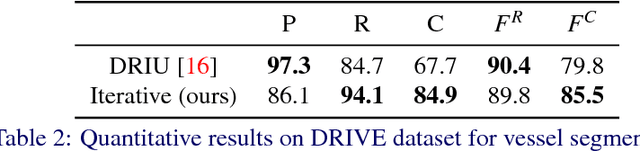
This paper tackles the task of estimating the topology of road networks from aerial images. Building on top of a global model that performs a dense semantical classification of the pixels of the image, we design a Convolutional Neural Network (CNN) that predicts the local connectivity among the central pixel of an input patch and its border points. By iterating this local connectivity we sweep the whole image and infer the global topology of the road network, inspired by a human delineating a complex network with the tip of their finger. We perform an extensive and comprehensive qualitative and quantitative evaluation on the road network estimation task, and show that our method also generalizes well when moving to networks of retinal vessels.
Semantically-Guided Video Object Segmentation
Jul 17, 2018
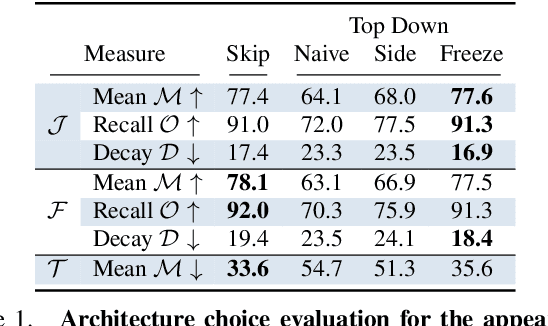
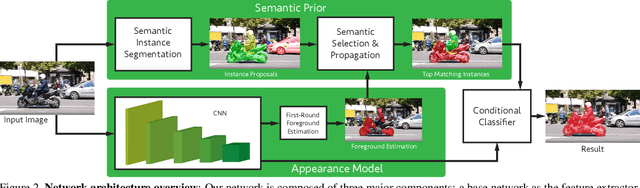
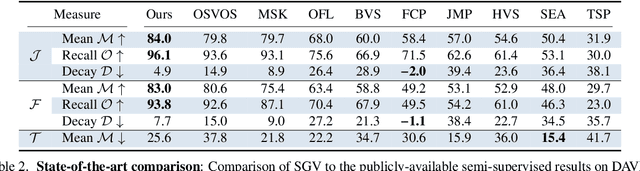
This paper tackles the problem of semi-supervised video object segmentation, that is, segmenting an object in a sequence given its mask in the first frame. One of the main challenges in this scenario is the change of appearance of the objects of interest. Their semantics, on the other hand, do not vary. This paper investigates how to take advantage of such invariance via the introduction of a semantic prior that guides the appearance model. Specifically, given the segmentation mask of the first frame of a sequence, we estimate the semantics of the object of interest, and propagate that knowledge throughout the sequence to improve the results based on an appearance model. We present Semantically-Guided Video Object Segmentation (SGV), which improves results over previous state of the art on two different datasets using a variety of evaluation metrics, while running in half a second per frame.
Video Object Segmentation Without Temporal Information
May 16, 2018
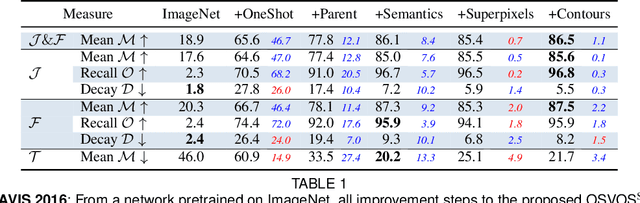
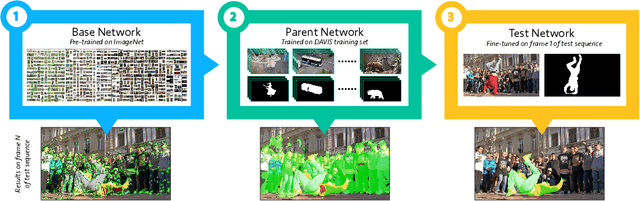
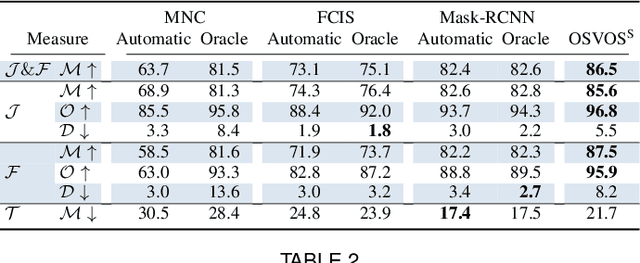
Video Object Segmentation, and video processing in general, has been historically dominated by methods that rely on the temporal consistency and redundancy in consecutive video frames. When the temporal smoothness is suddenly broken, such as when an object is occluded, or some frames are missing in a sequence, the result of these methods can deteriorate significantly or they may not even produce any result at all. This paper explores the orthogonal approach of processing each frame independently, i.e disregarding the temporal information. In particular, it tackles the task of semi-supervised video object segmentation: the separation of an object from the background in a video, given its mask in the first frame. We present Semantic One-Shot Video Object Segmentation (OSVOS-S), based on a fully-convolutional neural network architecture that is able to successively transfer generic semantic information, learned on ImageNet, to the task of foreground segmentation, and finally to learning the appearance of a single annotated object of the test sequence (hence one shot). We show that instance level semantic information, when combined effectively, can dramatically improve the results of our previous method, OSVOS. We perform experiments on two recent video segmentation databases, which show that OSVOS-S is both the fastest and most accurate method in the state of the art.
Deep Extreme Cut: From Extreme Points to Object Segmentation
Mar 27, 2018
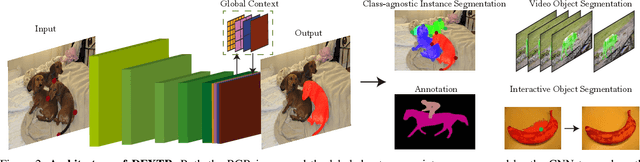
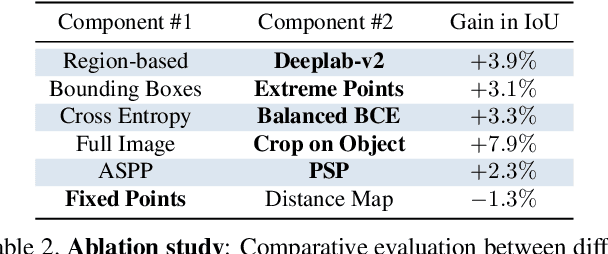
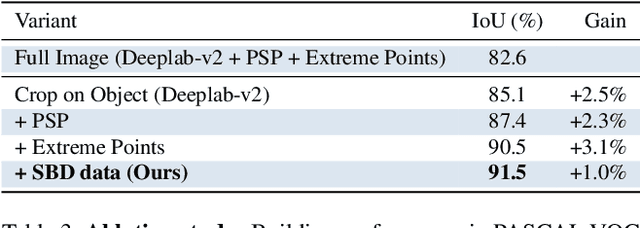
This paper explores the use of extreme points in an object (left-most, right-most, top, bottom pixels) as input to obtain precise object segmentation for images and videos. We do so by adding an extra channel to the image in the input of a convolutional neural network (CNN), which contains a Gaussian centered in each of the extreme points. The CNN learns to transform this information into a segmentation of an object that matches those extreme points. We demonstrate the usefulness of this approach for guided segmentation (grabcut-style), interactive segmentation, video object segmentation, and dense segmentation annotation. We show that we obtain the most precise results to date, also with less user input, in an extensive and varied selection of benchmarks and datasets. All our models and code are publicly available on http://www.vision.ee.ethz.ch/~cvlsegmentation/dextr/.