 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Layered Diffusion Model for One-Shot High Resolution Text-to-Image Synthesis
Jul 08, 2024



We present a one-shot text-to-image diffusion model that can generate high-resolution images from natural language descriptions. Our model employs a layered U-Net architecture that simultaneously synthesizes images at multiple resolution scales. We show that this method outperforms the baseline of synthesizing images only at the target resolution, while reducing the computational cost per step. We demonstrate that higher resolution synthesis can be achieved by layering convolutions at additional resolution scales, in contrast to other methods which require additional models for super-resolution synthesis.
Improving Multi-Agent Debate with Sparse Communication Topology
Jun 17, 2024Multi-agent debate has proven effective in improving large language models quality for reasoning and factuality tasks. While various role-playing strategies in multi-agent debates have been explored, in terms of the communication among agents, existing approaches adopt a brute force algorithm -- each agent can communicate with all other agents. In this paper, we systematically investigate the effect of communication connectivity in multi-agent systems. Our experiments on GPT and Mistral models reveal that multi-agent debates leveraging sparse communication topology can achieve comparable or superior performance while significantly reducing computational costs. Furthermore, we extend the multi-agent debate framework to multimodal reasoning and alignment labeling tasks, showcasing its broad applicability and effectiveness. Our findings underscore the importance of communication connectivity on enhancing the efficiency and effectiveness of the "society of minds" approach.
Greedy Growing Enables High-Resolution Pixel-Based Diffusion Models
May 27, 2024



We address the long-standing problem of how to learn effective pixel-based image diffusion models at scale, introducing a remarkably simple greedy growing method for stable training of large-scale, high-resolution models. without the needs for cascaded super-resolution components. The key insight stems from careful pre-training of core components, namely, those responsible for text-to-image alignment {\it vs.} high-resolution rendering. We first demonstrate the benefits of scaling a {\it Shallow UNet}, with no down(up)-sampling enc(dec)oder. Scaling its deep core layers is shown to improve alignment, object structure, and composition. Building on this core model, we propose a greedy algorithm that grows the architecture into high-resolution end-to-end models, while preserving the integrity of the pre-trained representation, stabilizing training, and reducing the need for large high-resolution datasets. This enables a single stage model capable of generating high-resolution images without the need of a super-resolution cascade. Our key results rely on public datasets and show that we are able to train non-cascaded models up to 8B parameters with no further regularization schemes. Vermeer, our full pipeline model trained with internal datasets to produce 1024x1024 images, without cascades, is preferred by 44.0% vs. 21.4% human evaluators over SDXL.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
MaskConver: Revisiting Pure Convolution Model for Panoptic Segmentation
Dec 11, 2023In recent years, transformer-based models have dominated panoptic segmentation, thanks to their strong modeling capabilities and their unified representation for both semantic and instance classes as global binary masks. In this paper, we revisit pure convolution model and propose a novel panoptic architecture named MaskConver. MaskConver proposes to fully unify things and stuff representation by predicting their centers. To that extent, it creates a lightweight class embedding module that can break the ties when multiple centers co-exist in the same location. Furthermore, our study shows that the decoder design is critical in ensuring that the model has sufficient context for accurate detection and segmentation. We introduce a powerful ConvNeXt-UNet decoder that closes the performance gap between convolution- and transformerbased models. With ResNet50 backbone, our MaskConver achieves 53.6% PQ on the COCO panoptic val set, outperforming the modern convolution-based model, Panoptic FCN, by 9.3% as well as transformer-based models such as Mask2Former (+1.7% PQ) and kMaX-DeepLab (+0.6% PQ). Additionally, MaskConver with a MobileNet backbone reaches 37.2% PQ, improving over Panoptic-DeepLab by +6.4% under the same FLOPs/latency constraints. A further optimized version of MaskConver achieves 29.7% PQ, while running in real-time on mobile devices. The code and model weights will be publicly available
Multimodal Open-Vocabulary Video Classification via Pre-Trained Vision and Language Models
Jul 15, 2022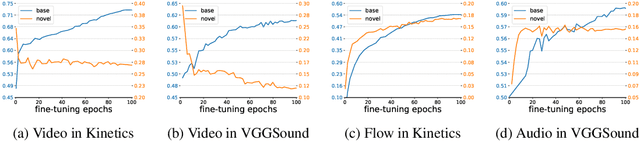
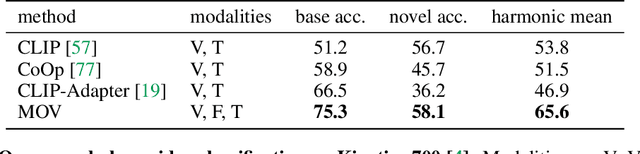
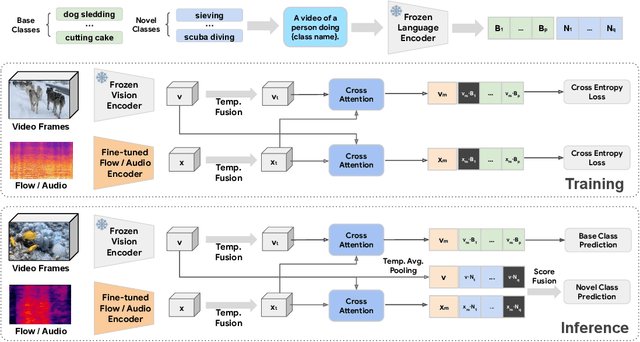
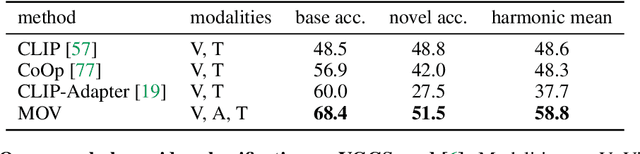
Utilizing vision and language models (VLMs) pre-trained on large-scale image-text pairs is becoming a promising paradigm for open-vocabulary visual recognition. In this work, we extend this paradigm by leveraging motion and audio that naturally exist in video. We present \textbf{MOV}, a simple yet effective method for \textbf{M}ultimodal \textbf{O}pen-\textbf{V}ocabulary video classification. In MOV, we directly use the vision encoder from pre-trained VLMs with minimal modifications to encode video, optical flow and audio spectrogram. We design a cross-modal fusion mechanism to aggregate complimentary multimodal information. Experiments on Kinetics-700 and VGGSound show that introducing flow or audio modality brings large performance gains over the pre-trained VLM and existing methods. Specifically, MOV greatly improves the accuracy on base classes, while generalizes better on novel classes. MOV achieves state-of-the-art results on UCF and HMDB zero-shot video classification benchmarks, significantly outperforming both traditional zero-shot methods and recent methods based on VLMs. Code and models will be released.
Exploring Temporal Granularity in Self-Supervised Video Representation Learning
Dec 08, 2021



This work presents a self-supervised learning framework named TeG to explore Temporal Granularity in learning video representations. In TeG, we sample a long clip from a video and a short clip that lies inside the long clip. We then extract their dense temporal embeddings. The training objective consists of two parts: a fine-grained temporal learning objective to maximize the similarity between corresponding temporal embeddings in the short clip and the long clip, and a persistent temporal learning objective to pull together global embeddings of the two clips. Our study reveals the impact of temporal granularity with three major findings. 1) Different video tasks may require features of different temporal granularities. 2) Intriguingly, some tasks that are widely considered to require temporal awareness can actually be well addressed by temporally persistent features. 3) The flexibility of TeG gives rise to state-of-the-art results on 8 video benchmarks, outperforming supervised pre-training in most cases.
Revisiting 3D ResNets for Video Recognition
Sep 03, 2021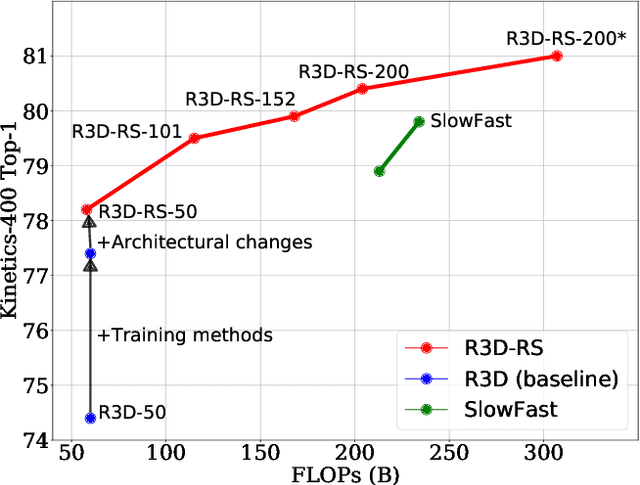
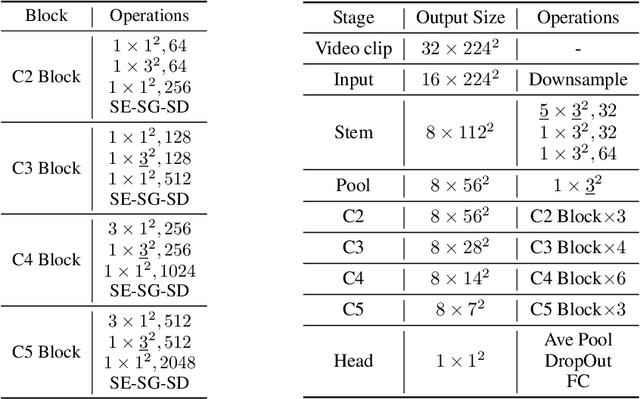
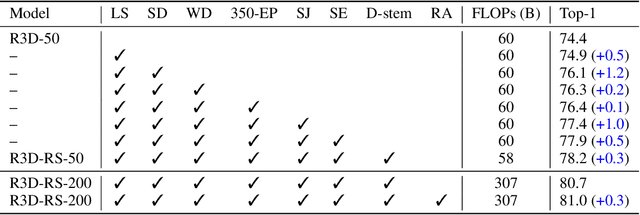
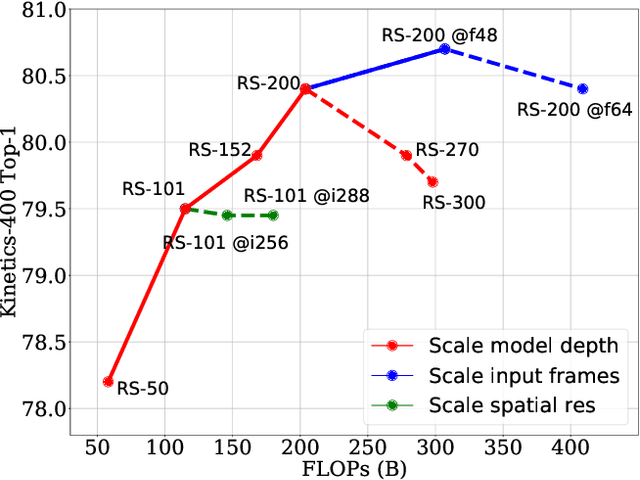
A recent work from Bello shows that training and scaling strategies may be more significant than model architectures for visual recognition. This short note studies effective training and scaling strategies for video recognition models. We propose a simple scaling strategy for 3D ResNets, in combination with improved training strategies and minor architectural changes. The resulting models, termed 3D ResNet-RS, attain competitive performance of 81.0 on Kinetics-400 and 83.8 on Kinetics-600 without pre-training. When pre-trained on a large Web Video Text dataset, our best model achieves 83.5 and 84.3 on Kinetics-400 and Kinetics-600. The proposed scaling rule is further evaluated in a self-supervised setup using contrastive learning, demonstrating improved performance. Code is available at: https://github.com/tensorflow/models/tree/master/official.
High Resolution Medical Image Analysis with Spatial Partitioning
Sep 12, 2019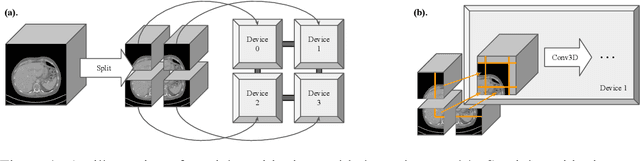
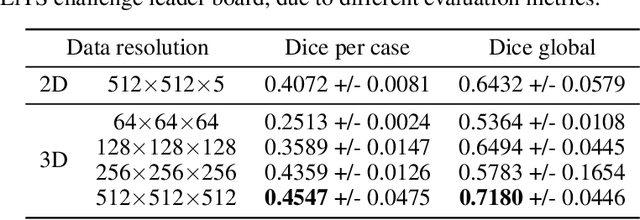

Medical images such as 3D computerized tomography (CT) scans and pathology images, have hundreds of millions or billions of voxels/pixels. It is infeasible to train CNN models directly on such high resolution images, because neural activations of a single image do not fit in the memory of a single GPU/TPU, and naive data and model parallelism approaches do not work. Existing image analysis approaches alleviate this problem by cropping or down-sampling input images, which leads to complicated implementation and sub-optimal performance due to information loss. In this paper, we implement spatial partitioning, which internally distributes the input and output of convolutional layers across GPUs/TPUs. Our implementation is based on the Mesh-TensorFlow framework and the computation distribution is transparent to end users. With this technique, we train a 3D Unet on up to 512 by 512 by 512 resolution data. To the best of our knowledge, this is the first work for handling such high resolution images end-to-end.