 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Conversational Medical AI with Eyes, Ears and a Voice
May 10, 2026The practice of medicine relies not only upon skillful dialogue but also on the nuanced exchange and interpretation of rich auditory and visual cues between doctors and patients. Building on the low-latency voice and video processing capabilities of Gemini, we introduce AI co-clinician, a first-of-its-kind conversational AI system utilizing continuous streams of audio-visual data from live patient conversations to inform real-time clinical decisions. Its dual-agent architecture balances deep clinical reasoning with the low latency required for natural dialogue. To assess this system, we implemented a video-based interface emulating telemedicine consultations. We crafted 20 standardized outpatient scenarios requiring proactive real-time auditory and visual reasoning and designed "TelePACES" evaluation criteria alongside case-specific rubrics. In a randomized, interface-blinded, crossover simulation study (n = 120 encounters) with 10 internal medicine residents as patient actors, we compared AI co-clinician with primary care physicians (PCPs), GPT-Realtime, and a baseline agent. AI co-clinician approached PCPs in key TelePACES dimensions, including management plans and differential diagnosis, while significantly outperforming GPT-Realtime across all general criteria. While our agent demonstrated parity with PCPs in case-specific triage measures, physicians maintained superior overall performance in case-specific assessments. Although AI co-clinician marks a significant advance in real-time telemedical AI, gaps remain in physical examination and disease-specific reasoning. Our work shows that text-only approaches fail to capture the true challenges of medical consultation and suggests that high-stakes real-time diagnostic AI is most safely advanced in collaborative, triadic models where AI can be a supportive co-clinician for doctors and patients.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
A Probabilistic U-Net for Segmentation of Ambiguous Images
Oct 29, 2018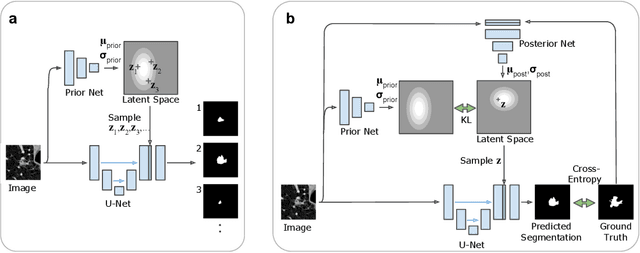

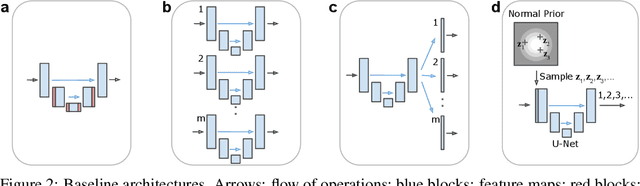

Many real-world vision problems suffer from inherent ambiguities. In clinical applications for example, it might not be clear from a CT scan alone which particular region is cancer tissue. Therefore a group of graders typically produces a set of diverse but plausible segmentations. We consider the task of learning a distribution over segmentations given an input. To this end we propose a generative segmentation model based on a combination of a U-Net with a conditional variational autoencoder that is capable of efficiently producing an unlimited number of plausible hypotheses. We show on a lung abnormalities segmentation task and on a Cityscapes segmentation task that our model reproduces the possible segmentation variants as well as the frequencies with which they occur, doing so significantly better than published approaches. These models could have a high impact in real-world applications, such as being used as clinical decision-making algorithms accounting for multiple plausible semantic segmentation hypotheses to provide possible diagnoses and recommend further actions to resolve the present ambiguities.
Deep learning to achieve clinically applicable segmentation of head and neck anatomy for radiotherapy
Sep 12, 2018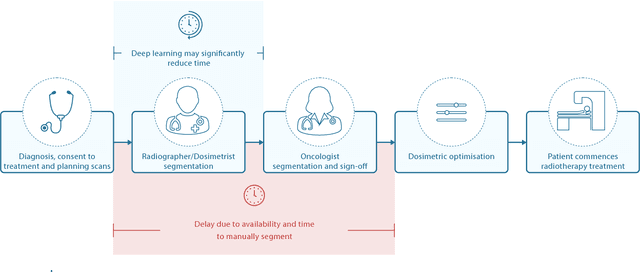
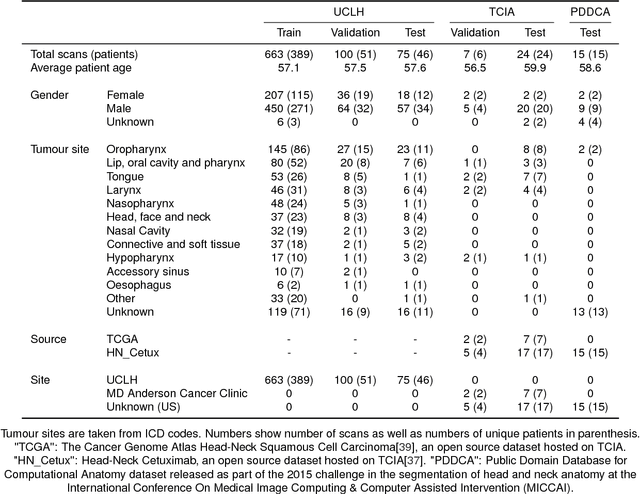
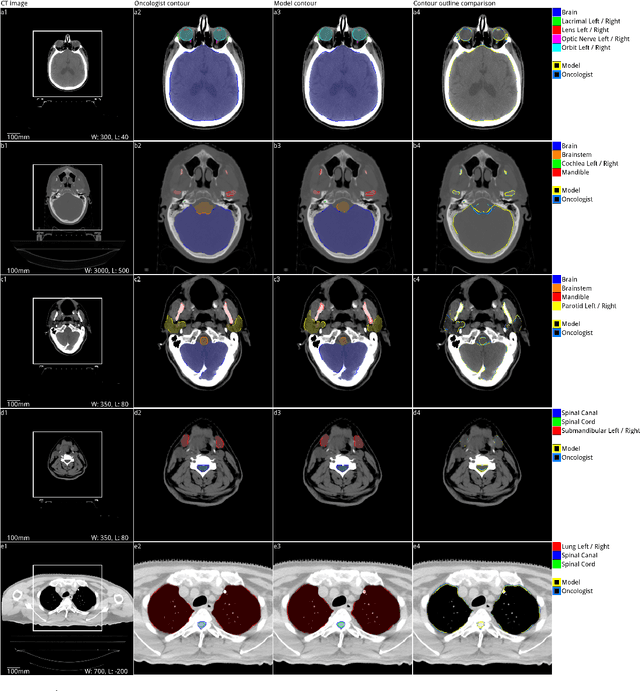
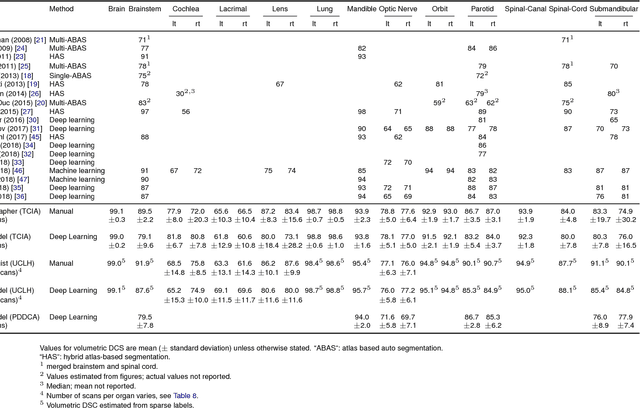
Over half a million individuals are diagnosed with head and neck cancer each year worldwide. Radiotherapy is an important curative treatment for this disease, but it requires manually intensive delineation of radiosensitive organs at risk (OARs). This planning process can delay treatment commencement. While auto-segmentation algorithms offer a potentially time-saving solution, the challenges in defining, quantifying and achieving expert performance remain. Adopting a deep learning approach, we demonstrate a 3D U-Net architecture that achieves performance similar to experts in delineating a wide range of head and neck OARs. The model was trained on a dataset of 663 deidentified computed tomography (CT) scans acquired in routine clinical practice and segmented according to consensus OAR definitions. We demonstrate its generalisability through application to an independent test set of 24 CT scans available from The Cancer Imaging Archive collected at multiple international sites previously unseen to the model, each segmented by two independent experts and consisting of 21 OARs commonly segmented in clinical practice. With appropriate validation studies and regulatory approvals, this system could improve the effectiveness of radiotherapy pathways.