 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecFed: Accelerating Federated LLM Inference with Speculative Decoding and Compressed Transmission
Apr 28, 2026Federated inference enhances LLM performance in edge computing through weighted averaging of distributed model predictions. However, autoregressive LLM inference requires frequent full-model forward passes across workers, severely limiting decoding throughput. Distributed deployment further aggravates this due to a communication bottleneck: each worker must transmit full token probability distributions per draft token, dominating end-to-end latency. To address these challenges, we introduce speculative decoding to enable parallel LLM processing and propose a top-K compressed transmission scheme with two server-side reconstruction strategies. We theoretically analyze the robustness of our method in terms of local reconstruction error, aggregation bias, and acceptance-rate bias, and derive corresponding bounds. Experiments demonstrate that our scheme achieves high generation fidelity while significantly reducing communication overhead.
Low-Latency Edge LLM Handover via Joint KV Cache Transfer and Token Prefill
Mar 30, 2026Edge deployment of large language models (LLMs) can reduce latency for interactive services, but mobility introduces service interruptions when an user equipment (UE) hands over between base stations (BSs). To promptly resume decoding, the target-side edge server must recover the UE context state, which can be provisioned either by token forwarding followed by prefill computation or by direct key-value (KV) cache transmission over backhaul. This paper proposes a unified handover (HO) design that jointly selects the prefill length and schedules backhaul KV cache delivery to minimize the worst-user LLM HO delay for multiple UEs. The resulting scheme admits a tractable step-wise solution with explicit feasibility conditions and a constructive rate-scheduling policy. Simulations show that the proposed method consistently outperforms baselines across a wide range of backhaul capacities, prefill speeds, and context sizes, providing practical guidelines for mobility-aware Edge LLM token streaming.
OnlineHMR: Video-based Online World-Grounded Human Mesh Recovery
Mar 18, 2026Human mesh recovery (HMR) models 3D human body from monocular videos, with recent works extending it to world-coordinate human trajectory and motion reconstruction. However, most existing methods remain offline, relying on future frames or global optimization, which limits their applicability in interactive feedback and perception-action loop scenarios such as AR/VR and telepresence. To address this, we propose OnlineHMR, a fully online framework that jointly satisfies four essential criteria of online processing, including system-level causality, faithfulness, temporal consistency, and efficiency. Built upon a two-branch architecture, OnlineHMR enables streaming inference via a causal key-value cache design and a curated sliding-window learning strategy. Meanwhile, a human-centric incremental SLAM provides online world-grounded alignment under physically plausible trajectory correction. Experimental results show that our method achieves performance comparable to existing chunk-based approaches on the standard EMDB benchmark and highly dynamic custom videos, while uniquely supporting online processing. Page and code are available at https://tsukasane.github.io/Video-OnlineHMR/.
Clustering-Based User Selection in Federated Learning: Metadata Exploitation for 3GPP Networks
Jan 15, 2026Federated learning (FL) enables collaborative model training without sharing raw user data, but conventional simulations often rely on unrealistic data partitioning and current user selection methods ignore data correlation among users. To address these challenges, this paper proposes a metadatadriven FL framework. We first introduce a novel data partition model based on a homogeneous Poisson point process (HPPP), capturing both heterogeneity in data quantity and natural overlap among user datasets. Building on this model, we develop a clustering-based user selection strategy that leverages metadata, such as user location, to reduce data correlation and enhance label diversity across training rounds. Extensive experiments on FMNIST and CIFAR-10 demonstrate that the proposed framework improves model performance, stability, and convergence in non-IID scenarios, while maintaining comparable performance under IID settings. Furthermore, the method shows pronounced advantages when the number of selected users per round is small. These findings highlight the framework's potential for enhancing FL performance in realistic deployments and guiding future standardization.
Fast Collaborative Inference via Distributed Speculative Decoding
Dec 18, 2025Speculative decoding accelerates large language model (LLM) inference by allowing a small draft model to predict multiple future tokens for verification by a larger target model. In AI-native radio access networks (AI-RAN), this enables device-edge collaborative inference but introduces significant uplink overhead, as existing distributed speculative decoding schemes transmit full vocabulary logits at every step. We propose a sparsify-then-sample strategy, Truncated Sparse Logits Transmission (TSLT), which transmits only the logits and indices of a truncated candidate set. We provide theoretical guarantees showing that the acceptance rate is preserved under TSLT. TSLT is further extended to multi-candidate case, where multiple draft candidates per step increase acceptance probability. Experiments show that TSLT significantly reduces uplink communication while maintaining end-to-end inference latency and model quality, demonstrating its effectiveness for scalable, communication-efficient distributed LLM inference in future AI-RAN systems.
Communication-Efficient Collaborative LLM Inference via Distributed Speculative Decoding
Sep 04, 2025



Speculative decoding is an emerging technique that accelerates large language model (LLM) inference by allowing a smaller draft model to predict multiple tokens in advance, which are then verified or corrected by a larger target model. In AI-native radio access networks (AI-RAN), this paradigm is well-suited for collaborative inference between resource-constrained end devices and more capable edge servers or base stations (BSs). However, existing distributed speculative decoding requires transmitting the full vocabulary probability distribution from the draft model on the device to the target model at the BS, which leads to prohibitive uplink communication overhead. To address this issue, we propose a ``Top-K Sparse Logits Transmission (TK-SLT)`` scheme, where the draft model transmits only the top-K token raw probabilities and the corresponding token indices instead of the entire distribution. This approach significantly reduces bandwidth consumption while maintaining inference performance. We further derive an analytical expression for the optimal draft length that maximizes inference throughput, and provide a theoretical analysis of the achievable speedup ratio under TK-SLT. Experimental results validate both the efficiency and effectiveness of the proposed method.
DSSD: Efficient Edge-Device Deployment and Collaborative Inference via Distributed Split Speculative Decoding
Jul 16, 2025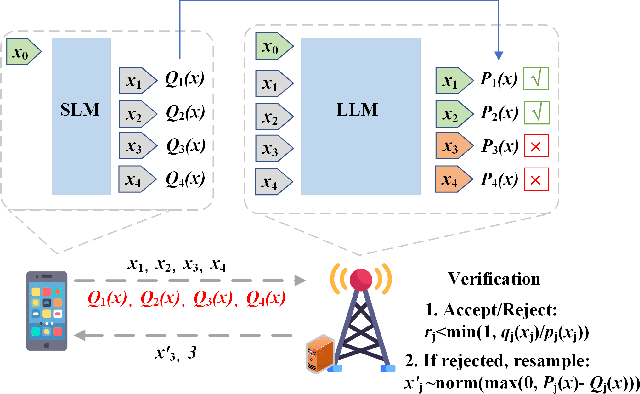
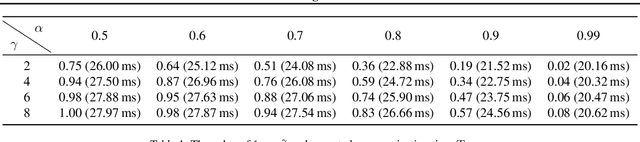
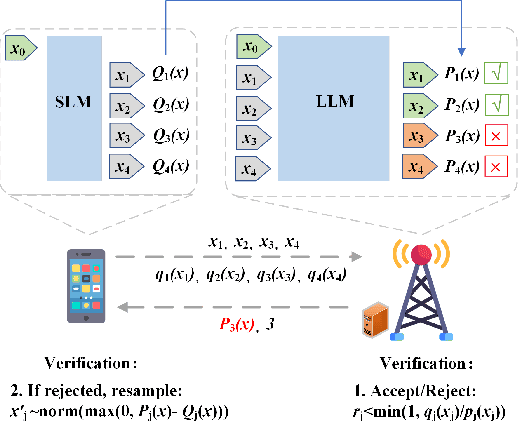
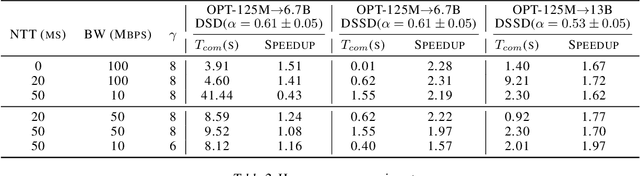
Large language models (LLMs) have transformed natural language processing but face critical deployment challenges in device-edge systems due to resource limitations and communication overhead. To address these issues, collaborative frameworks have emerged that combine small language models (SLMs) on devices with LLMs at the edge, using speculative decoding (SD) to improve efficiency. However, existing solutions often trade inference accuracy for latency or suffer from high uplink transmission costs when verifying candidate tokens. In this paper, we propose Distributed Split Speculative Decoding (DSSD), a novel architecture that not only preserves the SLM-LLM split but also partitions the verification phase between the device and edge. In this way, DSSD replaces the uplink transmission of multiple vocabulary distributions with a single downlink transmission, significantly reducing communication latency while maintaining inference quality. Experiments show that our solution outperforms current methods, and codes are at: https://github.com/JasonNing96/DSSD-Efficient-Edge-Computing
EdgePrompt: A Distributed Key-Value Inference Framework for LLMs in 6G Networks
Apr 16, 2025As sixth-generation (6G) networks advance, large language models (LLMs) are increasingly integrated into 6G infrastructure to enhance network management and intelligence. However, traditional LLMs architecture struggle to meet the stringent latency and security requirements of 6G, especially as the increasing in sequence length leads to greater task complexity. This paper proposes Edge-Prompt, a cloud-edge collaborative framework based on a hierarchical attention splicing mechanism. EdgePrompt employs distributed key-value (KV) pair optimization techniques to accelerate inference and adapt to network conditions. Additionally, to reduce the risk of data leakage, EdgePrompt incorporates a privacy preserving strategy by isolating sensitive information during processing. Experiments on public dataset show that EdgePrompt effectively improves the inference throughput and reduces the latency, which provides a reliable solution for LLMs deployment in 6G environments.
MAVERIX: Multimodal Audio-Visual Evaluation Reasoning IndeX
Mar 27, 2025



Frontier models have either been language-only or have primarily focused on vision and language modalities. Although recent advancements in models with vision and audio understanding capabilities have shown substantial progress, the field lacks a standardized evaluation framework for thoroughly assessing their cross-modality perception performance. We introduce MAVERIX~(Multimodal Audio-Visual Evaluation Reasoning IndeX), a novel benchmark with 700 videos and 2,556 questions explicitly designed to evaluate multimodal models through tasks that necessitate close integration of video and audio information. MAVERIX uniquely provides models with audiovisual tasks, closely mimicking the multimodal perceptual experiences available to humans during inference and decision-making processes. To our knowledge, MAVERIX is the first benchmark aimed explicitly at assessing comprehensive audiovisual integration. Experiments with state-of-the-art models, including Gemini 1.5 Pro and o1, show performance approaching human levels (around 70% accuracy), while human experts reach near-ceiling performance (95.1%). With standardized evaluation protocols, a rigorously annotated pipeline, and a public toolkit, MAVERIX establishes a challenging testbed for advancing audiovisual multimodal intelligence.
Exploiting Aggregation and Segregation of Representations for Domain Adaptive Human Pose Estimation
Dec 29, 2024Human pose estimation (HPE) has received increasing attention recently due to its wide application in motion analysis, virtual reality, healthcare, etc. However, it suffers from the lack of labeled diverse real-world datasets due to the time- and labor-intensive annotation. To cope with the label deficiency issue, one common solution is to train the HPE models with easily available synthetic datasets (source) and apply them to real-world data (target) through domain adaptation (DA). Unfortunately, prevailing domain adaptation techniques within the HPE domain remain predominantly fixated on effecting alignment and aggregation between source and target features, often sidestepping the crucial task of excluding domain-specific representations. To rectify this, we introduce a novel framework that capitalizes on both representation aggregation and segregation for domain adaptive human pose estimation. Within this framework, we address the network architecture aspect by disentangling representations into distinct domain-invariant and domain-specific components, facilitating aggregation of domain-invariant features while simultaneously segregating domain-specific ones. Moreover, we tackle the discrepancy measurement facet by delving into various keypoint relationships and applying separate aggregation or segregation mechanisms to enhance alignment. Extensive experiments on various benchmarks, e.g., Human3.6M, LSP, H3D, and FreiHand, show that our method consistently achieves state-of-the-art performance. The project is available at \url{https://github.com/davidpengucf/EPIC}.