 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Technical Report on the CleverHans v2.1.0 Adversarial Examples Library
Jun 27, 2018CleverHans is a software library that provides standardized reference implementations of adversarial example construction techniques and adversarial training. The library may be used to develop more robust machine learning models and to provide standardized benchmarks of models' performance in the adversarial setting. Benchmarks constructed without a standardized implementation of adversarial example construction are not comparable to each other, because a good result may indicate a robust model or it may merely indicate a weak implementation of the adversarial example construction procedure. This technical report is structured as follows. Section 1 provides an overview of adversarial examples in machine learning and of the CleverHans software. Section 2 presents the core functionalities of the library: namely the attacks based on adversarial examples and defenses to improve the robustness of machine learning models to these attacks. Section 3 describes how to report benchmark results using the library. Section 4 describes the versioning system.
Conditional Adversarial Network for Semantic Segmentation of Brain Tumor
Aug 17, 2017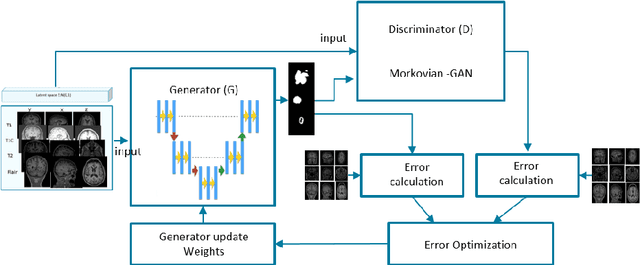
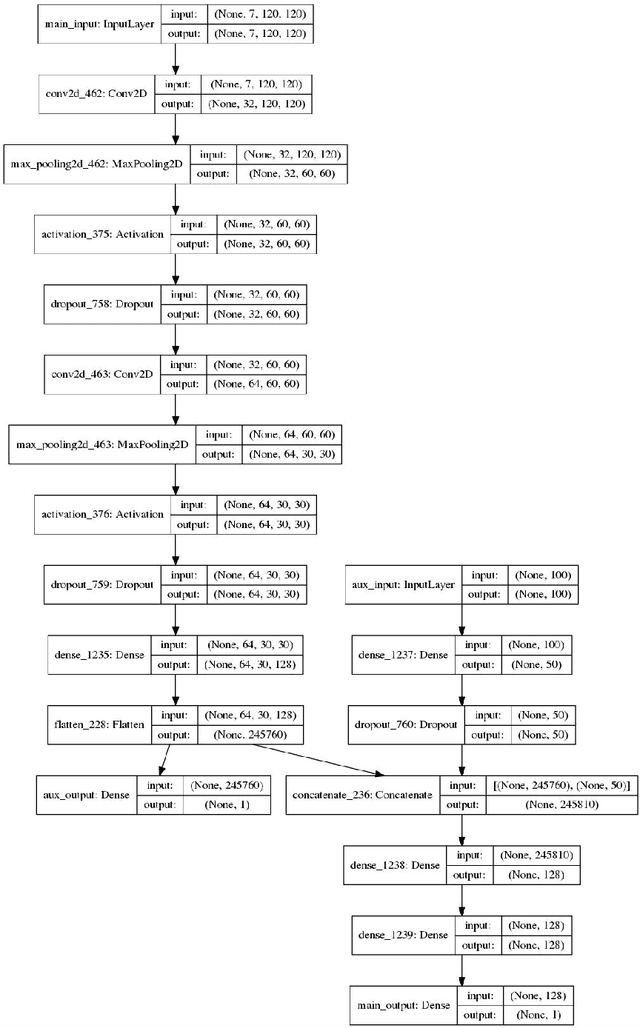

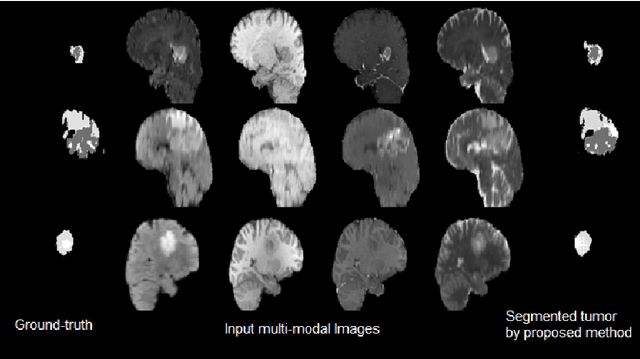
Automated medical image analysis has a significant value in diagnosis and treatment of lesions. Brain tumors segmentation has a special importance and difficulty due to the difference in appearances and shapes of the different tumor regions in magnetic resonance images. Additionally, the data sets are heterogeneous and usually limited in size in comparison with the computer vision problems. The recently proposed adversarial training has shown promising results in generative image modeling. In this paper, we propose a novel end-to-end trainable architecture for brain tumor semantic segmentation through conditional adversarial training. We exploit conditional Generative Adversarial Network (cGAN) and train a semantic segmentation Convolution Neural Network (CNN) along with an adversarial network that discriminates segmentation maps coming from the ground truth or from the segmentation network for BraTS 2017 segmentation task[15, 4, 2, 3]. We also propose an end-to-end trainable CNN for survival day prediction based on deep learning techniques for BraTS 2017 prediction task [15, 4, 2, 3]. The experimental results demonstrate the superior ability of the proposed approach for both tasks. The proposed model achieves on validation data a DICE score, Sensitivity and Specificity respectively 0.68, 0.99 and 0.98 for the whole tumor, regarding online judgment system.