 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegalDrill: Diagnosis-Driven Synthesis for Legal Reasoning in Small Language Models
Apr 26, 2026Small language models (SLMs) are promising for real-world deployment due to their efficiency and low operational cost. However, their limited capacity struggles with high-stakes legal reasoning tasks that require coherent statute interpretation and logically consistent deduction. Furthermore, training SLMs for such tasks demands high-quality, concise reasoning trajectories, which are prohibitively expensive to manually collect and difficult to curate via standard rejection sampling, lacking granularity beyond final verdicts. To address these challenges, we propose {LegalDrill}, a diagnosis-driven synthesis framework that extracts and iteratively refines reasoning trajectories from a capable teacher via fine-grained prompting, then a self-reflective verification is employed to adaptively select the most effective data for the SLM student. The resulting data empower SLM training through supervised fine-tuning and direct preference optimization. Extensive experiments on several legal benchmarks demonstrate that {LegalDrill} significantly bolsters the legal reasoning capabilities of representative SLMs while bypassing the need for scarce expert annotations, paving a scalable path toward practical legal reasoning systems.
SpatialFly: Geometry-Guided Representation Alignment for UAV Vision-and-Language Navigation in Urban Environments
Mar 22, 2026UAVs play an important role in applications such as autonomous exploration, disaster response, and infrastructure inspection. However, UAV VLN in complex 3D environments remains challenging. A key difficulty is the structural representation mismatch between 2D visual perception and the 3D trajectory decision space, which limits spatial reasoning. To this end, we propose SpatialFly, a geometry-guided spatial representation framework for UAV VLN. Operating on RGB observations without explicit 3D reconstruction, SpatialFly introduces a geometry-guided 2D representation alignment mechanism. Specifically, the geometric prior injection module injects global structural cues into 2D semantic tokens to provide scene-level geometric guidance. The geometry-aware reparameterization module then aligns 2D semantic tokens with 3D geometric tokens through cross-modal attention, followed by gated residual fusion to preserve semantic discrimination. Experimental results show that SpatialFly consistently outperforms state-of-the-art UAV VLN baselines across both seen and unseen environments, reducing NE by 4.03m and improving SR by 1.27% over the strongest baseline on the unseen Full split. Additional trajectory-level analysis shows that SpatialFly produces trajectories with better path alignment and smoother, more stable motion.
Deep Tabular Representation Corrector
Mar 17, 2026Tabular data have been playing a mostly important role in diverse real-world fields, such as healthcare, engineering, finance, etc. The recent success of deep learning has fostered many deep networks (e.g., Transformer, ResNet) based tabular learning methods. Generally, existing deep tabular machine learning methods are along with the two paradigms, i.e., in-learning and pre-learning. In-learning methods need to train networks from scratch or impose extra constraints to regulate the representations which nonetheless train multiple tasks simultaneously and make learning more difficult, while pre-learning methods design several pretext tasks for pre-training and then conduct task-specific fine-tuning, which however need much extra training effort with prior knowledge. In this paper, we introduce a novel deep Tabular Representation Corrector, TRC, to enhance any trained deep tabular model's representations without altering its parameters in a model-agnostic manner. Specifically, targeting the representation shift and representation redundancy that hinder prediction, we propose two tasks, i.e., (i) Tabular Representation Re-estimation, that involves training a shift estimator to calculate the inherent shift of tabular representations to subsequently mitigate it, thereby re-estimating the representations and (ii) Tabular Space Mapping, that transforms the above re-estimated representations into a light-embedding vector space via a coordinate estimator while preserves crucial predictive information to minimize redundancy. The two tasks jointly enhance the representations of deep tabular models without touching on the original models thus enjoying high efficiency. Finally, we conduct extensive experiments on state-of-the-art deep tabular machine learning models coupled with TRC on various tabular benchmarks which have shown consistent superiority.
Flexible Multi-Target Angular Emulation for Over-the-Air Testing of Large-Scale ISAC Base Stations: Principle and Experimental Verification
Mar 11, 2026Over-the-air (OTA) emulation of diverse sensing target characteristics in a controlled laboratory environment is pivotal for advancing integrated sensing and communication (ISAC) technology, as it facilitates the non-invasive performance evaluation of ISAC base stations (BSs) across complex scenarios. In this work, a flexible multi-target OTA emulation framework based on a wireless cable method is proposed to evaluate the sensing performance of large-scale ISAC BSs. The core concept leverages an amplitude and phase modulation (APM) network to simultaneously establish wireless cables and simulate target spatial characteristics without consuming additional resources on costly radar target emulators. For the wireless cable method, the condition number increases as the number of antennas scales up, which affects the performance of the wireless cable. Although the wireless cable concept has been established for devices-under-test (DUTs) with a limited number of antenna ports, establishing wireless cables for large-scale DUTs remains an open question in the community. We address this problem by optimizing the OTA probe array configuration based on the theoretical properties of strictly diagonally dominant matrices. Experimental results validate the proposed framework, demonstrating high-isolation wireless cables for a 32-element DUT and an extremely low condition number for a 128-element synthetic array. Furthermore, the OTA emulation of a dynamic dual-drone scenario confirms the method's effectiveness and practicality in reproducing complex sensing environments.
Robust and Efficient Tool Orchestration via Layered Execution Structures with Reflective Correction
Feb 21, 2026Tool invocation is a core capability of agentic systems, yet failures often arise not from individual tool calls but from how multiple tools are organized and executed together. Existing approaches tightly couple tool execution with stepwise language reasoning or explicit planning, leading to brittle behavior and high execution overhead. To overcome these limitations, we revisit tool invocation from the perspective of tool orchestration. Our key insight is that effective orchestration does not require precise dependency graphs or fine-grained planning. Instead, a coarse-grained layer structure suffices to provide global guidance, while execution-time errors can be corrected locally. Specifically, we model tool orchestration as learning a layered execution structure that captures high-level tool dependencies, inducing layer-wise execution through context constraints. To handle execution-time failures, we introduce a schema-aware reflective correction mechanism that detects and repairs errors locally. This design confines errors to individual tool calls and avoids re-planning entire execution trajectories. This structured execution paradigm enables a lightweight and reusable orchestration component for agentic systems. Experimental results show that our approach achieves robust tool execution while reducing execution complexity and overhead. Code will be made publicly available.
Do VLMs Have a Moral Backbone? A Study on the Fragile Morality of Vision-Language Models
Jan 23, 2026Despite substantial efforts toward improving the moral alignment of Vision-Language Models (VLMs), it remains unclear whether their ethical judgments are stable in realistic settings. This work studies moral robustness in VLMs, defined as the ability to preserve moral judgments under textual and visual perturbations that do not alter the underlying moral context. We systematically probe VLMs with a diverse set of model-agnostic multimodal perturbations and find that their moral stances are highly fragile, frequently flipping under simple manipulations. Our analysis reveals systematic vulnerabilities across perturbation types, moral domains, and model scales, including a sycophancy trade-off where stronger instruction-following models are more susceptible to persuasion. We further show that lightweight inference-time interventions can partially restore moral stability. These results demonstrate that moral alignment alone is insufficient and that moral robustness is a necessary criterion for the responsible deployment of VLMs.
AppellateGen: A Benchmark for Appellate Legal Judgment Generation
Jan 08, 2026Legal judgment generation is a critical task in legal intelligence. However, existing research in legal judgment generation has predominantly focused on first-instance trials, relying on static fact-to-verdict mappings while neglecting the dialectical nature of appellate (second-instance) review. To address this, we introduce AppellateGen, a benchmark for second-instance legal judgment generation comprising 7,351 case pairs. The task requires models to draft legally binding judgments by reasoning over the initial verdict and evidentiary updates, thereby modeling the causal dependency between trial stages. We further propose a judicial Standard Operating Procedure (SOP)-based Legal Multi-Agent System (SLMAS) to simulate judicial workflows, which decomposes the generation process into discrete stages of issue identification, retrieval, and drafting. Experimental results indicate that while SLMAS improves logical consistency, the complexity of appellate reasoning remains a substantial challenge for current LLMs. The dataset and code are publicly available at: https://anonymous.4open.science/r/AppellateGen-5763.
LongFly: Long-Horizon UAV Vision-and-Language Navigation with Spatiotemporal Context Integration
Dec 26, 2025Unmanned aerial vehicles (UAVs) are crucial tools for post-disaster search and rescue, facing challenges such as high information density, rapid changes in viewpoint, and dynamic structures, especially in long-horizon navigation. However, current UAV vision-and-language navigation(VLN) methods struggle to model long-horizon spatiotemporal context in complex environments, resulting in inaccurate semantic alignment and unstable path planning. To this end, we propose LongFly, a spatiotemporal context modeling framework for long-horizon UAV VLN. LongFly proposes a history-aware spatiotemporal modeling strategy that transforms fragmented and redundant historical data into structured, compact, and expressive representations. First, we propose the slot-based historical image compression module, which dynamically distills multi-view historical observations into fixed-length contextual representations. Then, the spatiotemporal trajectory encoding module is introduced to capture the temporal dynamics and spatial structure of UAV trajectories. Finally, to integrate existing spatiotemporal context with current observations, we design the prompt-guided multimodal integration module to support time-based reasoning and robust waypoint prediction. Experimental results demonstrate that LongFly outperforms state-of-the-art UAV VLN baselines by 7.89\% in success rate and 6.33\% in success weighted by path length, consistently across both seen and unseen environments.
MTP: Exploring Multimodal Urban Traffic Profiling with Modality Augmentation and Spectrum Fusion
Nov 17, 2025With rapid urbanization in the modern era, traffic signals from various sensors have been playing a significant role in monitoring the states of cities, which provides a strong foundation in ensuring safe travel, reducing traffic congestion and optimizing urban mobility. Most existing methods for traffic signal modeling often rely on the original data modality, i.e., numerical direct readings from the sensors in cities. However, this unimodal approach overlooks the semantic information existing in multimodal heterogeneous urban data in different perspectives, which hinders a comprehensive understanding of traffic signals and limits the accurate prediction of complex traffic dynamics. To address this problem, we propose a novel Multimodal framework, MTP, for urban Traffic Profiling, which learns multimodal features through numeric, visual, and textual perspectives. The three branches drive for a multimodal perspective of urban traffic signal learning in the frequency domain, while the frequency learning strategies delicately refine the information for extraction. Specifically, we first conduct the visual augmentation for the traffic signals, which transforms the original modality into frequency images and periodicity images for visual learning. Also, we augment descriptive texts for the traffic signals based on the specific topic, background information and item description for textual learning. To complement the numeric information, we utilize frequency multilayer perceptrons for learning on the original modality. We design a hierarchical contrastive learning on the three branches to fuse the spectrum of three modalities. Finally, extensive experiments on six real-world datasets demonstrate superior performance compared with the state-of-the-art approaches.
iMAD: Intelligent Multi-Agent Debate for Efficient and Accurate LLM Inference
Nov 14, 2025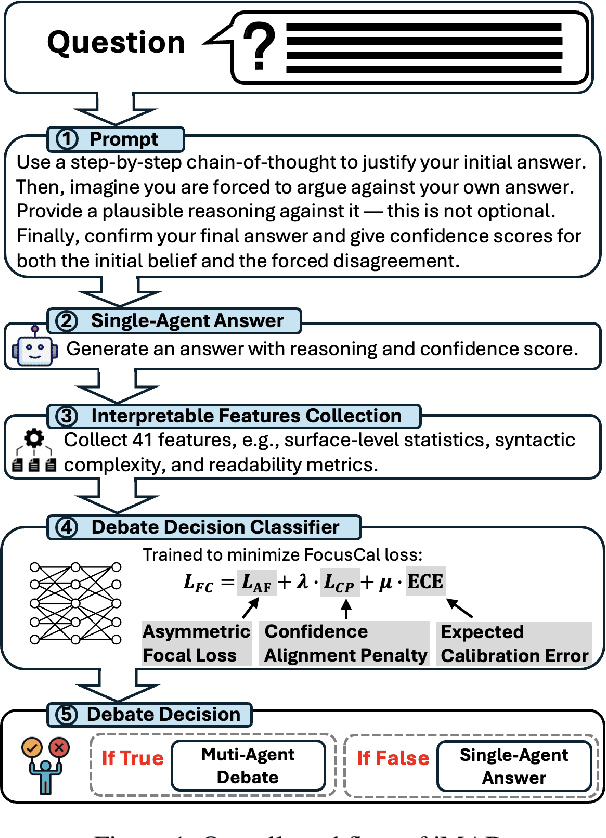
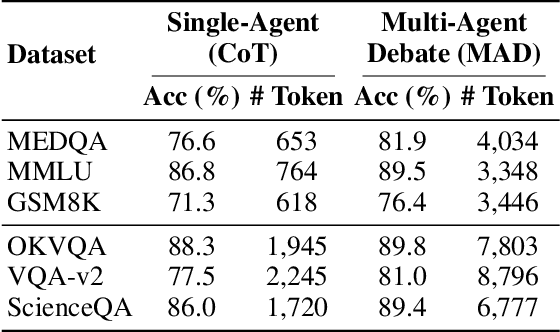
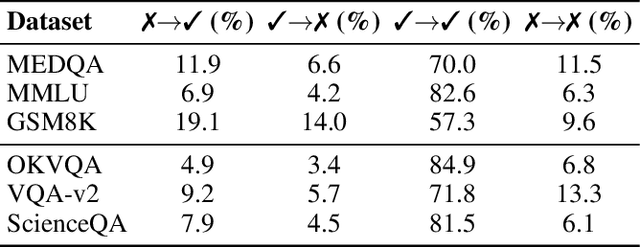
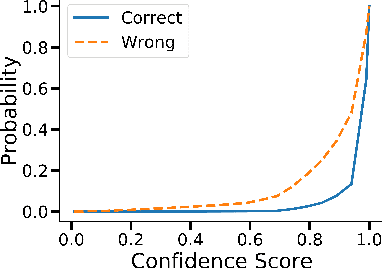
Large Language Model (LLM) agent systems have advanced rapidly, driven by their strong generalization in zero-shot settings. To further enhance reasoning and accuracy on complex tasks, Multi-Agent Debate (MAD) has emerged as a promising framework that engages multiple LLM agents in structured debates to encourage diverse reasoning. However, triggering MAD for every query is inefficient, as it incurs substantial computational (token) cost and may even degrade accuracy by overturning correct single-agent answers. To address these limitations, we propose intelligent Multi-Agent Debate (iMAD), a token-efficient framework that selectively triggers MAD only when it is likely to be beneficial (i.e., correcting an initially wrong answer). To achieve this goal, iMAD learns generalizable model behaviors to make accurate debate decisions. Specifically, iMAD first prompts a single agent to produce a structured self-critique response, from which we extract 41 interpretable linguistic and semantic features capturing hesitation cues. Then, iMAD uses a lightweight debate-decision classifier, trained using our proposed FocusCal loss, to determine whether to trigger MAD, enabling robust debate decisions without test dataset-specific tuning. Through extensive experiments using six (visual) question answering datasets against five competitive baselines, we have shown that iMAD significantly reduces token usage (by up to 92%) while also improving final answer accuracy (by up to 13.5%).