 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColoring the Noise: Adversarial Sobolev Alignment for Faithful Image Super Resolution
May 22, 2026Generative priors in Image Super-Resolution (SR) often compromise faithful restoration, we attribute this limitation to a fundamental spectral misalignment between isotropic objectives and the intrinsic natural image manifold. While Direct Preference Optimization offers a path to alignment, its reliance on spectrally flat Gaussian noise fails to distinguish authentic high-frequency details from hallucinations. To bridge this geometric gap, we propose ASASR, a theoretically grounded framework that recasts the generative flow into a Sobolev-induced Riemannian geometry by explicitly coloring the noise transition kernel to mirror natural spectral decay. Driving this geometric alignment, we integrate a parametric adversary grounded in the Riesz Representation Theorem, which synthesizes targeted negative samples equivalent to worst-case Sobolev gradients to direct optimization along the tangent space of plausible structural failures. Extensive evaluations demonstrate that ASASR outperforms leading generative baselines, particularly in preserving spectral consistency and structural fidelity, offering a robust solution that effectively mitigates artifacts.
Tuning Real-World Image Restoration at Inference: A Test-Time Scaling Paradigm for Flow Matching Models
Mar 23, 2026Although diffusion-based real-world image restoration (Real-IR) has achieved remarkable progress, efficiently leveraging ultra-large-scale pre-trained text-to-image (T2I) models and fully exploiting their potential remain significant challenges. To address this issue, we propose ResFlow-Tuner, an image restoration framework based on the state-of-the-art flow matching model, FLUX.1-dev, which integrates unified multi-modal fusion (UMMF) with test-time scaling (TTS) to achieve unprecedented restoration performance. Our approach fully leverages the advantages of the Multi-Modal Diffusion Transformer (MM-DiT) architecture by encoding multi-modal conditions into a unified sequence that guides the synthesis of high-quality images. Furthermore, we introduce a training-free test-time scaling paradigm tailored for image restoration. During inference, this technique dynamically steers the denoising direction through feedback from a reward model (RM), thereby achieving significant performance gains with controllable computational overhead. Extensive experiments demonstrate that our method achieves state-of-the-art performance across multiple standard benchmarks. This work not only validates the powerful capabilities of the flow matching model in low-level vision tasks but, more importantly, proposes a novel and efficient inference-time scaling paradigm suitable for large pre-trained models.
YAYI 2: Multilingual Open-Source Large Language Models
Dec 22, 2023As the latest advancements in natural language processing, large language models (LLMs) have achieved human-level language understanding and generation abilities in many real-world tasks, and even have been regarded as a potential path to the artificial general intelligence. To better facilitate research on LLMs, many open-source LLMs, such as Llama 2 and Falcon, have recently been proposed and gained comparable performances to proprietary models. However, these models are primarily designed for English scenarios and exhibit poor performances in Chinese contexts. In this technical report, we propose YAYI 2, including both base and chat models, with 30 billion parameters. YAYI 2 is pre-trained from scratch on a multilingual corpus which contains 2.65 trillion tokens filtered by our pre-training data processing pipeline. The base model is aligned with human values through supervised fine-tuning with millions of instructions and reinforcement learning from human feedback. Extensive experiments on multiple benchmarks, such as MMLU and CMMLU, consistently demonstrate that the proposed YAYI 2 outperforms other similar sized open-source models.
Overlapping oriented imbalanced ensemble learning method based on projective clustering and stagewise hybrid sampling
Nov 30, 2022



The challenge of imbalanced learning lies not only in class imbalance problem, but also in the class overlapping problem which is complex. However, most of the existing algorithms mainly focus on the former. The limitation prevents the existing methods from breaking through. To address this limitation, this paper proposes an ensemble learning algorithm based on dual clustering and stage-wise hybrid sampling (DCSHS). The DCSHS has three parts. Firstly, we design a projection clustering combination framework (PCC) guided by Davies-Bouldin clustering effectiveness index (DBI), which is used to obtain high-quality clusters and combine them to obtain a set of cross-complete subsets (CCS) with balanced class and low overlapping. Secondly, according to the characteristics of subset classes, a stage-wise hybrid sampling algorithm is designed to realize the de-overlapping and balancing of subsets. Finally, a projective clustering transfer mapping mechanism (CTM) is constructed for all processed subsets by means of transfer learning, thereby reducing class overlapping and explore structure information of samples. The major advantage of our algorithm is that it can exploit the intersectionality of the CCS to realize the soft elimination of overlapping majority samples, and learn as much information of overlapping samples as possible, thereby enhancing the class overlapping while class balancing. In the experimental section, more than 30 public datasets and over ten representative algorithms are chosen for verification. The experimental results show that the DCSHS is significantly best in terms of various evaluation criteria.
A new Stack Autoencoder: Neighbouring Sample Envelope Embedded Stack Autoencoder Ensemble Model
Oct 25, 2022



Stack autoencoder (SAE), as a representative deep network, has unique and excellent performance in feature learning, and has received extensive attention from researchers. However, existing deep SAEs focus on original samples without considering the hierarchical structural information between samples. To address this limitation, this paper proposes a new SAE model-neighbouring envelope embedded stack autoencoder ensemble (NE_ESAE). Firstly, the neighbouring sample envelope learning mechanism (NSELM) is proposed for preprocessing of input of SAE. NSELM constructs sample pairs by combining neighbouring samples. Besides, the NSELM constructs a multilayer sample spaces by multilayer iterative mean clustering, which considers the similar samples and generates layers of envelope samples with hierarchical structural information. Second, an embedded stack autoencoder (ESAE) is proposed and trained in each layer of sample space to consider the original samples during training and in the network structure, thereby better finding the relationship between original feature samples and deep feature samples. Third, feature reduction and base classifiers are conducted on the layers of envelope samples respectively, and output classification results of every layer of samples. Finally, the classification results of the layers of envelope sample space are fused through the ensemble mechanism. In the experimental section, the proposed algorithm is validated with over ten representative public datasets. The results show that our method significantly has better performance than existing traditional feature learning methods and the representative deep autoencoders.
Envelope imbalanced ensemble model with deep sample learning and local-global structure consistency
Jun 25, 2022

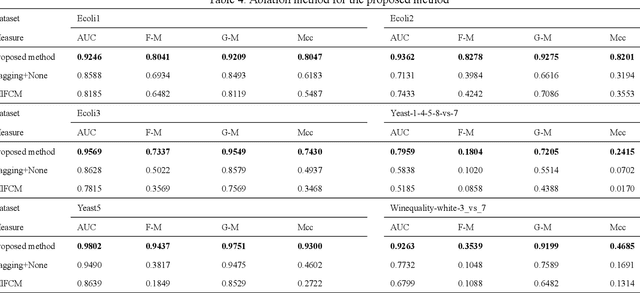
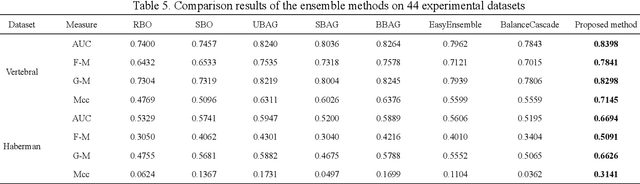
The class imbalance problem is important and challenging. Ensemble approaches are widely used to tackle this problem because of their effectiveness. However, existing ensemble methods are always applied into original samples, while not considering the structure information among original samples. The limitation will prevent the imbalanced learning from being better. Besides, research shows that the structure information among samples includes local and global structure information. Based on the analysis above, an imbalanced ensemble algorithm with the deep sample pre-envelope network (DSEN) and local-global structure consistency mechanism (LGSCM) is proposed here to solve the problem.This algorithm can guarantee high-quality deep envelope samples for considering the local manifold and global structures information, which is helpful for imbalance learning. First, the deep sample envelope pre-network (DSEN) is designed to mine structure information among samples.Then, the local manifold structure metric (LMSM) and global structure distribution metric (GSDM) are designed to construct LGSCM to enhance distribution consistency of interlayer samples. Next, the DSEN and LGSCM are put together to form the final deep sample envelope network (DSEN-LG). After that, base classifiers are applied on the layers of deep samples respectively.Finally, the predictive results from base classifiers are fused through bagging ensemble learning mechanism. To demonstrate the effectiveness of the proposed method, forty-four public datasets and more than ten representative relevant algorithms are chosen for verification. The experimental results show that the algorithm is significantly better than other imbalanced ensemble algorithms.
Subject Enveloped Deep Sample Fuzzy Ensemble Learning Algorithm of Parkinson's Speech Data
Nov 17, 2021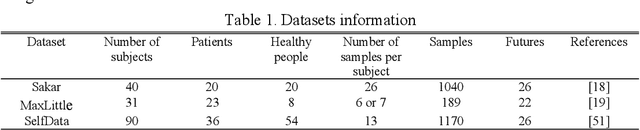
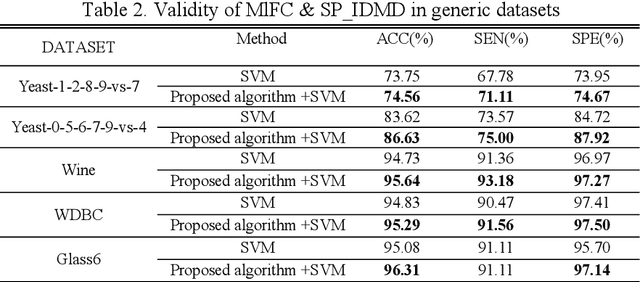

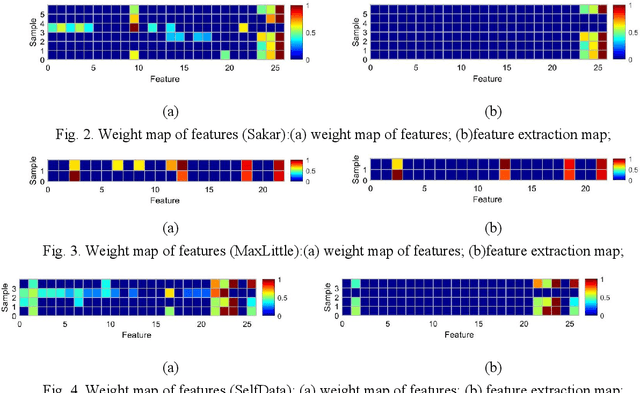
Parkinson disease (PD)'s speech recognition is an effective way for its diagnosis, which has become a hot and difficult research area in recent years. As we know, there are large corpuses (segments) within one subject. However, too large segments will increase the complexity of the classification model. Besides, the clinicians interested in finding diagnostic speech markers that reflect the pathology of the whole subject. Since the optimal relevant features of each speech sample segment are different, it is difficult to find the uniform diagnostic speech markers. Therefore, it is necessary to reconstruct the existing large segments within one subject into few segments even one segment within one subject, which can facilitate the extraction of relevant speech features to characterize diagnostic markers for the whole subject. To address this problem, an enveloped deep speech sample learning algorithm for Parkinson's subjects based on multilayer fuzzy c-mean (MlFCM) clustering and interlayer consistency preservation is proposed in this paper. The algorithm can be used to achieve intra-subject sample reconstruction for Parkinson's disease (PD) to obtain a small number of high-quality prototype sample segments. At the end of the paper, several representative PD speech datasets are selected and compared with the state-of-the-art related methods, respectively. The experimental results show that the proposed algorithm is effective signifcantly.
Envelope Imbalance Learning Algorithm based on Multilayer Fuzzy C-means Clustering and Minimum Interlayer discrepancy
Nov 02, 2021

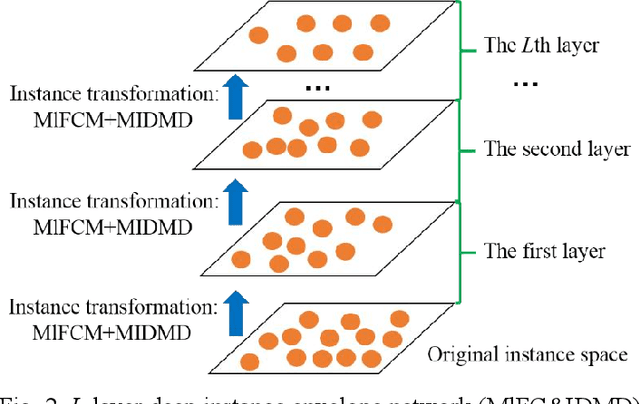
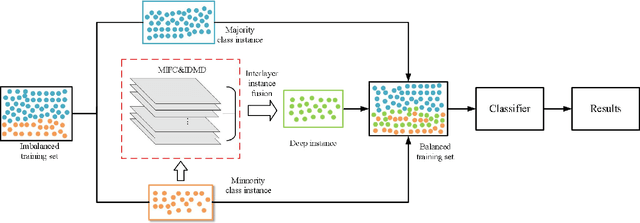
Imbalanced learning is important and challenging since the problem of the classification of imbalanced datasets is prevalent in machine learning and data mining fields. Sampling approaches are proposed to address this issue, and cluster-based oversampling methods have shown great potential as they aim to simultaneously tackle between-class and within-class imbalance issues. However, all existing clustering methods are based on a one-time approach. Due to the lack of a priori knowledge, improper setting of the number of clusters often exists, which leads to poor clustering performance. Besides, the existing methods are likely to generate noisy instances. To solve these problems, this paper proposes a deep instance envelope network-based imbalanced learning algorithm with the multilayer fuzzy c-means (MlFCM) and a minimum interlayer discrepancy mechanism based on the maximum mean discrepancy (MIDMD). This algorithm can guarantee high quality balanced instances using a deep instance envelope network in the absence of prior knowledge. In the experimental section, thirty-three popular public datasets are used for verification, and over ten representative algorithms are used for comparison. The experimental results show that the proposed approach significantly outperforms other popular methods.
Subject Envelope based Multitype Reconstruction Algorithm of Speech Samples of Parkinson's Disease
Aug 23, 2021



The risk of Parkinson's disease (PD) is extremely serious, and PD speech recognition is an effective method of diagnosis nowadays. However, due to the influence of the disease stage, corpus, and other factors on data collection, the ability of every samples within one subject to reflect the status of PD vary. No samples are useless totally, and not samples are 100% perfect. This characteristic means that it is not suitable just to remove some samples or keep some samples. It is necessary to consider the sample transformation for obtaining high quality new samples. Unfortunately, existing PD speech recognition methods focus mainly on feature learning and classifier design rather than sample learning, and few methods consider the sample transformation. To solve the problem above, a PD speech sample transformation algorithm based on multitype reconstruction operators is proposed in this paper. The algorithm is divided into four major steps. Three types of reconstruction operators are designed in the algorithm: types A, B and C. Concerning the type A operator, the original dataset is directly reconstructed by designing a linear transformation to obtain the first dataset. The type B operator is designed for clustering and linear transformation of the dataset to obtain the second new dataset. The third operator, namely, the type C operator, reconstructs the dataset by clustering and convolution to obtain the third dataset. Finally, the base classifier is trained based on the three new datasets, and then the classification results are fused by decision weighting. In the experimental section, two representative PD speech datasets are used for verification. The results show that the proposed algorithm is effective. Compared with other algorithms, the proposed algorithm achieves apparent improvements in terms of classification accuracy.
FA-GAN: Fused Attentive Generative Adversarial Networks for MRI Image Super-Resolution
Aug 09, 2021


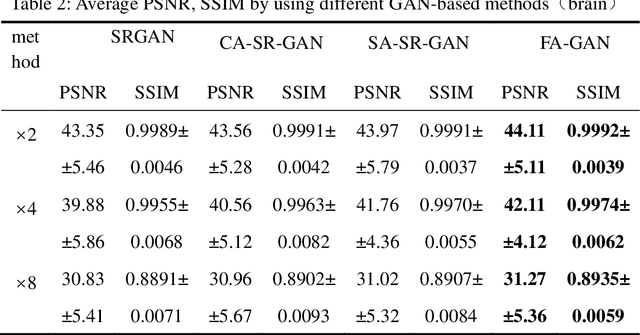
High-resolution magnetic resonance images can provide fine-grained anatomical information, but acquiring such data requires a long scanning time. In this paper, a framework called the Fused Attentive Generative Adversarial Networks(FA-GAN) is proposed to generate the super-resolution MR image from low-resolution magnetic resonance images, which can reduce the scanning time effectively but with high resolution MR images. In the framework of the FA-GAN, the local fusion feature block, consisting of different three-pass networks by using different convolution kernels, is proposed to extract image features at different scales. And the global feature fusion module, including the channel attention module, the self-attention module, and the fusion operation, is designed to enhance the important features of the MR image. Moreover, the spectral normalization process is introduced to make the discriminator network stable. 40 sets of 3D magnetic resonance images (each set of images contains 256 slices) are used to train the network, and 10 sets of images are used to test the proposed method. The experimental results show that the PSNR and SSIM values of the super-resolution magnetic resonance image generated by the proposed FA-GAN method are higher than the state-of-the-art reconstruction methods.