 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Graph Posterior Sampling for Nonlinear Inverse Problems with Application to Electrical Impedance Tomography
May 19, 2026Deep generative models have emerged as state-of-the-art for solving inverse problems, but applying them to inverse problems for PDEs, like electrical impedance tomography (EIT) remains challenging. Because physical domains are naturally discretized as unstructured meshes rather than regular grids, standard convolutional architectures are often inadequate. In this paper, we propose a novel framework that extends diffusion posterior sampling (DPS) to graph-structured data. We develop an unconditional score-based diffusion model directly on a 2D triangular mesh to learn an accurate prior over the physical solution space. Furthermore, we introduce a regularized variant, RDPS, which incorporates explicit regularization terms, such as total variation and generalized Tikhonov, to complement the implicit diffusion prior and mitigate severe ill-posedness. Extensive experiments on synthetic and real 2D EIT datasets demonstrate that RDPS produces stable, physically plausible reconstructions. Our approach generalizes well to out-of-distribution inclusion geometries, is highly robust to measurement noise, and outperforms current state-of-the-art solvers (e.g., GPnP-BM3D, DP-SGS) in reconstruction accuracy and artifact reduction.
UniDial-EvalKit: A Unified Toolkit for Evaluating Multi-Faceted Conversational Abilities
Mar 24, 2026Benchmarking AI systems in multi-turn interactive scenarios is essential for understanding their practical capabilities in real-world applications. However, existing evaluation protocols are highly heterogeneous, differing significantly in dataset formats, model interfaces, and evaluation pipelines, which severely impedes systematic comparison. In this work, we present UniDial-EvalKit (UDE), a unified evaluation toolkit for assessing interactive AI systems. The core contribution of UDE lies in its holistic unification: it standardizes heterogeneous data formats into a universal schema, streamlines complex evaluation pipelines through a modular architecture, and aligns metric calculations under a consistent scoring interface. It also supports efficient large-scale evaluation through parallel generation and scoring, as well as checkpoint-based caching to eliminate redundant computation. Validated across diverse multi-turn benchmarks, UDE not only guarantees high reproducibility through standardized workflows and transparent logging, but also significantly improves evaluation efficiency and extensibility. We make the complete toolkit and evaluation scripts publicly available to foster a standardized benchmarking ecosystem and accelerate future breakthroughs in interactive AI.
LifeEval: A Multimodal Benchmark for Assistive AI in Egocentric Daily Life Tasks
Feb 28, 2026The rapid progress of Multimodal Large Language Models (MLLMs) marks a significant step toward artificial general intelligence, offering great potential for augmenting human capabilities. However, their ability to provide effective assistance in dynamic, real-world environments remains largely underexplored. Existing video benchmarks predominantly assess passive understanding through retrospective analysis or isolated perception tasks, failing to capture the interactive and adaptive nature of real-time user assistance. To bridge this gap, we introduce LifeEval, a multimodal benchmark designed to evaluate real-time, task-oriented human-AI collaboration in daily life from an egocentric perspective. LifeEval emphasizes three key aspects: task-oriented holistic evaluation, egocentric real-time perception from continuous first-person streams, and human-assistant collaborative interaction through natural dialogues. Constructed via a rigorous annotation pipeline, the benchmark comprises 4,075 high-quality question-answer pairs across 6 core capability dimensions. Extensive evaluations of 26 state-of-the-art MLLMs on LifeEval reveal substantial challenges in achieving timely, effective and adaptive interaction, highlighting essential directions for advancing human-centered interactive intelligence.
MagicHOI: Leveraging 3D Priors for Accurate Hand-object Reconstruction from Short Monocular Video Clips
Aug 07, 2025



Most RGB-based hand-object reconstruction methods rely on object templates, while template-free methods typically assume full object visibility. This assumption often breaks in real-world settings, where fixed camera viewpoints and static grips leave parts of the object unobserved, resulting in implausible reconstructions. To overcome this, we present MagicHOI, a method for reconstructing hands and objects from short monocular interaction videos, even under limited viewpoint variation. Our key insight is that, despite the scarcity of paired 3D hand-object data, large-scale novel view synthesis diffusion models offer rich object supervision. This supervision serves as a prior to regularize unseen object regions during hand interactions. Leveraging this insight, we integrate a novel view synthesis model into our hand-object reconstruction framework. We further align hand to object by incorporating visible contact constraints. Our results demonstrate that MagicHOI significantly outperforms existing state-of-the-art hand-object reconstruction methods. We also show that novel view synthesis diffusion priors effectively regularize unseen object regions, enhancing 3D hand-object reconstruction.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
N-Grammer: Augmenting Transformers with latent n-grams
Jul 13, 2022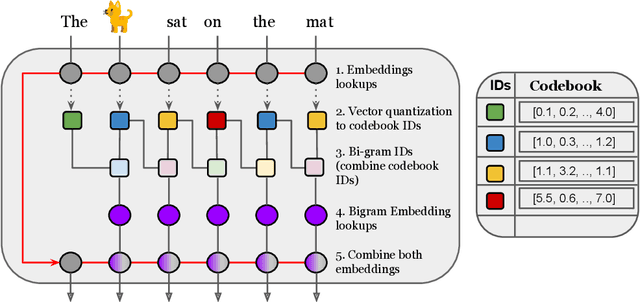
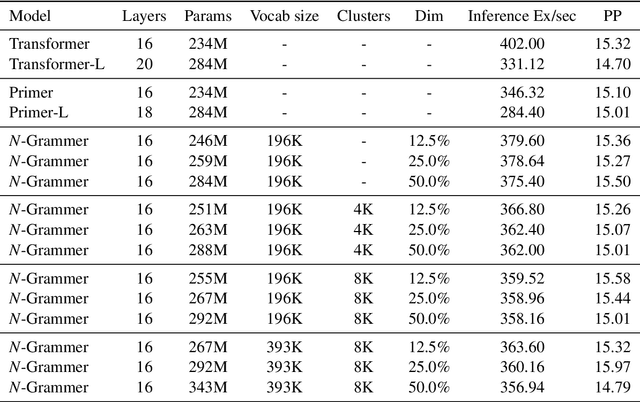

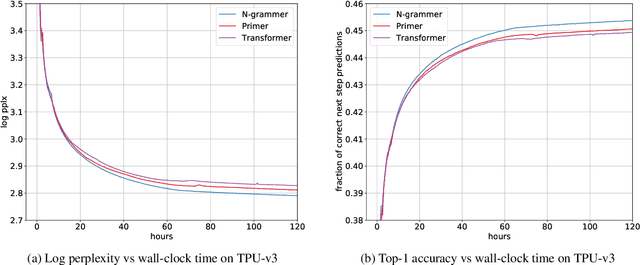
Transformer models have recently emerged as one of the foundational models in natural language processing, and as a byproduct, there is significant recent interest and investment in scaling these models. However, the training and inference costs of these large Transformer language models are prohibitive, thus necessitating more research in identifying more efficient variants. In this work, we propose a simple yet effective modification to the Transformer architecture inspired by the literature in statistical language modeling, by augmenting the model with n-grams that are constructed from a discrete latent representation of the text sequence. We evaluate our model, the N-Grammer on language modeling on the C4 data-set as well as text classification on the SuperGLUE data-set, and find that it outperforms several strong baselines such as the Transformer and the Primer. We open-source our model for reproducibility purposes in Jax.
BigSSL: Exploring the Frontier of Large-Scale Semi-Supervised Learning for Automatic Speech Recognition
Oct 01, 2021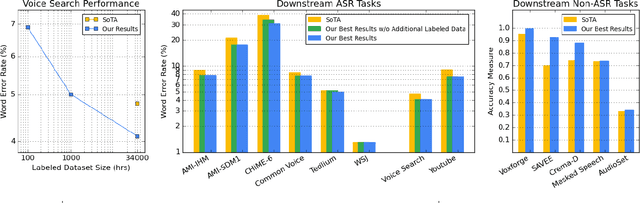
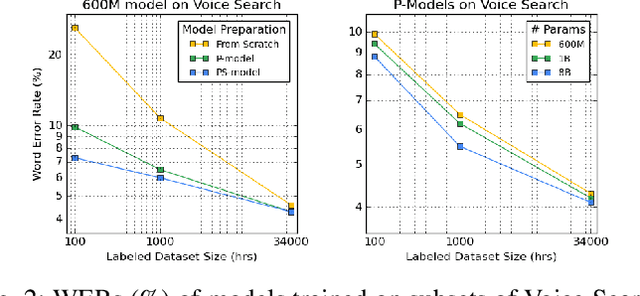
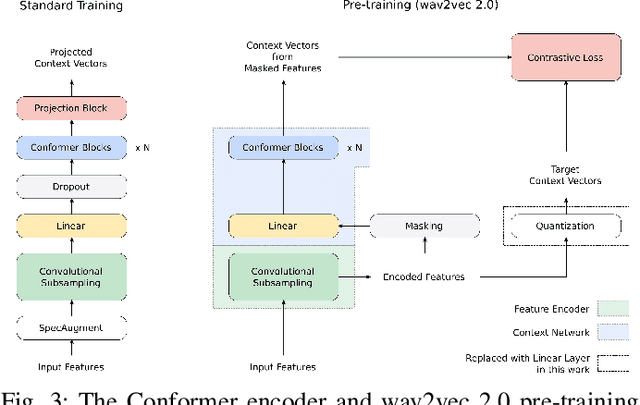
We summarize the results of a host of efforts using giant automatic speech recognition (ASR) models pre-trained using large, diverse unlabeled datasets containing approximately a million hours of audio. We find that the combination of pre-training, self-training and scaling up model size greatly increases data efficiency, even for extremely large tasks with tens of thousands of hours of labeled data. In particular, on an ASR task with 34k hours of labeled data, by fine-tuning an 8 billion parameter pre-trained Conformer model we can match state-of-the-art (SoTA) performance with only 3% of the training data and significantly improve SoTA with the full training set. We also report on the universal benefits gained from using big pre-trained and self-trained models for a large set of downstream tasks that cover a wide range of speech domains and span multiple orders of magnitudes of dataset sizes, including obtaining SoTA performance on many public benchmarks. In addition, we utilize the learned representation of pre-trained networks to achieve SoTA results on non-ASR tasks.
GSPMD: General and Scalable Parallelization for ML Computation Graphs
May 10, 2021

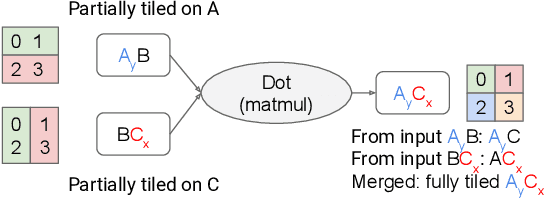
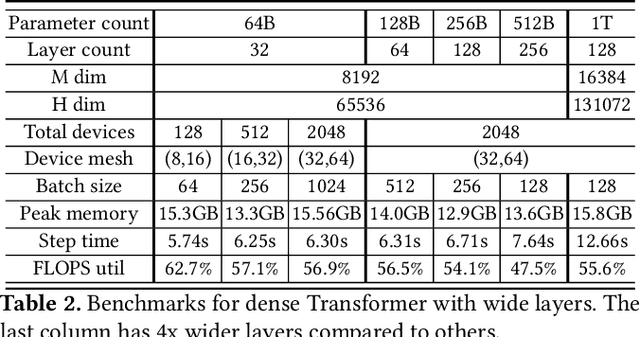
We present GSPMD, an automatic, compiler-based parallelization system for common machine learning computation graphs. It allows users to write programs in the same way as for a single device, then give hints through a few annotations on how to distribute tensors, based on which GSPMD will parallelize the computation. Its representation of partitioning is simple yet general, allowing it to express different or mixed paradigms of parallelism on a wide variety of models. GSPMD infers the partitioning for every operator in the graph based on limited user annotations, making it convenient to scale up existing single-device programs. It solves several technical challenges for production usage, such as static shape constraints, uneven partitioning, exchange of halo data, and nested operator partitioning. These techniques allow GSPMD to achieve 50% to 62% compute utilization on 128 to 2048 Cloud TPUv3 cores for models with up to one trillion parameters. GSPMD produces a single program for all devices, which adjusts its behavior based on a run-time partition ID, and uses collective operators for cross-device communication. This property allows the system itself to be scalable: the compilation time stays constant with increasing number of devices.
Exploring the limits of Concurrency in ML Training on Google TPUs
Nov 07, 2020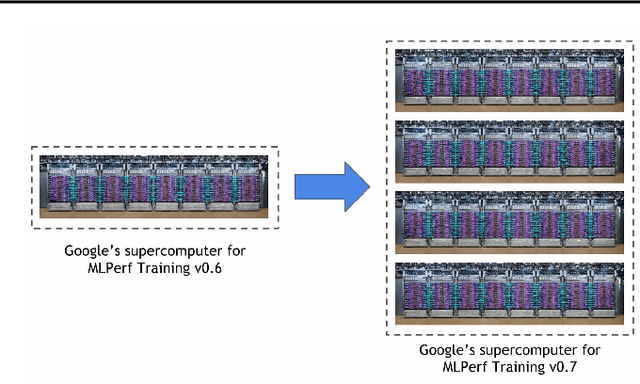
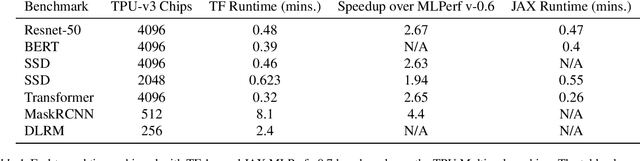
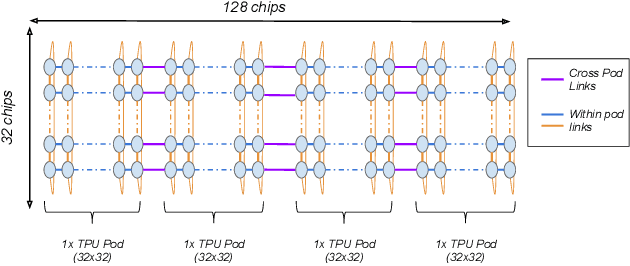
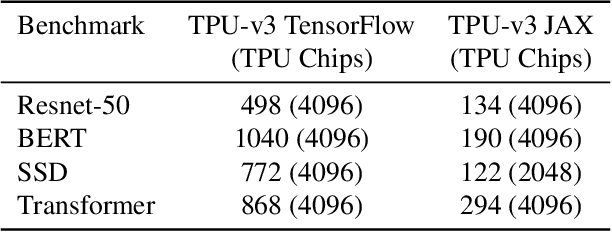
Recent results in language understanding using neural networks have required training hardware of unprecedentedscale, with thousands of chips cooperating on a single training run. This paper presents techniques to scaleML models on the Google TPU Multipod, a mesh with 4096 TPU-v3 chips. We discuss model parallelism toovercome scaling limitations from the fixed batch size in data parallelism, communication/collective optimizations,distributed evaluation of training metrics, and host input processing scaling optimizations. These techniques aredemonstrated in both the TensorFlow and JAX programming frameworks. We also present performance resultsfrom the recent Google submission to the MLPerf-v0.7 benchmark contest, achieving record training times from16 to 28 seconds in four MLPerf models on the Google TPU-v3 Multipod machine.
Conformer: Convolution-augmented Transformer for Speech Recognition
May 16, 2020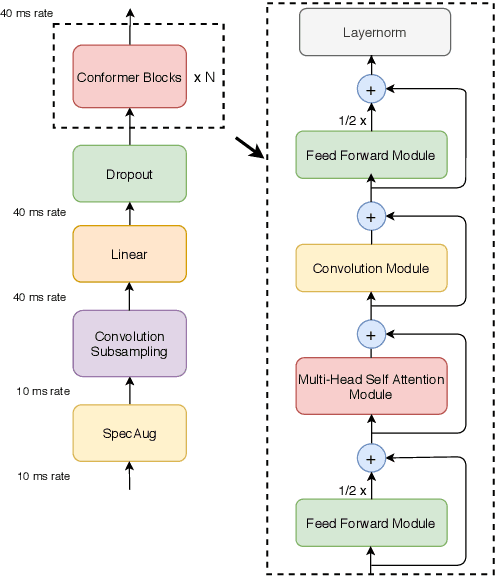
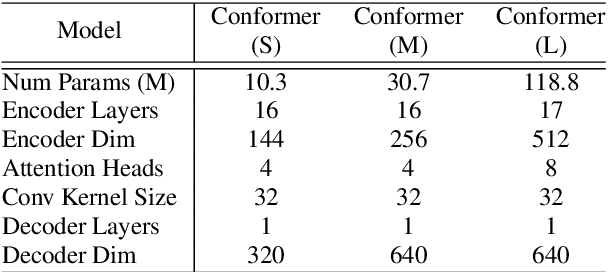

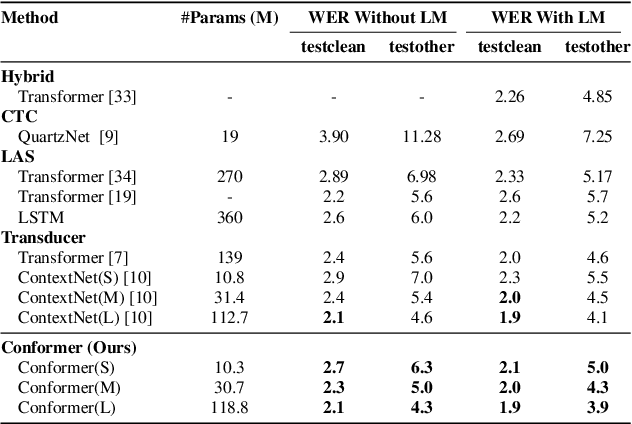
Recently Transformer and Convolution neural network (CNN) based models have shown promising results in Automatic Speech Recognition (ASR), outperforming Recurrent neural networks (RNNs). Transformer models are good at capturing content-based global interactions, while CNNs exploit local features effectively. In this work, we achieve the best of both worlds by studying how to combine convolution neural networks and transformers to model both local and global dependencies of an audio sequence in a parameter-efficient way. To this regard, we propose the convolution-augmented transformer for speech recognition, named Conformer. Conformer significantly outperforms the previous Transformer and CNN based models achieving state-of-the-art accuracies. On the widely used LibriSpeech benchmark, our model achieves WER of 2.1%/4.3% without using a language model and 1.9%/3.9% with an external language model on test/testother. We also observe competitive performance of 2.7%/6.3% with a small model of only 10M parameters.