 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCauses in neuron diagrams, and testing causal reasoning in Large Language Models. A glimpse of the future of philosophy?
Jun 17, 2025



We propose a test for abstract causal reasoning in AI, based on scholarship in the philosophy of causation, in particular on the neuron diagrams popularized by D. Lewis. We illustrate the test on advanced Large Language Models (ChatGPT, DeepSeek and Gemini). Remarkably, these chatbots are already capable of correctly identifying causes in cases that are hotly debated in the literature. In order to assess the results of these LLMs and future dedicated AI, we propose a definition of cause in neuron diagrams with a wider validity than published hitherto, which challenges the widespread view that such a definition is elusive. We submit that these results are an illustration of how future philosophical research might evolve: as an interplay between human and artificial expertise.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
SEAHORSE: A Multilingual, Multifaceted Dataset for Summarization Evaluation
May 22, 2023



Reliable automatic evaluation of summarization systems is challenging due to the multifaceted and subjective nature of the task. This is especially the case for languages other than English, where human evaluations are scarce. In this work, we introduce SEAHORSE, a dataset for multilingual, multifaceted summarization evaluation. SEAHORSE consists of 96K summaries with human ratings along 6 quality dimensions: comprehensibility, repetition, grammar, attribution, main ideas, and conciseness, covering 6 languages, 9 systems and 4 datasets. As a result of its size and scope, SEAHORSE can serve both as a benchmark to evaluate learnt metrics, as well as a large-scale resource for training such metrics. We show that metrics trained with SEAHORSE achieve strong performance on the out-of-domain meta-evaluation benchmarks TRUE (Honovich et al., 2022) and mFACE (Aharoni et al., 2022). We make SEAHORSE publicly available for future research on multilingual and multifaceted summarization evaluation.
TaTa: A Multilingual Table-to-Text Dataset for African Languages
Oct 31, 2022



Existing data-to-text generation datasets are mostly limited to English. To address this lack of data, we create Table-to-Text in African languages (TaTa), the first large multilingual table-to-text dataset with a focus on African languages. We created TaTa by transcribing figures and accompanying text in bilingual reports by the Demographic and Health Surveys Program, followed by professional translation to make the dataset fully parallel. TaTa includes 8,700 examples in nine languages including four African languages (Hausa, Igbo, Swahili, and Yor\`ub\'a) and a zero-shot test language (Russian). We additionally release screenshots of the original figures for future research on multilingual multi-modal approaches. Through an in-depth human evaluation, we show that TaTa is challenging for current models and that less than half the outputs from an mT5-XXL-based model are understandable and attributable to the source data. We further demonstrate that existing metrics perform poorly for TaTa and introduce learned metrics that achieve a high correlation with human judgments. We release all data and annotations at https://github.com/google-research/url-nlp.
GEMv2: Multilingual NLG Benchmarking in a Single Line of Code
Jun 24, 2022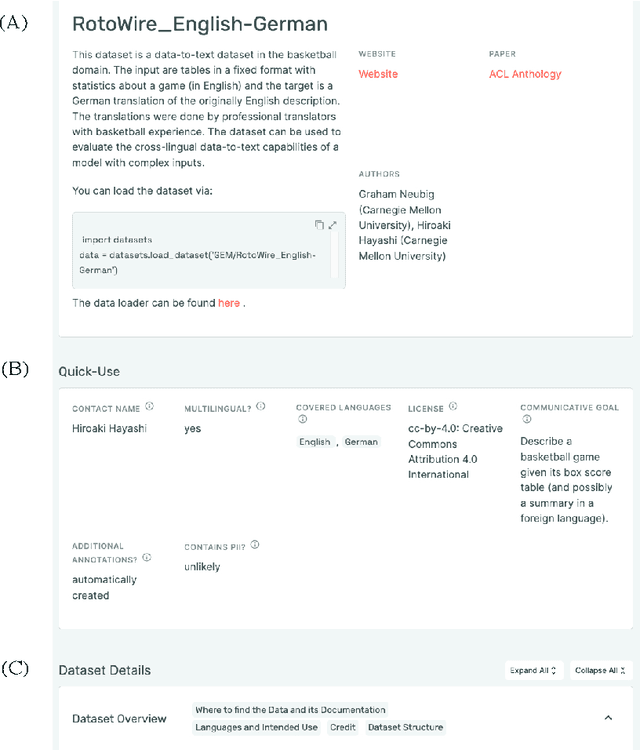

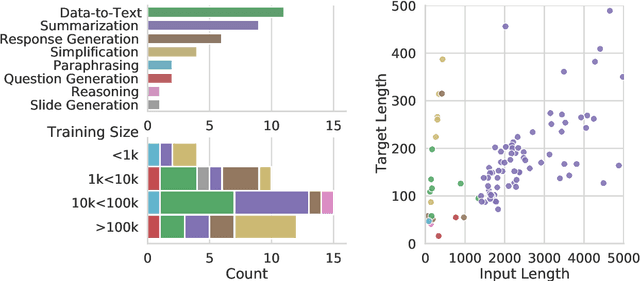

Evaluation in machine learning is usually informed by past choices, for example which datasets or metrics to use. This standardization enables the comparison on equal footing using leaderboards, but the evaluation choices become sub-optimal as better alternatives arise. This problem is especially pertinent in natural language generation which requires ever-improving suites of datasets, metrics, and human evaluation to make definitive claims. To make following best model evaluation practices easier, we introduce GEMv2. The new version of the Generation, Evaluation, and Metrics Benchmark introduces a modular infrastructure for dataset, model, and metric developers to benefit from each others work. GEMv2 supports 40 documented datasets in 51 languages. Models for all datasets can be evaluated online and our interactive data card creation and rendering tools make it easier to add new datasets to the living benchmark.
Measuring Attribution in Natural Language Generation Models
Dec 23, 2021

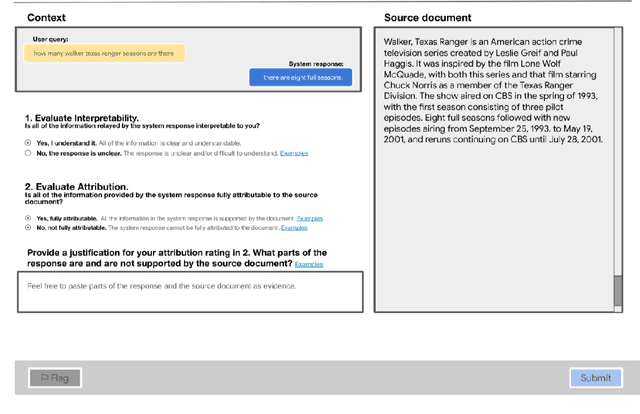
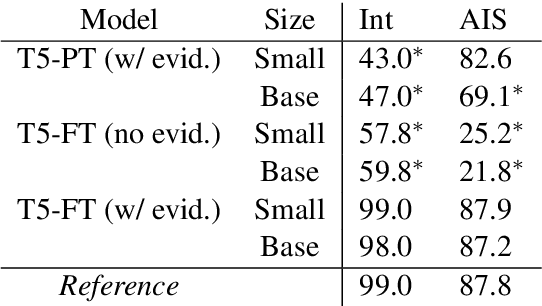
With recent improvements in natural language generation (NLG) models for various applications, it has become imperative to have the means to identify and evaluate whether NLG output is only sharing verifiable information about the external world. In this work, we present a new evaluation framework entitled Attributable to Identified Sources (AIS) for assessing the output of natural language generation models, when such output pertains to the external world. We first define AIS and introduce a two-stage annotation pipeline for allowing annotators to appropriately evaluate model output according to AIS guidelines. We empirically validate this approach on three generation datasets (two in the conversational QA domain and one in summarization) via human evaluation studies that suggest that AIS could serve as a common framework for measuring whether model-generated statements are supported by underlying sources. We release guidelines for the human evaluation studies.
SynthBio: A Case Study in Human-AI Collaborative Curation of Text Datasets
Nov 11, 2021
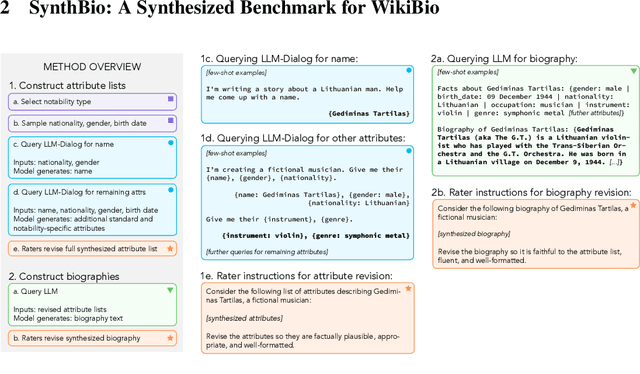

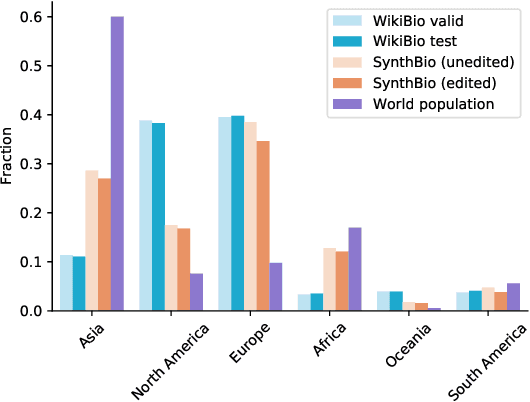
NLP researchers need more, higher-quality text datasets. Human-labeled datasets are expensive to collect, while datasets collected via automatic retrieval from the web such as WikiBio are noisy and can include undesired biases. Moreover, data sourced from the web is often included in datasets used to pretrain models, leading to inadvertent cross-contamination of training and test sets. In this work we introduce a novel method for efficient dataset curation: we use a large language model to provide seed generations to human raters, thereby changing dataset authoring from a writing task to an editing task. We use our method to curate SynthBio - a new evaluation set for WikiBio - composed of structured attribute lists describing fictional individuals, mapped to natural language biographies. We show that our dataset of fictional biographies is less noisy than WikiBio, and also more balanced with respect to gender and nationality.
The GEM Benchmark: Natural Language Generation, its Evaluation and Metrics
Feb 03, 2021



We introduce GEM, a living benchmark for natural language Generation (NLG), its Evaluation, and Metrics. Measuring progress in NLG relies on a constantly evolving ecosystem of automated metrics, datasets, and human evaluation standards. However, due to this moving target, new models often still evaluate on divergent anglo-centric corpora with well-established, but flawed, metrics. This disconnect makes it challenging to identify the limitations of current models and opportunities for progress. Addressing this limitation, GEM provides an environment in which models can easily be applied to a wide set of corpora and evaluation strategies can be tested. Regular updates to the benchmark will help NLG research become more multilingual and evolve the challenge alongside models. This paper serves as the description of the initial release for which we are organizing a shared task at our ACL 2021 Workshop and to which we invite the entire NLG community to participate.
Convolution Neural Networks for Semantic Segmentation: Application to Small Datasets of Biomedical Images
Nov 01, 2020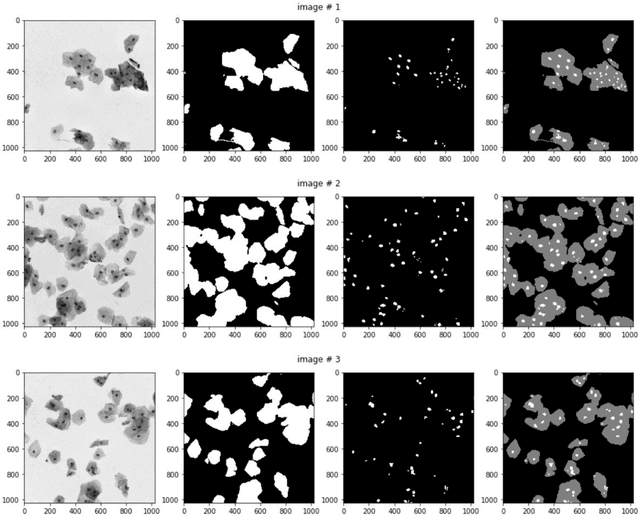
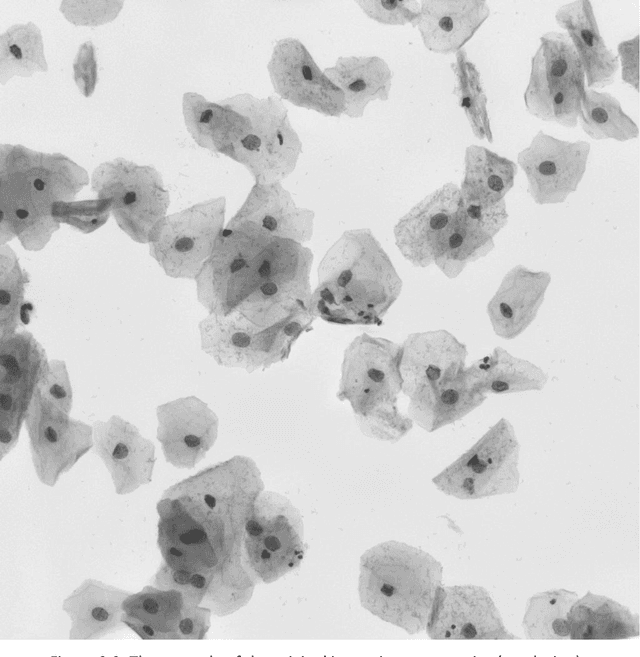
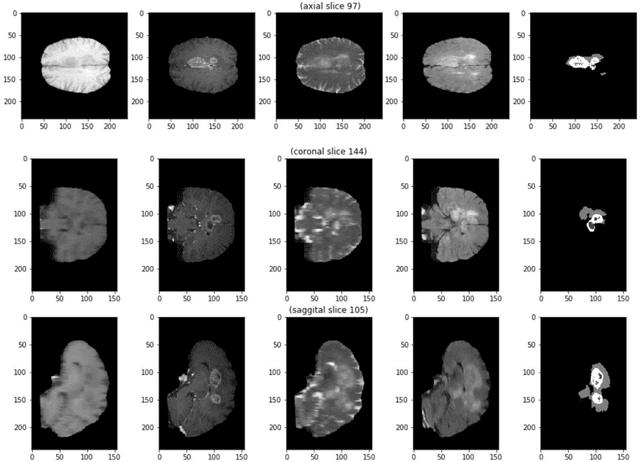
This thesis studies how the segmentation results, produced by convolutional neural networks (CNN), is different from each other when applied to small biomedical datasets. We use different architectures, parameters and hyper-parameters, trying to find out the better configurations for our task, and trying to find out underlying regularities. Two working datasets are from biomedical area of research. We conducted a lot of experiments with the two types of networks and the received results have shown the preference of some conditions of experiments and parameters of the networks over the others. All testing results are given in the tables and some selected resulting graphs and segmentation predictions are shown for better illustration.