 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePSSI-MaxST: An Efficient Pixel-Segment Similarity Index Using Intensity and Smoothness Features for Maximum Spanning Tree Based Segmentation
Jan 15, 2026Interactive graph-based segmentation methods partition an image into foreground and background regions with the aid of user inputs. However, existing approaches often suffer from high computational costs, sensitivity to user interactions, and degraded performance when the foreground and background share similar color distributions. A key factor influencing segmentation performance is the similarity measure used for assigning edge weights in the graph. To address these challenges, we propose a novel Pixel Segment Similarity Index (PSSI), which leverages the harmonic mean of inter-channel similarities by incorporating both pixel intensity and spatial smoothness features. The harmonic mean effectively penalizes dissimilarities in any individual channel, enhancing robustness. The computational complexity of PSSI is $\mathcal{O}(B)$, where $B$ denotes the number of histogram bins. Our segmentation framework begins with low-level segmentation using MeanShift, which effectively captures color, texture, and segment shape. Based on the resulting pixel segments, we construct a pixel-segment graph with edge weights determined by PSSI. For partitioning, we employ the Maximum Spanning Tree (MaxST), which captures strongly connected local neighborhoods beneficial for precise segmentation. The integration of the proposed PSSI, MeanShift, and MaxST allows our method to jointly capture color similarity, smoothness, texture, shape, and strong local connectivity. Experimental evaluations on the GrabCut and Images250 datasets demonstrate that our method consistently outperforms current graph-based interactive segmentation methods such as AMOE, OneCut, and SSNCut in terms of segmentation quality, as measured by Jaccard Index (IoU), $F_1$ score, execution time and Mean Error (ME). Code is publicly available at: https://github.com/KaustubhShejole/PSSI-MaxST.
Nirjas: An open source framework for extracting metadata from the source code
Sep 22, 2024



Metadata and comments are critical elements of any software development process. In this paper, we explain how metadata and comments in source code can play an essential role in comprehending software. We introduce a Python-based open-source framework, Nirjas, which helps in extracting this metadata in a structured manner. Various syntaxes, types, and widely accepted conventions exist for adding comments in source files of different programming languages. Edge cases can create noise in extraction, for which we use Regex to accurately retrieve metadata. Non-Regex methods can give results but often miss accuracy and noise separation. Nirjas also separates different types of comments, source code, and provides details about those comments, such as line number, file name, language used, total SLOC, etc. Nirjas is a standalone Python framework/library and can be easily installed via source or pip (the Python package installer). Nirjas was initially created as part of a Google Summer of Code project and is currently developed and maintained under the FOSSology organization.
Training Language Models on the Knowledge Graph: Insights on Hallucinations and Their Detectability
Aug 14, 2024



While many capabilities of language models (LMs) improve with increased training budget, the influence of scale on hallucinations is not yet fully understood. Hallucinations come in many forms, and there is no universally accepted definition. We thus focus on studying only those hallucinations where a correct answer appears verbatim in the training set. To fully control the training data content, we construct a knowledge graph (KG)-based dataset, and use it to train a set of increasingly large LMs. We find that for a fixed dataset, larger and longer-trained LMs hallucinate less. However, hallucinating on $\leq5$% of the training data requires an order of magnitude larger model, and thus an order of magnitude more compute, than Hoffmann et al. (2022) reported was optimal. Given this costliness, we study how hallucination detectors depend on scale. While we see detector size improves performance on fixed LM's outputs, we find an inverse relationship between the scale of the LM and the detectability of its hallucinations.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Frontier Language Models are not Robust to Adversarial Arithmetic, or "What do I need to say so you agree 2+2=5?
Nov 15, 2023



We introduce and study the problem of adversarial arithmetic, which provides a simple yet challenging testbed for language model alignment. This problem is comprised of arithmetic questions posed in natural language, with an arbitrary adversarial string inserted before the question is complete. Even in the simple setting of 1-digit addition problems, it is easy to find adversarial prompts that make all tested models (including PaLM2, GPT4, Claude2) misbehave, and even to steer models to a particular wrong answer. We additionally provide a simple algorithm for finding successful attacks by querying those same models, which we name "prompt inversion rejection sampling" (PIRS). We finally show that models can be partially hardened against these attacks via reinforcement learning and via agentic constitutional loops. However, we were not able to make a language model fully robust against adversarial arithmetic attacks.
PaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.
Scaling Instruction-Finetuned Language Models
Oct 20, 2022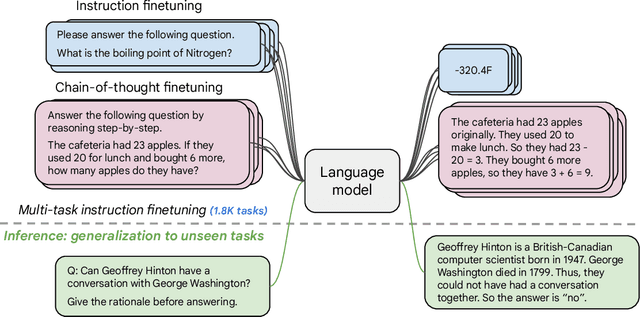

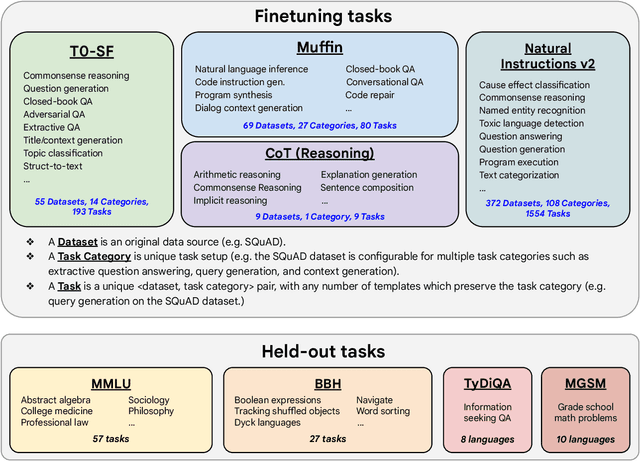

Finetuning language models on a collection of datasets phrased as instructions has been shown to improve model performance and generalization to unseen tasks. In this paper we explore instruction finetuning with a particular focus on (1) scaling the number of tasks, (2) scaling the model size, and (3) finetuning on chain-of-thought data. We find that instruction finetuning with the above aspects dramatically improves performance on a variety of model classes (PaLM, T5, U-PaLM), prompting setups (zero-shot, few-shot, CoT), and evaluation benchmarks (MMLU, BBH, TyDiQA, MGSM, open-ended generation). For instance, Flan-PaLM 540B instruction-finetuned on 1.8K tasks outperforms PALM 540B by a large margin (+9.4% on average). Flan-PaLM 540B achieves state-of-the-art performance on several benchmarks, such as 75.2% on five-shot MMLU. We also publicly release Flan-T5 checkpoints, which achieve strong few-shot performance even compared to much larger models, such as PaLM 62B. Overall, instruction finetuning is a general method for improving the performance and usability of pretrained language models.
PaLI: A Jointly-Scaled Multilingual Language-Image Model
Sep 16, 2022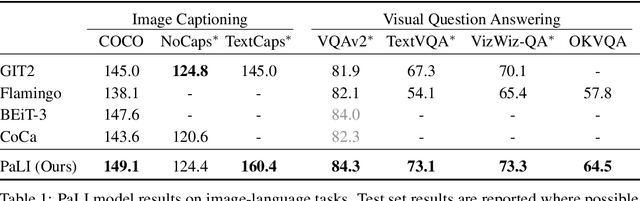

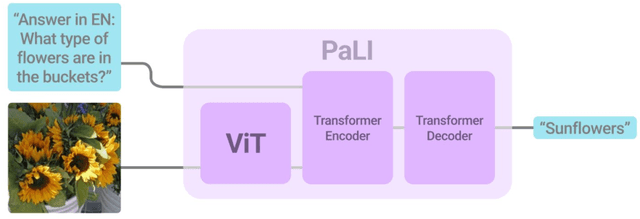

Effective scaling and a flexible task interface enable large language models to excel at many tasks. PaLI (Pathways Language and Image model) extends this approach to the joint modeling of language and vision. PaLI generates text based on visual and textual inputs, and with this interface performs many vision, language, and multimodal tasks, in many languages. To train PaLI, we make use of large pretrained encoder-decoder language models and Vision Transformers (ViTs). This allows us to capitalize on their existing capabilities and leverage the substantial cost of training them. We find that joint scaling of the vision and language components is important. Since existing Transformers for language are much larger than their vision counterparts, we train the largest ViT to date (ViT-e) to quantify the benefits from even larger-capacity vision models. To train PaLI, we create a large multilingual mix of pretraining tasks, based on a new image-text training set containing 10B images and texts in over 100 languages. PaLI achieves state-of-the-art in multiple vision and language tasks (such as captioning, visual question-answering, scene-text understanding), while retaining a simple, modular, and scalable design.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
PaLM: Scaling Language Modeling with Pathways
Apr 19, 2022



Large language models have been shown to achieve remarkable performance across a variety of natural language tasks using few-shot learning, which drastically reduces the number of task-specific training examples needed to adapt the model to a particular application. To further our understanding of the impact of scale on few-shot learning, we trained a 540-billion parameter, densely activated, Transformer language model, which we call Pathways Language Model PaLM. We trained PaLM on 6144 TPU v4 chips using Pathways, a new ML system which enables highly efficient training across multiple TPU Pods. We demonstrate continued benefits of scaling by achieving state-of-the-art few-shot learning results on hundreds of language understanding and generation benchmarks. On a number of these tasks, PaLM 540B achieves breakthrough performance, outperforming the finetuned state-of-the-art on a suite of multi-step reasoning tasks, and outperforming average human performance on the recently released BIG-bench benchmark. A significant number of BIG-bench tasks showed discontinuous improvements from model scale, meaning that performance steeply increased as we scaled to our largest model. PaLM also has strong capabilities in multilingual tasks and source code generation, which we demonstrate on a wide array of benchmarks. We additionally provide a comprehensive analysis on bias and toxicity, and study the extent of training data memorization with respect to model scale. Finally, we discuss the ethical considerations related to large language models and discuss potential mitigation strategies.