 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe FACTS Leaderboard: A Comprehensive Benchmark for Large Language Model Factuality
Dec 11, 2025We introduce The FACTS Leaderboard, an online leaderboard suite and associated set of benchmarks that comprehensively evaluates the ability of language models to generate factually accurate text across diverse scenarios. The suite provides a holistic measure of factuality by aggregating the performance of models on four distinct sub-leaderboards: (1) FACTS Multimodal, which measures the factuality of responses to image-based questions; (2) FACTS Parametric, which assesses models' world knowledge by answering closed-book factoid questions from internal parameters; (3) FACTS Search, which evaluates factuality in information-seeking scenarios, where the model must use a search API; and (4) FACTS Grounding (v2), which evaluates whether long-form responses are grounded in provided documents, featuring significantly improved judge models. Each sub-leaderboard employs automated judge models to score model responses, and the final suite score is an average of the four components, designed to provide a robust and balanced assessment of a model's overall factuality. The FACTS Leaderboard Suite will be actively maintained, containing both public and private splits to allow for external participation while guarding its integrity. It can be found at https://www.kaggle.com/benchmarks/google/facts .
The FACTS Grounding Leaderboard: Benchmarking LLMs' Ability to Ground Responses to Long-Form Input
Jan 06, 2025



We introduce FACTS Grounding, an online leaderboard and associated benchmark that evaluates language models' ability to generate text that is factually accurate with respect to given context in the user prompt. In our benchmark, each prompt includes a user request and a full document, with a maximum length of 32k tokens, requiring long-form responses. The long-form responses are required to be fully grounded in the provided context document while fulfilling the user request. Models are evaluated using automated judge models in two phases: (1) responses are disqualified if they do not fulfill the user request; (2) they are judged as accurate if the response is fully grounded in the provided document. The automated judge models were comprehensively evaluated against a held-out test-set to pick the best prompt template, and the final factuality score is an aggregate of multiple judge models to mitigate evaluation bias. The FACTS Grounding leaderboard will be actively maintained over time, and contains both public and private splits to allow for external participation while guarding the integrity of the leaderboard. It can be found at https://www.kaggle.com/facts-leaderboard.
DOLOMITES: Domain-Specific Long-Form Methodical Tasks
May 09, 2024Experts in various fields routinely perform methodical writing tasks to plan, organize, and report their work. From a clinician writing a differential diagnosis for a patient, to a teacher writing a lesson plan for students, these tasks are pervasive, requiring to methodically generate structured long-form output for a given input. We develop a typology of methodical tasks structured in the form of a task objective, procedure, input, and output, and introduce DoLoMiTes, a novel benchmark with specifications for 519 such tasks elicited from hundreds of experts from across 25 fields. Our benchmark further contains specific instantiations of methodical tasks with concrete input and output examples (1,857 in total) which we obtain by collecting expert revisions of up to 10 model-generated examples of each task. We use these examples to evaluate contemporary language models highlighting that automating methodical tasks is a challenging long-form generation problem, as it requires performing complex inferences, while drawing upon the given context as well as domain knowledge.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
$μ$PLAN: Summarizing using a Content Plan as Cross-Lingual Bridge
May 23, 2023



Cross-lingual summarization consists of generating a summary in one language given an input document in a different language, allowing for the dissemination of relevant content across speakers of other languages. However, this task remains challenging, mainly because of the need for cross-lingual datasets and the compounded difficulty of summarizing and translating. This work presents $\mu$PLAN, an approach to cross-lingual summarization that uses an intermediate planning step as a cross-lingual bridge. We formulate the plan as a sequence of entities that captures the conceptualization of the summary, i.e. identifying the salient content and expressing in which order to present the information, separate from the surface form. Using a multilingual knowledge base, we align the entities to their canonical designation across languages. $\mu$PLAN models first learn to generate the plan and then continue generating the summary conditioned on the plan and the input. We evaluate our methodology on the XWikis dataset on cross-lingual pairs across four languages and demonstrate that this planning objective achieves state-of-the-art performance in terms of ROUGE and faithfulness scores. Moreover, this planning approach improves the zero-shot transfer to new cross-lingual language pairs compared to non-planning baselines.
Coreference Resolution through a seq2seq Transition-Based System
Nov 22, 2022Most recent coreference resolution systems use search algorithms over possible spans to identify mentions and resolve coreference. We instead present a coreference resolution system that uses a text-to-text (seq2seq) paradigm to predict mentions and links jointly. We implement the coreference system as a transition system and use multilingual T5 as an underlying language model. We obtain state-of-the-art accuracy on the CoNLL-2012 datasets with 83.3 F1-score for English (a 2.3 higher F1-score than previous work (Dobrovolskii, 2021)) using only CoNLL data for training, 68.5 F1-score for Arabic (+4.1 higher than previous work) and 74.3 F1-score for Chinese (+5.3). In addition we use the SemEval-2010 data sets for experiments in the zero-shot setting, a few-shot setting, and supervised setting using all available training data. We get substantially higher zero-shot F1-scores for 3 out of 4 languages than previous approaches and significantly exceed previous supervised state-of-the-art results for all five tested languages.
Towards Computationally Verifiable Semantic Grounding for Language Models
Nov 16, 2022



The paper presents an approach to semantic grounding of language models (LMs) that conceptualizes the LM as a conditional model generating text given a desired semantic message formalized as a set of entity-relationship triples. It embeds the LM in an auto-encoder by feeding its output to a semantic parser whose output is in the same representation domain as the input message. Compared to a baseline that generates text using greedy search, we demonstrate two techniques that improve the fluency and semantic accuracy of the generated text: The first technique samples multiple candidate text sequences from which the semantic parser chooses. The second trains the language model while keeping the semantic parser frozen to improve the semantic accuracy of the auto-encoder. We carry out experiments on the English WebNLG 3.0 data set, using BLEU to measure the fluency of generated text and standard parsing metrics to measure semantic accuracy. We show that our proposed approaches significantly improve on the greedy search baseline. Human evaluation corroborates the results of the automatic evaluation experiments.
QAmeleon: Multilingual QA with Only 5 Examples
Nov 15, 2022The availability of large, high-quality datasets has been one of the main drivers of recent progress in question answering (QA). Such annotated datasets however are difficult and costly to collect, and rarely exist in languages other than English, rendering QA technology inaccessible to underrepresented languages. An alternative to building large monolingual training datasets is to leverage pre-trained language models (PLMs) under a few-shot learning setting. Our approach, QAmeleon, uses a PLM to automatically generate multilingual data upon which QA models are trained, thus avoiding costly annotation. Prompt tuning the PLM for data synthesis with only five examples per language delivers accuracy superior to translation-based baselines, bridges nearly 60% of the gap between an English-only baseline and a fully supervised upper bound trained on almost 50,000 hand labeled examples, and always leads to substantial improvements compared to fine-tuning a QA model directly on labeled examples in low resource settings. Experiments on the TyDiQA-GoldP and MLQA benchmarks show that few-shot prompt tuning for data synthesis scales across languages and is a viable alternative to large-scale annotation.
Conciseness: An Overlooked Language Task
Nov 08, 2022



We report on novel investigations into training models that make sentences concise. We define the task and show that it is different from related tasks such as summarization and simplification. For evaluation, we release two test sets, consisting of 2000 sentences each, that were annotated by two and five human annotators, respectively. We demonstrate that conciseness is a difficult task for which zero-shot setups with large neural language models often do not perform well. Given the limitations of these approaches, we propose a synthetic data generation method based on round-trip translations. Using this data to either train Transformers from scratch or fine-tune T5 models yields our strongest baselines that can be further improved by fine-tuning on an artificial conciseness dataset that we derived from multi-annotator machine translation test sets.
Simple and Effective Gradient-Based Tuning of Sequence-to-Sequence Models
Sep 10, 2022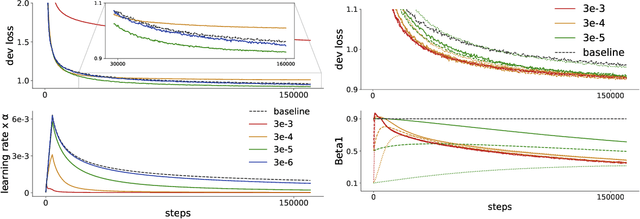
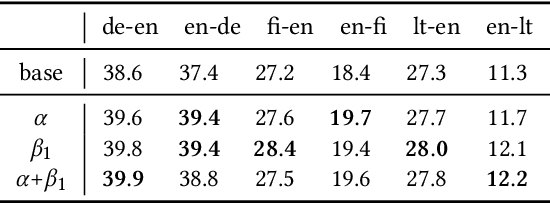
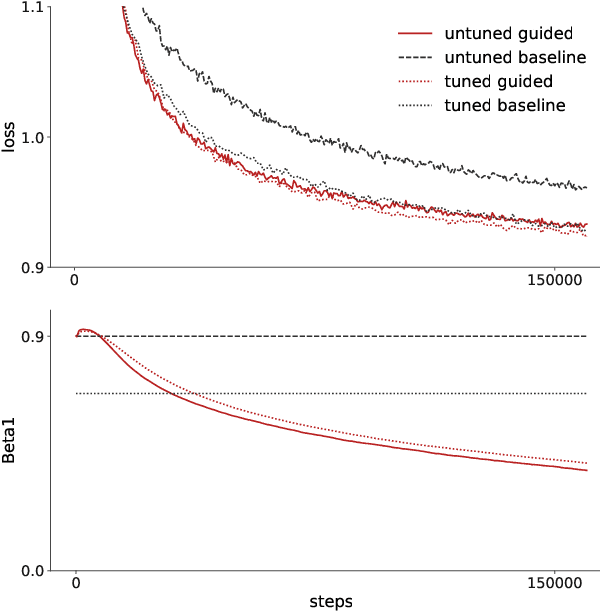
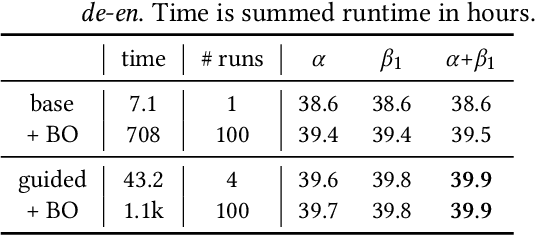
Recent trends towards training ever-larger language models have substantially improved machine learning performance across linguistic tasks. However, the huge cost of training larger models can make tuning them prohibitively expensive, motivating the study of more efficient methods. Gradient-based hyper-parameter optimization offers the capacity to tune hyper-parameters during training, yet has not previously been studied in a sequence-to-sequence setting. We apply a simple and general gradient-based hyperparameter optimization method to sequence-to-sequence tasks for the first time, demonstrating both efficiency and performance gains over strong baselines for both Neural Machine Translation and Natural Language Understanding (NLU) tasks (via T5 pretraining). For translation, we show the method generalizes across language pairs, is more efficient than Bayesian hyper-parameter optimization, and that learned schedules for some hyper-parameters can out-perform even optimal constant-valued tuning. For T5, we show that learning hyper-parameters during pretraining can improve performance across downstream NLU tasks. When learning multiple hyper-parameters concurrently, we show that the global learning rate can follow a schedule over training that improves performance and is not explainable by the `short-horizon bias' of greedy methods \citep{wu2018}. We release the code used to facilitate further research.