 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Neural Network Training: An Analysis of the AlgoPerf Competition
Feb 20, 2025



The goal of the AlgoPerf: Training Algorithms competition is to evaluate practical speed-ups in neural network training achieved solely by improving the underlying training algorithms. In the external tuning ruleset, submissions must provide workload-agnostic hyperparameter search spaces, while in the self-tuning ruleset they must be completely hyperparameter-free. In both rulesets, submissions are compared on time-to-result across multiple deep learning workloads, training on fixed hardware. This paper presents the inaugural AlgoPerf competition's results, which drew 18 diverse submissions from 10 teams. Our investigation reveals several key findings: (1) The winning submission in the external tuning ruleset, using Distributed Shampoo, demonstrates the effectiveness of non-diagonal preconditioning over popular methods like Adam, even when compared on wall-clock runtime. (2) The winning submission in the self-tuning ruleset, based on the Schedule Free AdamW algorithm, demonstrates a new level of effectiveness for completely hyperparameter-free training algorithms. (3) The top-scoring submissions were surprisingly robust to workload changes. We also discuss the engineering challenges encountered in ensuring a fair comparison between different training algorithms. These results highlight both the significant progress so far, and the considerable room for further improvements.
A Little Help Goes a Long Way: Efficient LLM Training by Leveraging Small LMs
Oct 24, 2024



A primary challenge in large language model (LLM) development is their onerous pre-training cost. Typically, such pre-training involves optimizing a self-supervised objective (such as next-token prediction) over a large corpus. This paper explores a promising paradigm to improve LLM pre-training efficiency and quality by suitably leveraging a small language model (SLM). In particular, this paradigm relies on an SLM to both (1) provide soft labels as additional training supervision, and (2) select a small subset of valuable ("informative" and "hard") training examples. Put together, this enables an effective transfer of the SLM's predictive distribution to the LLM, while prioritizing specific regions of the training data distribution. Empirically, this leads to reduced LLM training time compared to standard training, while improving the overall quality. Theoretically, we develop a statistical framework to systematically study the utility of SLMs in enabling efficient training of high-quality LLMs. In particular, our framework characterizes how the SLM's seemingly low-quality supervision can enhance the training of a much more capable LLM. Furthermore, it also highlights the need for an adaptive utilization of such supervision, by striking a balance between the bias and variance introduced by the SLM-provided soft labels. We corroborate our theoretical framework by improving the pre-training of an LLM with 2.8B parameters by utilizing a smaller LM with 1.5B parameters on the Pile dataset.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Benchmarking Neural Network Training Algorithms
Jun 12, 2023



Training algorithms, broadly construed, are an essential part of every deep learning pipeline. Training algorithm improvements that speed up training across a wide variety of workloads (e.g., better update rules, tuning protocols, learning rate schedules, or data selection schemes) could save time, save computational resources, and lead to better, more accurate, models. Unfortunately, as a community, we are currently unable to reliably identify training algorithm improvements, or even determine the state-of-the-art training algorithm. In this work, using concrete experiments, we argue that real progress in speeding up training requires new benchmarks that resolve three basic challenges faced by empirical comparisons of training algorithms: (1) how to decide when training is complete and precisely measure training time, (2) how to handle the sensitivity of measurements to exact workload details, and (3) how to fairly compare algorithms that require hyperparameter tuning. In order to address these challenges, we introduce a new, competitive, time-to-result benchmark using multiple workloads running on fixed hardware, the AlgoPerf: Training Algorithms benchmark. Our benchmark includes a set of workload variants that make it possible to detect benchmark submissions that are more robust to workload changes than current widely-used methods. Finally, we evaluate baseline submissions constructed using various optimizers that represent current practice, as well as other optimizers that have recently received attention in the literature. These baseline results collectively demonstrate the feasibility of our benchmark, show that non-trivial gaps between methods exist, and set a provisional state-of-the-art for future benchmark submissions to try and surpass.
PaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.
Kernel Regression with Infinite-Width Neural Networks on Millions of Examples
Mar 09, 2023Neural kernels have drastically increased performance on diverse and nonstandard data modalities but require significantly more compute, which previously limited their application to smaller datasets. In this work, we address this by massively parallelizing their computation across many GPUs. We combine this with a distributed, preconditioned conjugate gradients algorithm to enable kernel regression at a large scale (i.e. up to five million examples). Using this approach, we study scaling laws of several neural kernels across many orders of magnitude for the CIFAR-5m dataset. Using data augmentation to expand the original CIFAR-10 training dataset by a factor of 20, we obtain a test accuracy of 91.2\% (SotA for a pure kernel method). Moreover, we explore neural kernels on other data modalities, obtaining results on protein and small molecule prediction tasks that are competitive with SotA methods.
Benchmarking Bayesian Deep Learning on Diabetic Retinopathy Detection Tasks
Nov 23, 2022Bayesian deep learning seeks to equip deep neural networks with the ability to precisely quantify their predictive uncertainty, and has promised to make deep learning more reliable for safety-critical real-world applications. Yet, existing Bayesian deep learning methods fall short of this promise; new methods continue to be evaluated on unrealistic test beds that do not reflect the complexities of downstream real-world tasks that would benefit most from reliable uncertainty quantification. We propose the RETINA Benchmark, a set of real-world tasks that accurately reflect such complexities and are designed to assess the reliability of predictive models in safety-critical scenarios. Specifically, we curate two publicly available datasets of high-resolution human retina images exhibiting varying degrees of diabetic retinopathy, a medical condition that can lead to blindness, and use them to design a suite of automated diagnosis tasks that require reliable predictive uncertainty quantification. We use these tasks to benchmark well-established and state-of-the-art Bayesian deep learning methods on task-specific evaluation metrics. We provide an easy-to-use codebase for fast and easy benchmarking following reproducibility and software design principles. We provide implementations of all methods included in the benchmark as well as results computed over 100 TPU days, 20 GPU days, 400 hyperparameter configurations, and evaluation on at least 6 random seeds each.
Adaptive Gradient Methods at the Edge of Stability
Jul 29, 2022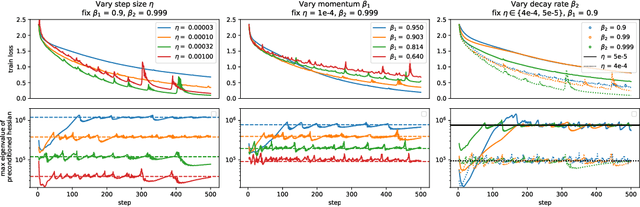
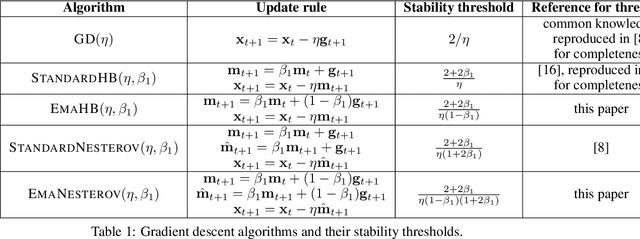
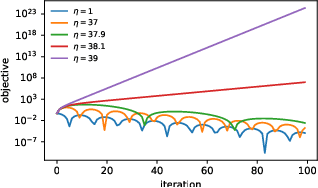

Very little is known about the training dynamics of adaptive gradient methods like Adam in deep learning. In this paper, we shed light on the behavior of these algorithms in the full-batch and sufficiently large batch settings. Specifically, we empirically demonstrate that during full-batch training, the maximum eigenvalue of the preconditioned Hessian typically equilibrates at a certain numerical value -- the stability threshold of a gradient descent algorithm. For Adam with step size $\eta$ and $\beta_1 = 0.9$, this stability threshold is $38/\eta$. Similar effects occur during minibatch training, especially as the batch size grows. Yet, even though adaptive methods train at the ``Adaptive Edge of Stability'' (AEoS), their behavior in this regime differs in a significant way from that of non-adaptive methods at the EoS. Whereas non-adaptive algorithms at the EoS are blocked from entering high-curvature regions of the loss landscape, adaptive gradient methods at the AEoS can keep advancing into high-curvature regions, while adapting the preconditioner to compensate. Our findings can serve as a foundation for the community's future understanding of adaptive gradient methods in deep learning.
Plex: Towards Reliability using Pretrained Large Model Extensions
Jul 15, 2022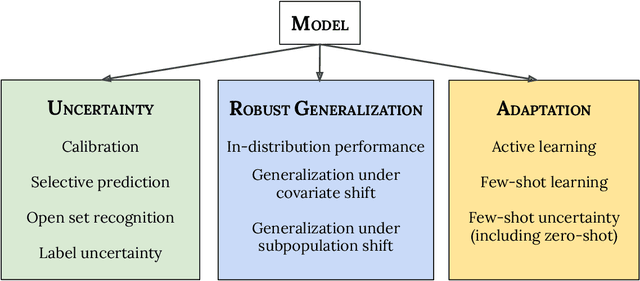

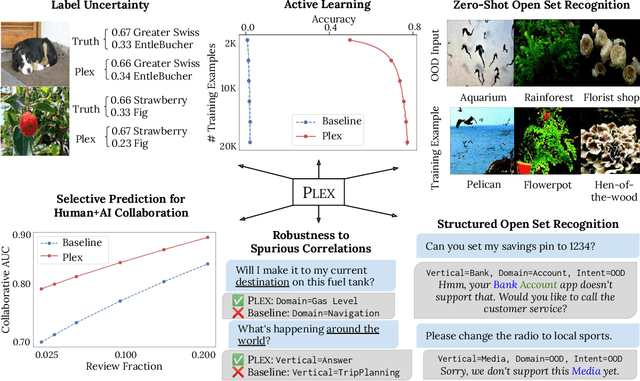

A recent trend in artificial intelligence is the use of pretrained models for language and vision tasks, which have achieved extraordinary performance but also puzzling failures. Probing these models' abilities in diverse ways is therefore critical to the field. In this paper, we explore the reliability of models, where we define a reliable model as one that not only achieves strong predictive performance but also performs well consistently over many decision-making tasks involving uncertainty (e.g., selective prediction, open set recognition), robust generalization (e.g., accuracy and proper scoring rules such as log-likelihood on in- and out-of-distribution datasets), and adaptation (e.g., active learning, few-shot uncertainty). We devise 10 types of tasks over 40 datasets in order to evaluate different aspects of reliability on both vision and language domains. To improve reliability, we developed ViT-Plex and T5-Plex, pretrained large model extensions for vision and language modalities, respectively. Plex greatly improves the state-of-the-art across reliability tasks, and simplifies the traditional protocol as it improves the out-of-the-box performance and does not require designing scores or tuning the model for each task. We demonstrate scaling effects over model sizes up to 1B parameters and pretraining dataset sizes up to 4B examples. We also demonstrate Plex's capabilities on challenging tasks including zero-shot open set recognition, active learning, and uncertainty in conversational language understanding.