 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquipping Transformer with Random-Access Reading for Long-Context Understanding
May 21, 2024



Long-context modeling presents a significant challenge for transformer-based large language models (LLMs) due to the quadratic complexity of the self-attention mechanism and issues with length extrapolation caused by pretraining exclusively on short inputs. Existing methods address computational complexity through techniques such as text chunking, the kernel approach, and structured attention, and tackle length extrapolation problems through positional encoding, continued pretraining, and data engineering. These approaches typically require $\textbf{sequential access}$ to the document, necessitating reading from the first to the last token. We contend that for goal-oriented reading of long documents, such sequential access is not necessary, and a proficiently trained model can learn to omit hundreds of less pertinent tokens. Inspired by human reading behaviors and existing empirical observations, we propose $\textbf{random access}$, a novel reading strategy that enables transformers to efficiently process long documents without examining every token. Experimental results from pretraining, fine-tuning, and inference phases validate the efficacy of our method.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Attendre: Wait To Attend By Retrieval With Evicted Queries in Memory-Based Transformers for Long Context Processing
Jan 10, 2024As LLMs have become capable of processing more complex types of inputs, researchers have recently studied how to efficiently and affordably process possibly arbitrarily long sequences. One effective approach is to use a FIFO memory to store keys and values of an attention sublayer from past chunks to allow subsequent queries to attend. However, this approach requires a large memory and/or takes into the consideration the specific LM architecture. Moreover, due to the causal nature between the key-values in prior context and the queries at present, this approach cannot be extended to bidirectional attention such as in an encoder-decoder or PrefixLM decoder-only architecture. In this paper, we propose to use eviction policies, such as LRA and LFA, to reduce the memory size and adapt to various architectures, and we also propose the Attendre layer, a wait-to-attend mechanism by retrieving the key-value memory (K/V memory) with evicted queries in the query memory (Q memory). As a first step, we evaluate this method in the context length extension setup using the TriviaQA reading comprehension task, and show the effectiveness of the approach.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
LMDX: Language Model-based Document Information Extraction and Localization
Sep 19, 2023



Large Language Models (LLM) have revolutionized Natural Language Processing (NLP), improving state-of-the-art on many existing tasks and exhibiting emergent capabilities. However, LLMs have not yet been successfully applied on semi-structured document information extraction, which is at the core of many document processing workflows and consists of extracting key entities from a visually rich document (VRD) given a predefined target schema. The main obstacles to LLM adoption in that task have been the absence of layout encoding within LLMs, critical for a high quality extraction, and the lack of a grounding mechanism ensuring the answer is not hallucinated. In this paper, we introduce Language Model-based Document Information Extraction and Localization (LMDX), a methodology to adapt arbitrary LLMs for document information extraction. LMDX can do extraction of singular, repeated, and hierarchical entities, both with and without training data, while providing grounding guarantees and localizing the entities within the document. In particular, we apply LMDX to the PaLM 2-S LLM and evaluate it on VRDU and CORD benchmarks, setting a new state-of-the-art and showing how LMDX enables the creation of high quality, data-efficient parsers.
FormNetV2: Multimodal Graph Contrastive Learning for Form Document Information Extraction
May 04, 2023



The recent advent of self-supervised pre-training techniques has led to a surge in the use of multimodal learning in form document understanding. However, existing approaches that extend the mask language modeling to other modalities require careful multi-task tuning, complex reconstruction target designs, or additional pre-training data. In FormNetV2, we introduce a centralized multimodal graph contrastive learning strategy to unify self-supervised pre-training for all modalities in one loss. The graph contrastive objective maximizes the agreement of multimodal representations, providing a natural interplay for all modalities without special customization. In addition, we extract image features within the bounding box that joins a pair of tokens connected by a graph edge, capturing more targeted visual cues without loading a sophisticated and separately pre-trained image embedder. FormNetV2 establishes new state-of-the-art performance on FUNSD, CORD, SROIE and Payment benchmarks with a more compact model size.
Protoformer: Embedding Prototypes for Transformers
Jun 25, 2022Transformers have been widely applied in text classification. Unfortunately, real-world data contain anomalies and noisy labels that cause challenges for state-of-art Transformers. This paper proposes Protoformer, a novel self-learning framework for Transformers that can leverage problematic samples for text classification. Protoformer features a selection mechanism for embedding samples that allows us to efficiently extract and utilize anomalies prototypes and difficult class prototypes. We demonstrated such capabilities on datasets with diverse textual structures (e.g., Twitter, IMDB, ArXiv). We also applied the framework to several models. The results indicate that Protoformer can improve current Transformers in various empirical settings.
* Advances in Knowledge Discovery and Data Mining (PAKDD 2022)
FormNet: Structural Encoding beyond Sequential Modeling in Form Document Information Extraction
Mar 24, 2022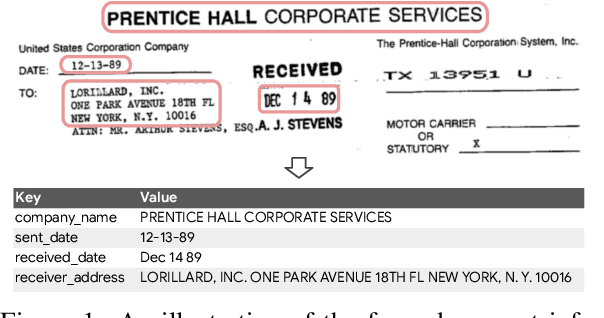
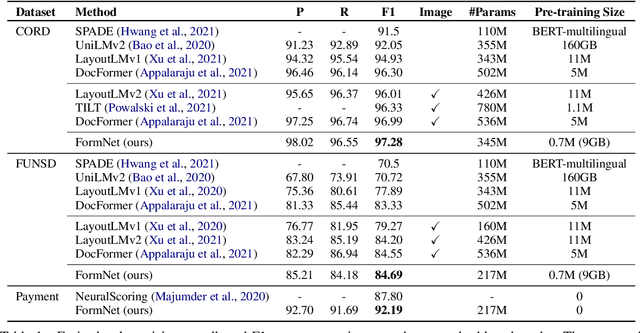
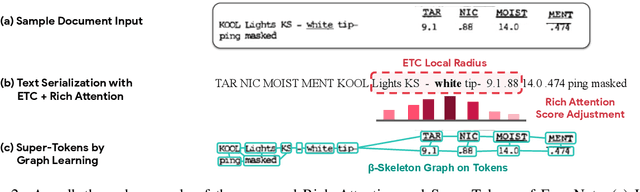
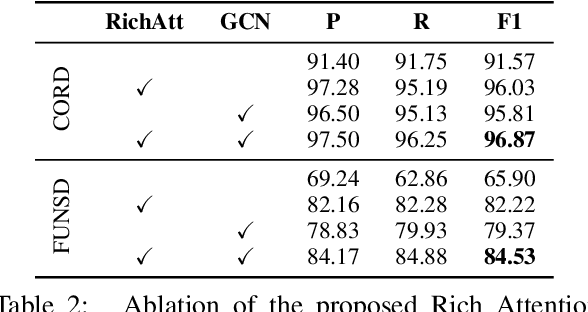
Sequence modeling has demonstrated state-of-the-art performance on natural language and document understanding tasks. However, it is challenging to correctly serialize tokens in form-like documents in practice due to their variety of layout patterns. We propose FormNet, a structure-aware sequence model to mitigate the suboptimal serialization of forms. First, we design Rich Attention that leverages the spatial relationship between tokens in a form for more precise attention score calculation. Second, we construct Super-Tokens for each word by embedding representations from their neighboring tokens through graph convolutions. FormNet therefore explicitly recovers local syntactic information that may have been lost during serialization. In experiments, FormNet outperforms existing methods with a more compact model size and less pre-training data, establishing new state-of-the-art performance on CORD, FUNSD and Payment benchmarks.
Pruning Redundant Mappings in Transformer Models via Spectral-Normalized Identity Prior
Oct 05, 2020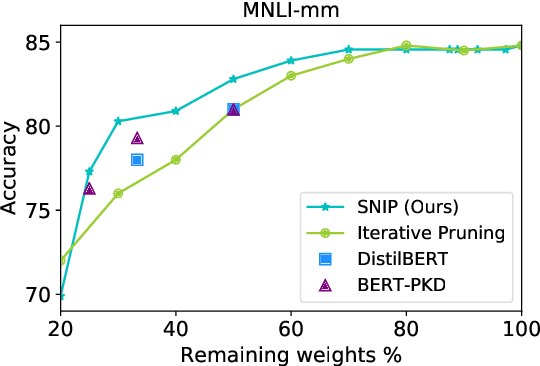
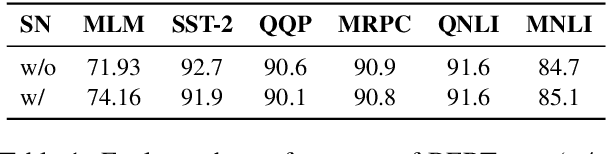
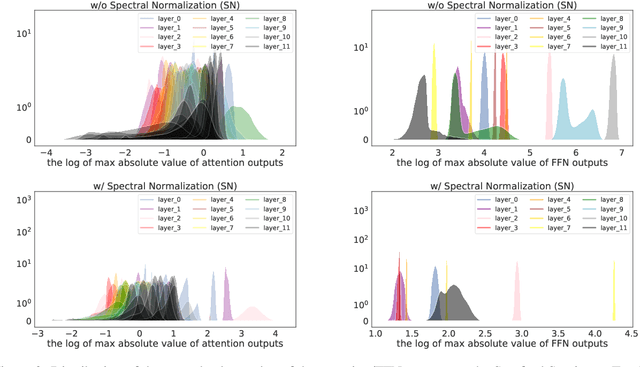
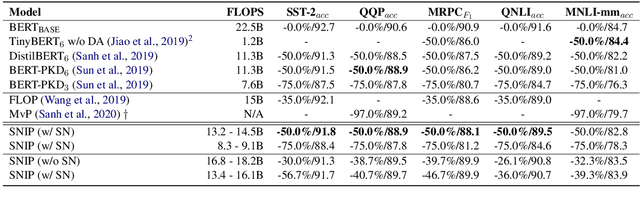
Traditional (unstructured) pruning methods for a Transformer model focus on regularizing the individual weights by penalizing them toward zero. In this work, we explore spectral-normalized identity priors (SNIP), a structured pruning approach that penalizes an entire residual module in a Transformer model toward an identity mapping. Our method identifies and discards unimportant non-linear mappings in the residual connections by applying a thresholding operator on the function norm. It is applicable to any structured module, including a single attention head, an entire attention block, or a feed-forward subnetwork. Furthermore, we introduce spectral normalization to stabilize the distribution of the post-activation values of the Transformer layers, further improving the pruning effectiveness of the proposed methodology. We conduct experiments with BERT on 5 GLUE benchmark tasks to demonstrate that SNIP achieves effective pruning results while maintaining comparable performance. Specifically, we improve the performance over the state-of-the-art by 0.5 to 1.0% on average at 50% compression ratio.
Universal Sentence Encoder
Apr 12, 2018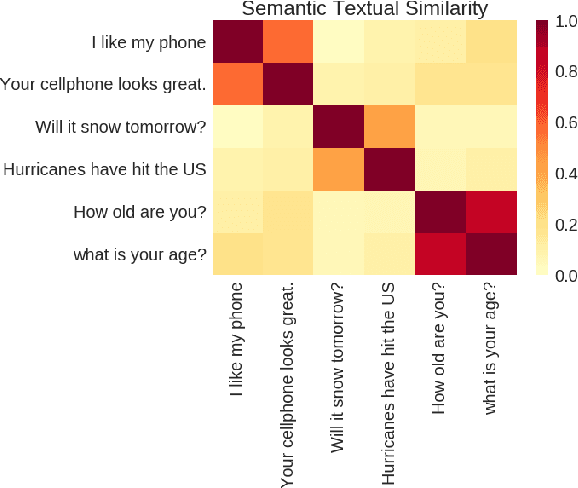
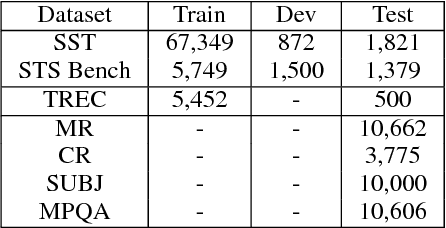
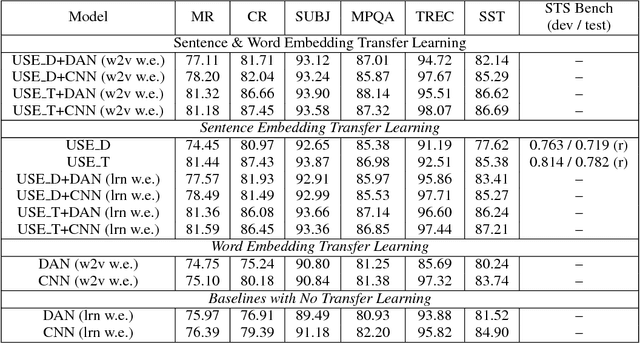
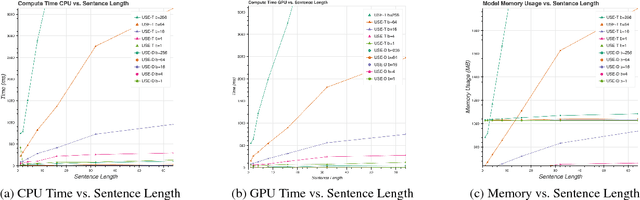
We present models for encoding sentences into embedding vectors that specifically target transfer learning to other NLP tasks. The models are efficient and result in accurate performance on diverse transfer tasks. Two variants of the encoding models allow for trade-offs between accuracy and compute resources. For both variants, we investigate and report the relationship between model complexity, resource consumption, the availability of transfer task training data, and task performance. Comparisons are made with baselines that use word level transfer learning via pretrained word embeddings as well as baselines do not use any transfer learning. We find that transfer learning using sentence embeddings tends to outperform word level transfer. With transfer learning via sentence embeddings, we observe surprisingly good performance with minimal amounts of supervised training data for a transfer task. We obtain encouraging results on Word Embedding Association Tests (WEAT) targeted at detecting model bias. Our pre-trained sentence encoding models are made freely available for download and on TF Hub.