 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
RecurrentGemma: Moving Past Transformers for Efficient Open Language Models
Apr 11, 2024



We introduce RecurrentGemma, an open language model which uses Google's novel Griffin architecture. Griffin combines linear recurrences with local attention to achieve excellent performance on language. It has a fixed-sized state, which reduces memory use and enables efficient inference on long sequences. We provide a pre-trained model with 2B non-embedding parameters, and an instruction tuned variant. Both models achieve comparable performance to Gemma-2B despite being trained on fewer tokens.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models
Feb 29, 2024Recurrent neural networks (RNNs) have fast inference and scale efficiently on long sequences, but they are difficult to train and hard to scale. We propose Hawk, an RNN with gated linear recurrences, and Griffin, a hybrid model that mixes gated linear recurrences with local attention. Hawk exceeds the reported performance of Mamba on downstream tasks, while Griffin matches the performance of Llama-2 despite being trained on over 6 times fewer tokens. We also show that Griffin can extrapolate on sequences significantly longer than those seen during training. Our models match the hardware efficiency of Transformers during training, and during inference they have lower latency and significantly higher throughput. We scale Griffin up to 14B parameters, and explain how to shard our models for efficient distributed training.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Reinforced Self-Training (ReST) for Language Modeling
Aug 21, 2023Reinforcement learning from human feedback (RLHF) can improve the quality of large language model's (LLM) outputs by aligning them with human preferences. We propose a simple algorithm for aligning LLMs with human preferences inspired by growing batch reinforcement learning (RL), which we call Reinforced Self-Training (ReST). Given an initial LLM policy, ReST produces a dataset by generating samples from the policy, which are then used to improve the LLM policy using offline RL algorithms. ReST is more efficient than typical online RLHF methods because the training dataset is produced offline, which allows data reuse. While ReST is a general approach applicable to all generative learning settings, we focus on its application to machine translation. Our results show that ReST can substantially improve translation quality, as measured by automated metrics and human evaluation on machine translation benchmarks in a compute and sample-efficient manner.
AlphaStar Unplugged: Large-Scale Offline Reinforcement Learning
Aug 07, 2023



StarCraft II is one of the most challenging simulated reinforcement learning environments; it is partially observable, stochastic, multi-agent, and mastering StarCraft II requires strategic planning over long time horizons with real-time low-level execution. It also has an active professional competitive scene. StarCraft II is uniquely suited for advancing offline RL algorithms, both because of its challenging nature and because Blizzard has released a massive dataset of millions of StarCraft II games played by human players. This paper leverages that and establishes a benchmark, called AlphaStar Unplugged, introducing unprecedented challenges for offline reinforcement learning. We define a dataset (a subset of Blizzard's release), tools standardizing an API for machine learning methods, and an evaluation protocol. We also present baseline agents, including behavior cloning, offline variants of actor-critic and MuZero. We improve the state of the art of agents using only offline data, and we achieve 90% win rate against previously published AlphaStar behavior cloning agent.
An Empirical Study of Implicit Regularization in Deep Offline RL
Jul 07, 2022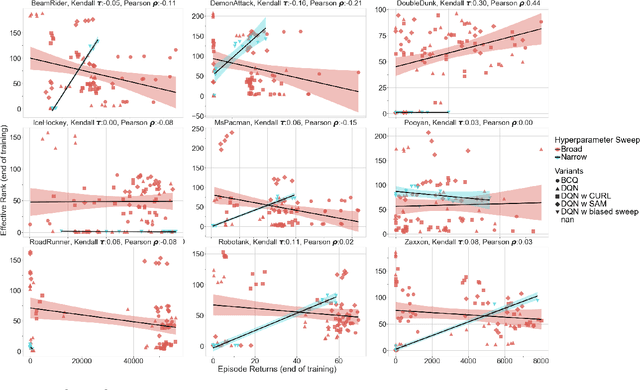

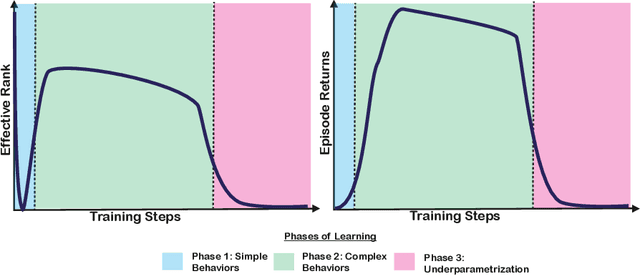

Deep neural networks are the most commonly used function approximators in offline reinforcement learning. Prior works have shown that neural nets trained with TD-learning and gradient descent can exhibit implicit regularization that can be characterized by under-parameterization of these networks. Specifically, the rank of the penultimate feature layer, also called \textit{effective rank}, has been observed to drastically collapse during the training. In turn, this collapse has been argued to reduce the model's ability to further adapt in later stages of learning, leading to the diminished final performance. Such an association between the effective rank and performance makes effective rank compelling for offline RL, primarily for offline policy evaluation. In this work, we conduct a careful empirical study on the relation between effective rank and performance on three offline RL datasets : bsuite, Atari, and DeepMind lab. We observe that a direct association exists only in restricted settings and disappears in the more extensive hyperparameter sweeps. Also, we empirically identify three phases of learning that explain the impact of implicit regularization on the learning dynamics and found that bootstrapping alone is insufficient to explain the collapse of the effective rank. Further, we show that several other factors could confound the relationship between effective rank and performance and conclude that studying this association under simplistic assumptions could be highly misleading.
Output-Constrained Bayesian Neural Networks
May 15, 2019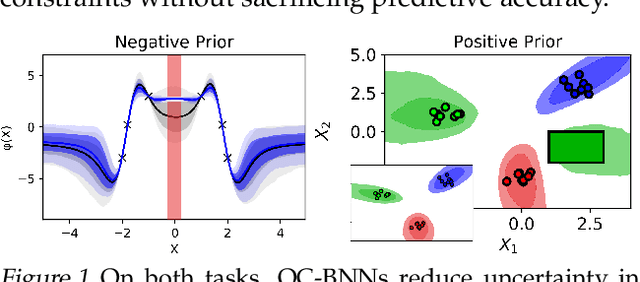
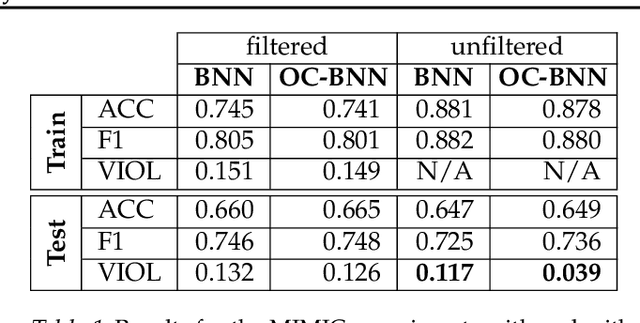
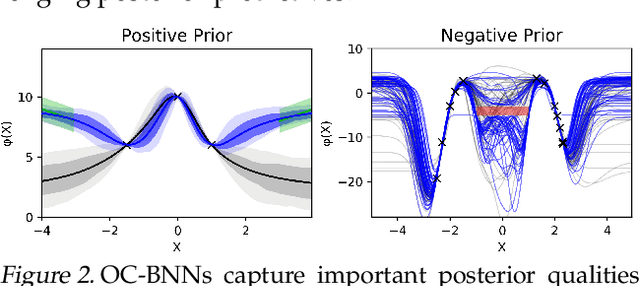
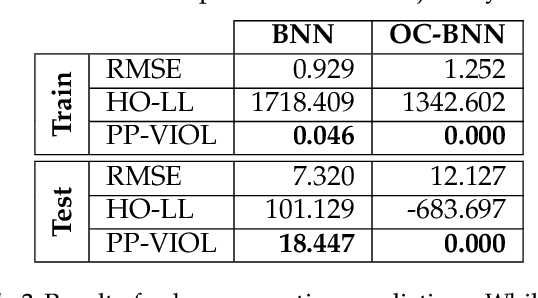
Bayesian neural network (BNN) priors are defined in parameter space, making it hard to encode prior knowledge expressed in function space. We formulate a prior that incorporates functional constraints about what the output can or cannot be in regions of the input space. Output-Constrained BNNs (OC-BNN) represent an interpretable approach of enforcing a range of constraints, fully consistent with the Bayesian framework and amenable to black-box inference. We demonstrate how OC-BNNs improve model robustness and prevent the prediction of infeasible outputs in two real-world applications of healthcare and robotics.
Truly Batch Apprenticeship Learning with Deep Successor Features
Mar 24, 2019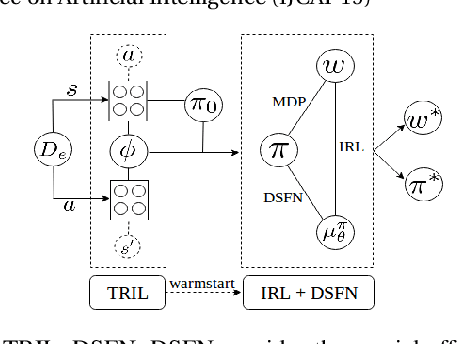
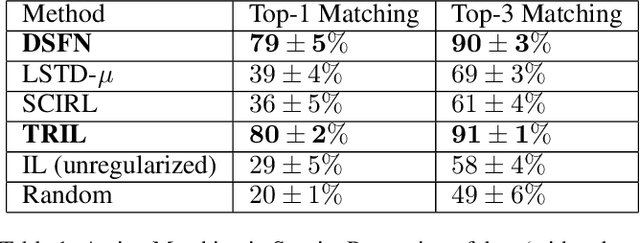
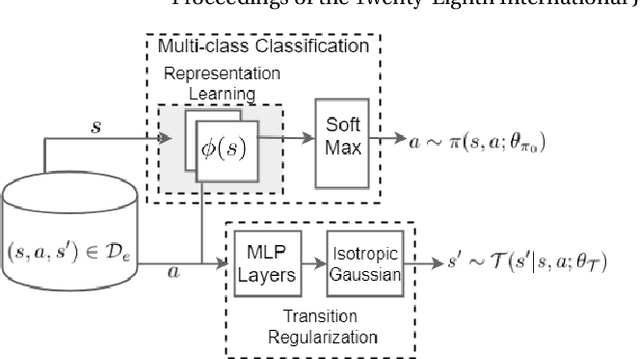
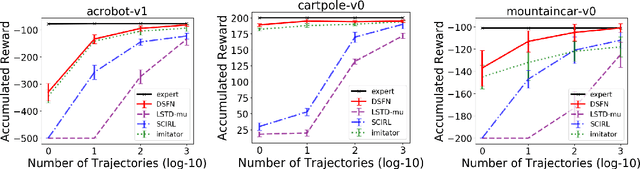
We introduce a novel apprenticeship learning algorithm to learn an expert's underlying reward structure in off-policy model-free \emph{batch} settings. Unlike existing methods that require a dynamics model or additional data acquisition for on-policy evaluation, our algorithm requires only the batch data of observed expert behavior. Such settings are common in real-world tasks---health care, finance or industrial processes ---where accurate simulators do not exist or data acquisition is costly. To address challenges in batch settings, we introduce Deep Successor Feature Networks(DSFN) that estimate feature expectations in an off-policy setting and a transition-regularized imitation network that produces a near-expert initial policy and an efficient feature representation. Our algorithm achieves superior results in batch settings on both control benchmarks and a vital clinical task of sepsis management in the Intensive Care Unit.