 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Apollo: Transferable Architecture Exploration
Feb 02, 2021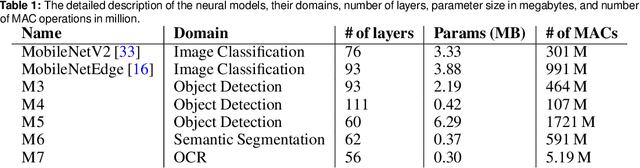
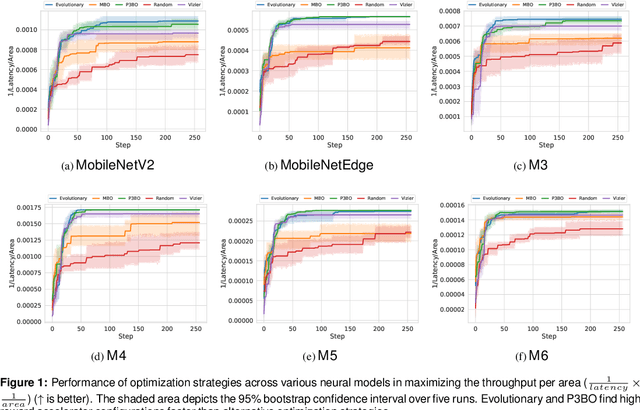

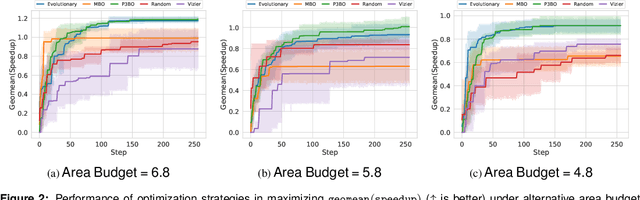
The looming end of Moore's Law and ascending use of deep learning drives the design of custom accelerators that are optimized for specific neural architectures. Architecture exploration for such accelerators forms a challenging constrained optimization problem over a complex, high-dimensional, and structured input space with a costly to evaluate objective function. Existing approaches for accelerator design are sample-inefficient and do not transfer knowledge between related optimizations tasks with different design constraints, such as area and/or latency budget, or neural architecture configurations. In this work, we propose a transferable architecture exploration framework, dubbed Apollo, that leverages recent advances in black-box function optimization for sample-efficient accelerator design. We use this framework to optimize accelerator configurations of a diverse set of neural architectures with alternative design constraints. We show that our framework finds high reward design configurations (up to 24.6% speedup) more sample-efficiently than a baseline black-box optimization approach. We further show that by transferring knowledge between target architectures with different design constraints, Apollo is able to find optimal configurations faster and often with better objective value (up to 25% improvements). This encouraging outcome portrays a promising path forward to facilitate generating higher quality accelerators.
Population-Based Black-Box Optimization for Biological Sequence Design
Jun 05, 2020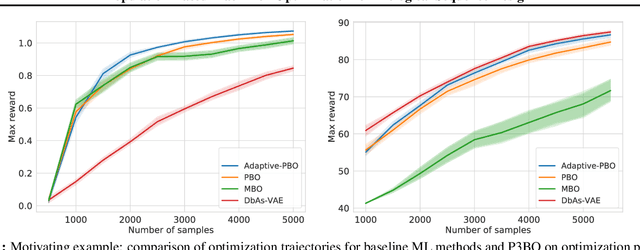
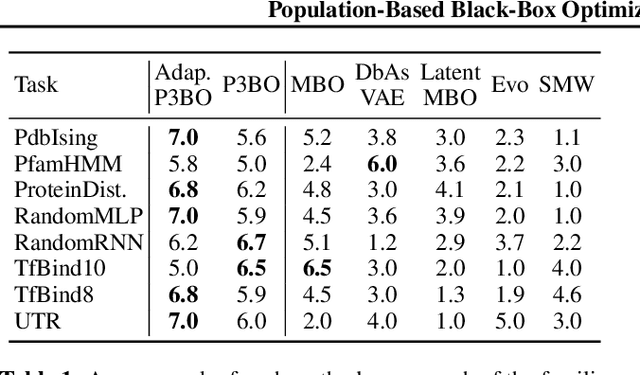
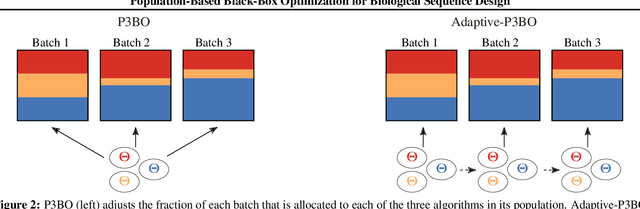
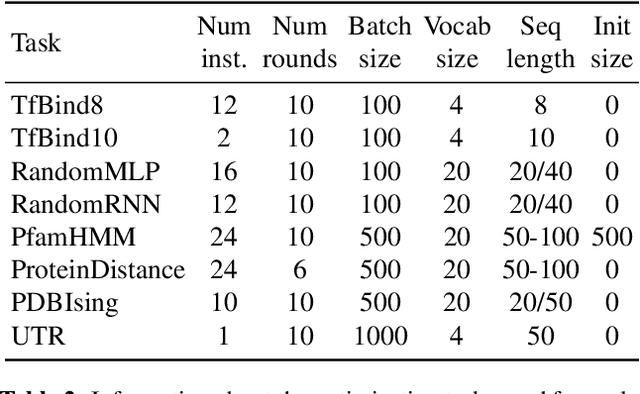
The use of black-box optimization for the design of new biological sequences is an emerging research area with potentially revolutionary impact. The cost and latency of wet-lab experiments requires methods that find good sequences in few experimental rounds of large batches of sequences--a setting that off-the-shelf black-box optimization methods are ill-equipped to handle. We find that the performance of existing methods varies drastically across optimization tasks, posing a significant obstacle to real-world applications. To improve robustness, we propose Population-Based Black-Box Optimization (P3BO), which generates batches of sequences by sampling from an ensemble of methods. The number of sequences sampled from any method is proportional to the quality of sequences it previously proposed, allowing P3BO to combine the strengths of individual methods while hedging against their innate brittleness. Adapting the hyper-parameters of each of the methods online using evolutionary optimization further improves performance. Through extensive experiments on in-silico optimization tasks, we show that P3BO outperforms any single method in its population, proposing higher quality sequences as well as more diverse batches. As such, P3BO and Adaptive-P3BO are a crucial step towards deploying ML to real-world sequence design.
Deep learning for predicting refractive error from retinal fundus images
Dec 21, 2017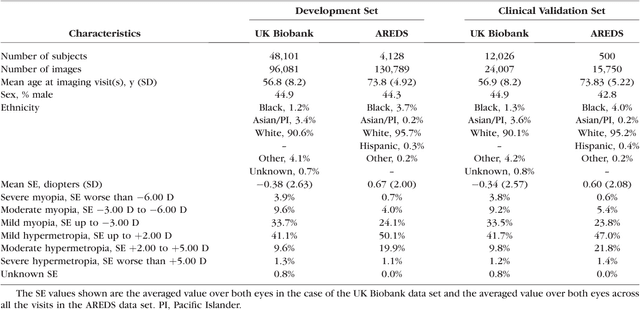
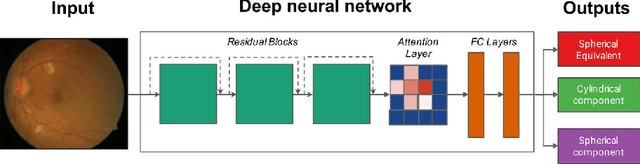
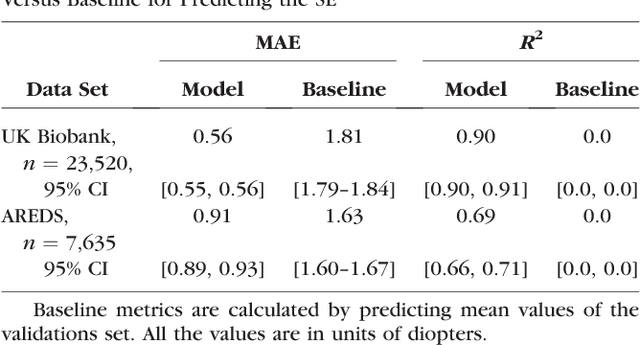
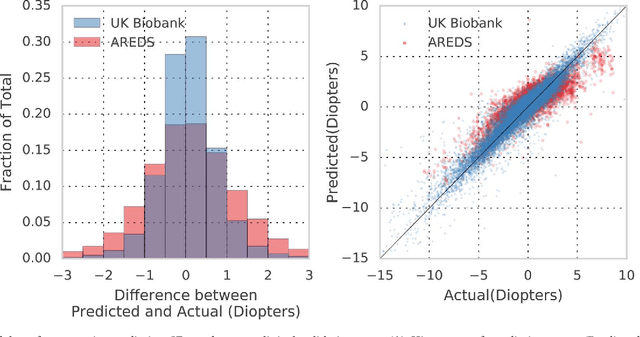
Refractive error, one of the leading cause of visual impairment, can be corrected by simple interventions like prescribing eyeglasses. We trained a deep learning algorithm to predict refractive error from the fundus photographs from participants in the UK Biobank cohort, which were 45 degree field of view images and the AREDS clinical trial, which contained 30 degree field of view images. Our model use the "attention" method to identify features that are correlated with refractive error. Mean absolute error (MAE) of the algorithm's prediction compared to the refractive error obtained in the AREDS and UK Biobank. The resulting algorithm had a MAE of 0.56 diopters (95% CI: 0.55-0.56) for estimating spherical equivalent on the UK Biobank dataset and 0.91 diopters (95% CI: 0.89-0.92) for the AREDS dataset. The baseline expected MAE (obtained by simply predicting the mean of this population) was 1.81 diopters (95% CI: 1.79-1.84) for UK Biobank and 1.63 (95% CI: 1.60-1.67) for AREDS. Attention maps suggested that the foveal region was one of the most important areas used by the algorithm to make this prediction, though other regions also contribute to the prediction. The ability to estimate refractive error with high accuracy from retinal fundus photos has not been previously known and demonstrates that deep learning can be applied to make novel predictions from medical images. Given that several groups have recently shown that it is feasible to obtain retinal fundus photos using mobile phones and inexpensive attachments, this work may be particularly relevant in regions of the world where autorefractors may not be readily available.
Theano: A Python framework for fast computation of mathematical expressions
May 09, 2016



Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.