 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Multi-Agent Design: Optimizing Agents with Better Prompts and Topologies
Feb 04, 2025Large language models, employed as multiple agents that interact and collaborate with each other, have excelled at solving complex tasks. The agents are programmed with prompts that declare their functionality, along with the topologies that orchestrate interactions across agents. Designing prompts and topologies for multi-agent systems (MAS) is inherently complex. To automate the entire design process, we first conduct an in-depth analysis of the design space aiming to understand the factors behind building effective MAS. We reveal that prompts together with topologies play critical roles in enabling more effective MAS design. Based on the insights, we propose Multi-Agent System Search (MASS), a MAS optimization framework that efficiently exploits the complex MAS design space by interleaving its optimization stages, from local to global, from prompts to topologies, over three stages: 1) block-level (local) prompt optimization; 2) workflow topology optimization; 3) workflow-level (global) prompt optimization, where each stage is conditioned on the iteratively optimized prompts/topologies from former stages. We show that MASS-optimized multi-agent systems outperform a spectrum of existing alternatives by a substantial margin. Based on the MASS-found systems, we finally propose design principles behind building effective multi-agent systems.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
A Domain-Agnostic Approach for Characterization of Lifelong Learning Systems
Jan 18, 2023



Despite the advancement of machine learning techniques in recent years, state-of-the-art systems lack robustness to "real world" events, where the input distributions and tasks encountered by the deployed systems will not be limited to the original training context, and systems will instead need to adapt to novel distributions and tasks while deployed. This critical gap may be addressed through the development of "Lifelong Learning" systems that are capable of 1) Continuous Learning, 2) Transfer and Adaptation, and 3) Scalability. Unfortunately, efforts to improve these capabilities are typically treated as distinct areas of research that are assessed independently, without regard to the impact of each separate capability on other aspects of the system. We instead propose a holistic approach, using a suite of metrics and an evaluation framework to assess Lifelong Learning in a principled way that is agnostic to specific domains or system techniques. Through five case studies, we show that this suite of metrics can inform the development of varied and complex Lifelong Learning systems. We highlight how the proposed suite of metrics quantifies performance trade-offs present during Lifelong Learning system development - both the widely discussed Stability-Plasticity dilemma and the newly proposed relationship between Sample Efficient and Robust Learning. Further, we make recommendations for the formulation and use of metrics to guide the continuing development of Lifelong Learning systems and assess their progress in the future.
ALMA: Hierarchical Learning for Composite Multi-Agent Tasks
May 27, 2022

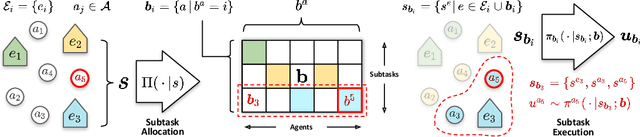
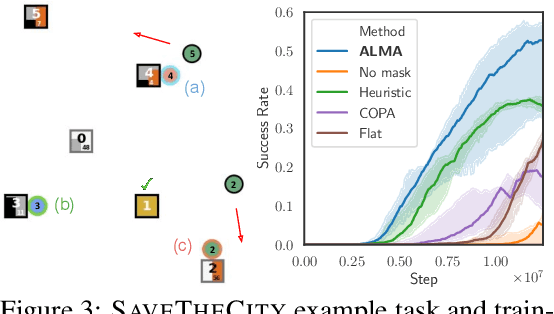
Despite significant progress on multi-agent reinforcement learning (MARL) in recent years, coordination in complex domains remains a challenge. Work in MARL often focuses on solving tasks where agents interact with all other agents and entities in the environment; however, we observe that real-world tasks are often composed of several isolated instances of local agent interactions (subtasks), and each agent can meaningfully focus on one subtask to the exclusion of all else in the environment. In these composite tasks, successful policies can often be decomposed into two levels of decision-making: agents are allocated to specific subtasks and each agent acts productively towards their assigned subtask alone. This decomposed decision making provides a strong structural inductive bias, significantly reduces agent observation spaces, and encourages subtask-specific policies to be reused and composed during training, as opposed to treating each new composition of subtasks as unique. We introduce ALMA, a general learning method for taking advantage of these structured tasks. ALMA simultaneously learns a high-level subtask allocation policy and low-level agent policies. We demonstrate that ALMA learns sophisticated coordination behavior in a number of challenging environments, outperforming strong baselines. ALMA's modularity also enables it to better generalize to new environment configurations. Finally, we find that while ALMA can integrate separately trained allocation and action policies, the best performance is obtained only by training all components jointly.
Possibility Before Utility: Learning And Using Hierarchical Affordances
Mar 23, 2022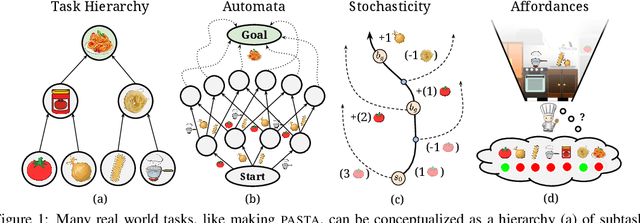
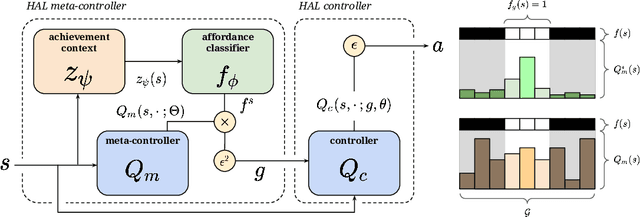
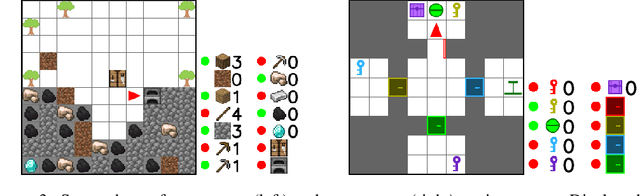
Reinforcement learning algorithms struggle on tasks with complex hierarchical dependency structures. Humans and other intelligent agents do not waste time assessing the utility of every high-level action in existence, but instead only consider ones they deem possible in the first place. By focusing only on what is feasible, or "afforded", at the present moment, an agent can spend more time both evaluating the utility of and acting on what matters. To this end, we present Hierarchical Affordance Learning (HAL), a method that learns a model of hierarchical affordances in order to prune impossible subtasks for more effective learning. Existing works in hierarchical reinforcement learning provide agents with structural representations of subtasks but are not affordance-aware, and by grounding our definition of hierarchical affordances in the present state, our approach is more flexible than the multitude of approaches that ground their subtask dependencies in a symbolic history. While these logic-based methods often require complete knowledge of the subtask hierarchy, our approach is able to utilize incomplete and varying symbolic specifications. Furthermore, we demonstrate that relative to non-affordance-aware methods, HAL agents are better able to efficiently learn complex tasks, navigate environment stochasticity, and acquire diverse skills in the absence of extrinsic supervision -- all of which are hallmarks of human learning.
AI-QMIX: Attention and Imagination for Dynamic Multi-Agent Reinforcement Learning
Jun 07, 2020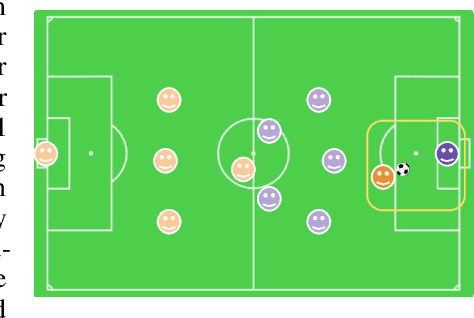

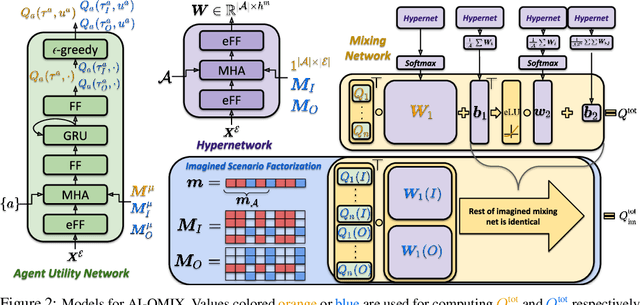
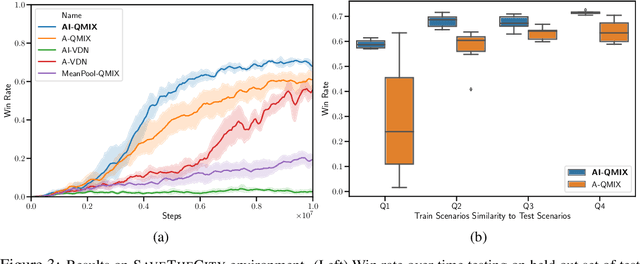
Real world multi-agent tasks often involve varying types and quantities of agents and non-agent entities. Agents frequently do not know a priori how many other agents and non-agent entities they will need to interact with in order to complete a given task, requiring agents to generalize across a combinatorial number of task configurations with each potentially requiring different strategies. In this work, we tackle the problem of multi-agent reinforcement learning (MARL) in such dynamic scenarios. We hypothesize that, while the optimal behaviors in these scenarios with varying quantities and types of agents/entities are diverse, they may share common patterns within sub-teams of agents that are combined to form team behavior. As such, we propose a method that can learn these sub-group relationships and how they can be combined, ultimately improving knowledge sharing and generalization across scenarios. This method, Attentive-Imaginative QMIX, extends QMIX for dynamic MARL in two ways: 1) an attention mechanism that enables model sharing across variable sized scenarios and 2) a training objective that improves learning across scenarios with varying combinations of agent/entity types by factoring the value function into imagined sub-scenarios. We validate our approach on both a novel grid-world task as well as a version of the StarCraft Multi-Agent Challenge minimally modified for the dynamic scenario setting. The results in these domains validate the effectiveness of the two new components in generalizing across dynamic configurations of agents and entities.
Decoupling Adaptation from Modeling with Meta-Optimizers for Meta Learning
Oct 30, 2019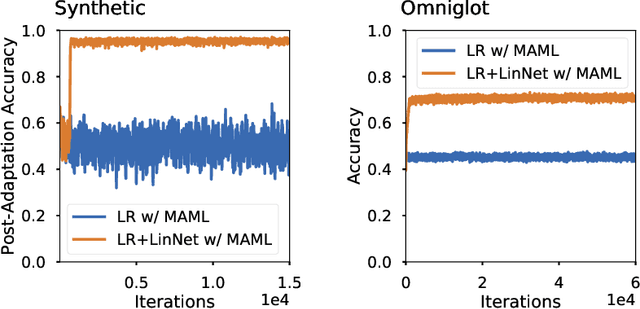

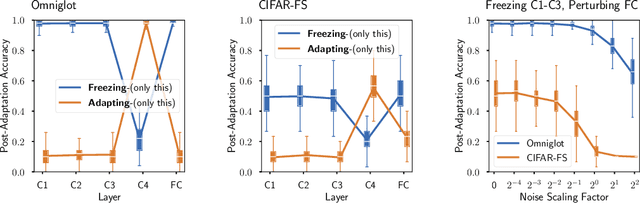

Meta-learning methods, most notably Model-Agnostic Meta-Learning or MAML, have achieved great success in adapting to new tasks quickly, after having been trained on similar tasks. The mechanism behind their success, however, is poorly understood. We begin this work with an experimental analysis of MAML, finding that deep models are crucial for its success, even given sets of simple tasks where a linear model would suffice on any individual task. Furthermore, on image-recognition tasks, we find that the early layers of MAML-trained models learn task-invariant features, while later layers are used for adaptation, providing further evidence that these models require greater capacity than is strictly necessary for their individual tasks. Following our findings, we propose a method which enables better use of model capacity at inference time by separating the adaptation aspect of meta-learning into parameters that are only used for adaptation but are not part of the forward model. We find that our approach enables more effective meta-learning in smaller models, which are suitably sized for the individual tasks.
Directional Semantic Grasping of Real-World Objects: From Simulation to Reality
Sep 04, 2019
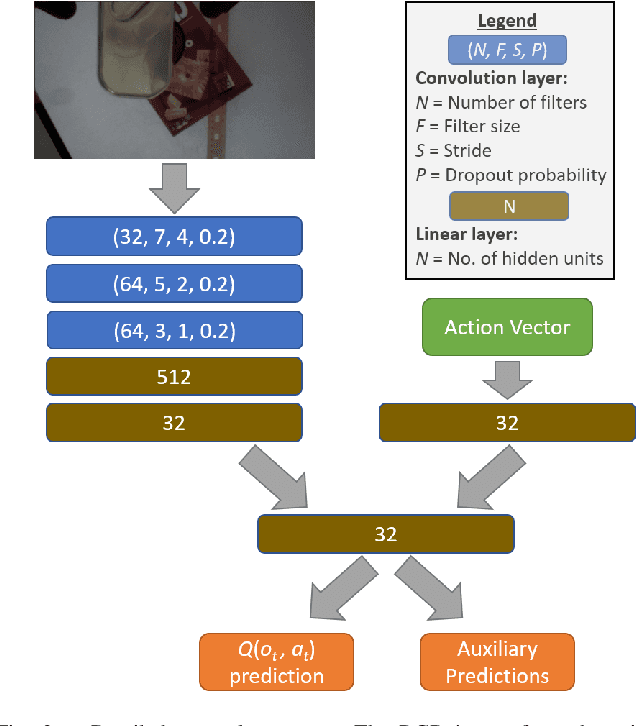


We present a deep reinforcement learning approach to grasp semantically meaningful objects from a particular direction. The system is trained entirely in simulation, with sim-to-real transfer accomplished by using a simulator that models physical contact and produces photorealistic imagery with domain randomized backgrounds. The system is an example of end-to-end (mapping input monocular RGB images to output Cartesian motor commands) grasping of objects from multiple pre-defined object-centric orientations, such as from the side or top. Coupled with a real-time 6-DoF object pose estimator, the eye-in-hand system is capable of grasping objects anywhere within the graspable workspace. Results are shown in both simulation and the real world, demonstrating the effectiveness of the approach.