 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
FLINT: A Platform for Federated Learning Integration
Mar 11, 2023



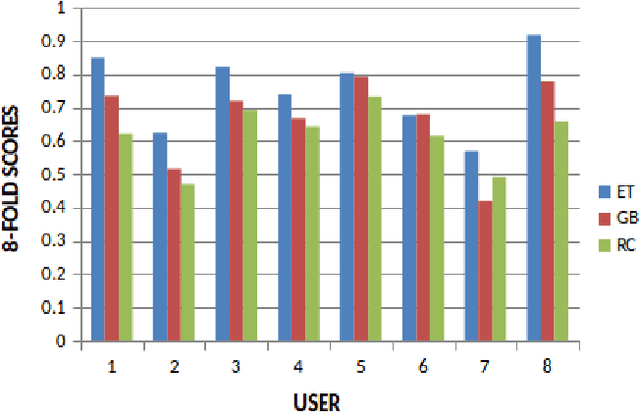
Cross-device federated learning (FL) has been well-studied from algorithmic, system scalability, and training speed perspectives. Nonetheless, moving from centralized training to cross-device FL for millions or billions of devices presents many risks, including performance loss, developer inertia, poor user experience, and unexpected application failures. In addition, the corresponding infrastructure, development costs, and return on investment are difficult to estimate. In this paper, we present a device-cloud collaborative FL platform that integrates with an existing machine learning platform, providing tools to measure real-world constraints, assess infrastructure capabilities, evaluate model training performance, and estimate system resource requirements to responsibly bring FL into production. We also present a decision workflow that leverages the FL-integrated platform to comprehensively evaluate the trade-offs of cross-device FL and share our empirical evaluations of business-critical machine learning applications that impact hundreds of millions of users.
Bridging the Generalization Gap: Training Robust Models on Confounded Biological Data
Dec 12, 2018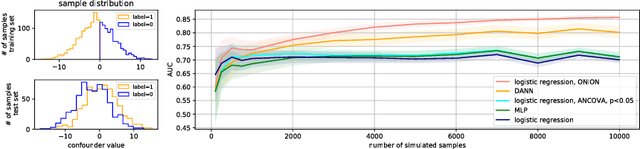
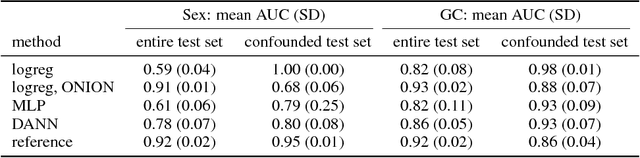
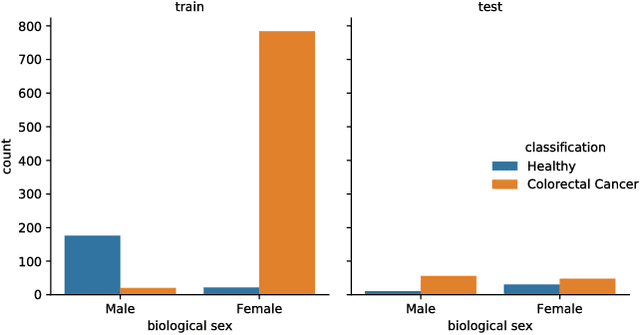
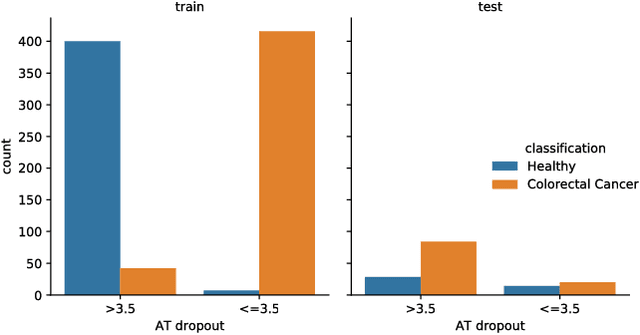
Statistical learning on biological data can be challenging due to confounding variables in sample collection and processing. Confounders can cause models to generalize poorly and result in inaccurate prediction performance metrics if models are not validated thoroughly. In this paper, we propose methods to control for confounding factors and further improve prediction performance. We introduce OrthoNormal basis construction In cOnfounding factor Normalization (ONION) to remove confounding covariates and use the Domain-Adversarial Neural Network (DANN) to penalize models for encoding confounder information. We apply the proposed methods to simulated and empirical patient data and show significant improvements in generalization.
A Generic Multi-modal Dynamic Gesture Recognition System using Machine Learning
Sep 16, 2018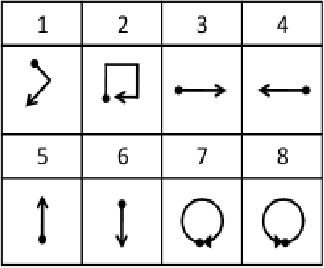
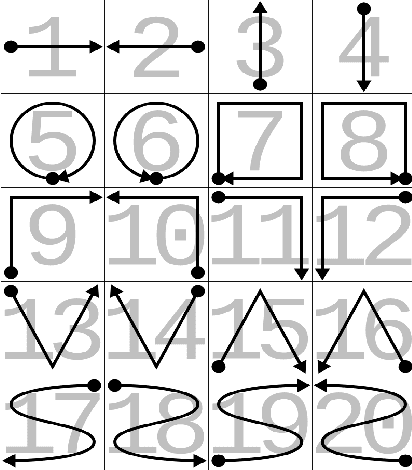

Human computer interaction facilitates intelligent communication between humans and computers, in which gesture recognition plays a prominent role. This paper proposes a machine learning system to identify dynamic gestures using tri-axial acceleration data acquired from two public datasets. These datasets, uWave and Sony, were acquired using accelerometers embedded in Wii remotes and smartwatches, respectively. A dynamic gesture signed by the user is characterized by a generic set of features extracted across time and frequency domains. The system was analyzed from an end-user perspective and was modelled to operate in three modes. The modes of operation determine the subsets of data to be used for training and testing the system. From an initial set of seven classifiers, three were chosen to evaluate each dataset across all modes rendering the system towards mode-neutrality and dataset-independence. The proposed system is able to classify gestures performed at varying speeds with minimum preprocessing, making it computationally efficient. Moreover, this system was found to run on a low-cost embedded platform - Raspberry Pi Zero (USD 5), making it economically viable.
Deep Voice 3: Scaling Text-to-Speech with Convolutional Sequence Learning
Feb 22, 2018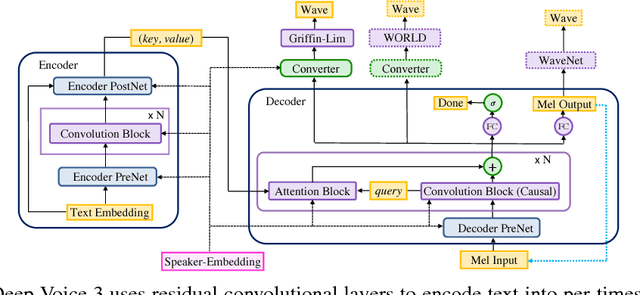

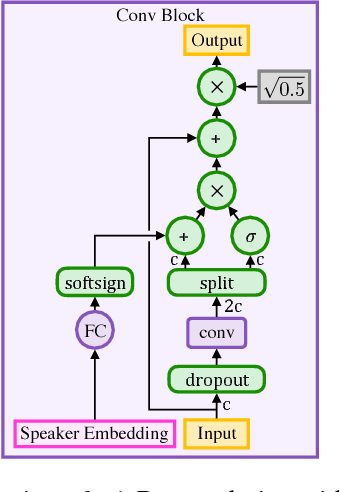
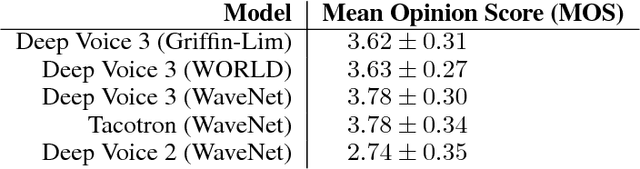
We present Deep Voice 3, a fully-convolutional attention-based neural text-to-speech (TTS) system. Deep Voice 3 matches state-of-the-art neural speech synthesis systems in naturalness while training ten times faster. We scale Deep Voice 3 to data set sizes unprecedented for TTS, training on more than eight hundred hours of audio from over two thousand speakers. In addition, we identify common error modes of attention-based speech synthesis networks, demonstrate how to mitigate them, and compare several different waveform synthesis methods. We also describe how to scale inference to ten million queries per day on one single-GPU server.
Reducing Bias in Production Speech Models
May 11, 2017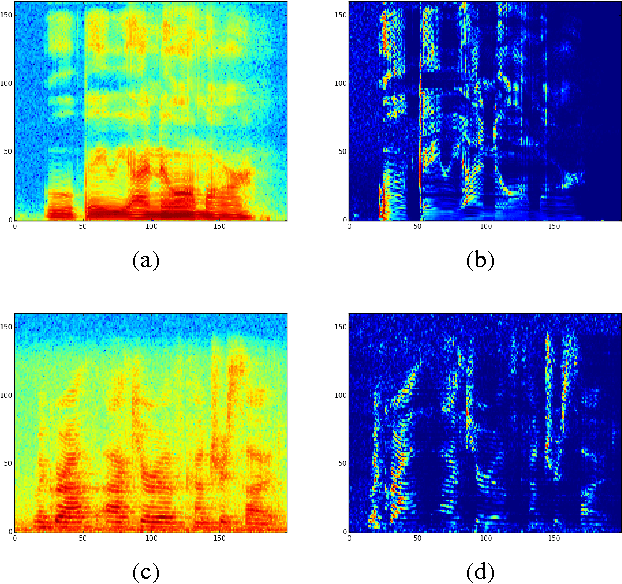
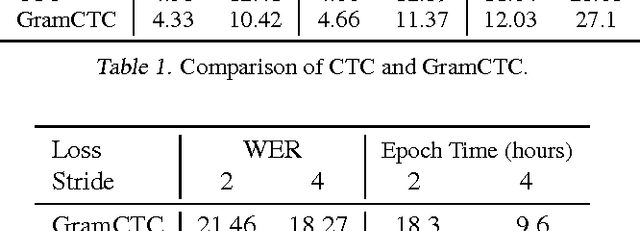
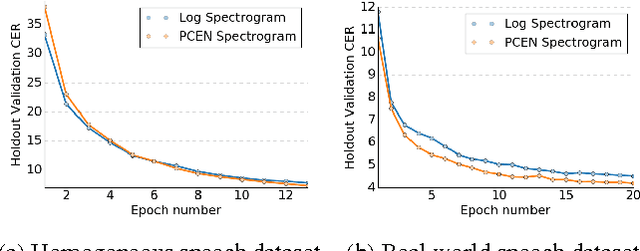
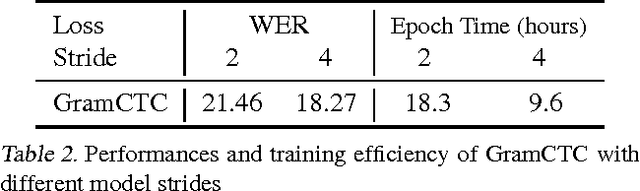
Replacing hand-engineered pipelines with end-to-end deep learning systems has enabled strong results in applications like speech and object recognition. However, the causality and latency constraints of production systems put end-to-end speech models back into the underfitting regime and expose biases in the model that we show cannot be overcome by "scaling up", i.e., training bigger models on more data. In this work we systematically identify and address sources of bias, reducing error rates by up to 20% while remaining practical for deployment. We achieve this by utilizing improved neural architectures for streaming inference, solving optimization issues, and employing strategies that increase audio and label modelling versatility.
Deep Speaker: an End-to-End Neural Speaker Embedding System
May 05, 2017
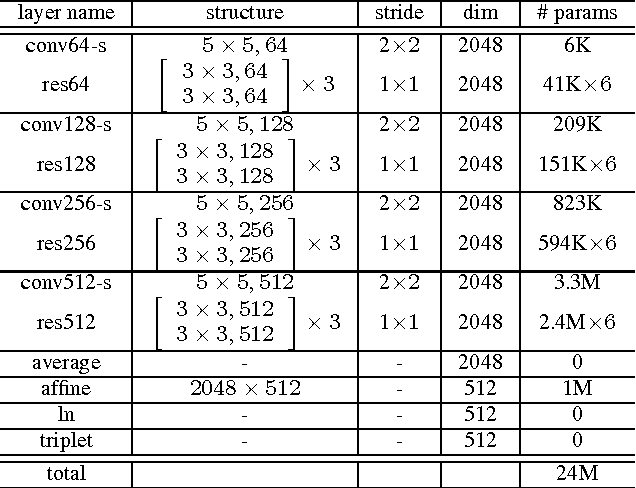
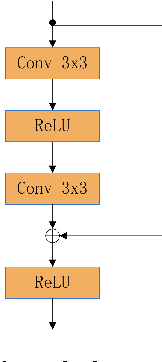
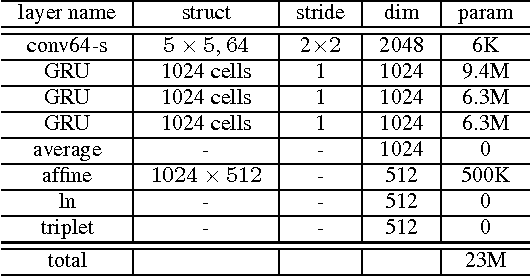
We present Deep Speaker, a neural speaker embedding system that maps utterances to a hypersphere where speaker similarity is measured by cosine similarity. The embeddings generated by Deep Speaker can be used for many tasks, including speaker identification, verification, and clustering. We experiment with ResCNN and GRU architectures to extract the acoustic features, then mean pool to produce utterance-level speaker embeddings, and train using triplet loss based on cosine similarity. Experiments on three distinct datasets suggest that Deep Speaker outperforms a DNN-based i-vector baseline. For example, Deep Speaker reduces the verification equal error rate by 50% (relatively) and improves the identification accuracy by 60% (relatively) on a text-independent dataset. We also present results that suggest adapting from a model trained with Mandarin can improve accuracy for English speaker recognition.
Automated Attribution and Intertextual Analysis
May 03, 2014
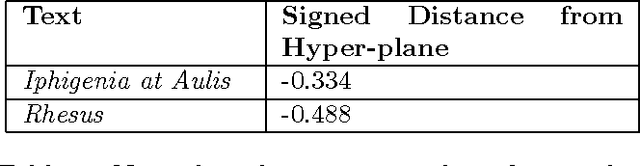


In this work, we employ quantitative methods from the realm of statistics and machine learning to develop novel methodologies for author attribution and textual analysis. In particular, we develop techniques and software suitable for applications to Classical study, and we illustrate the efficacy of our approach in several interesting open questions in the field. We apply our numerical analysis techniques to questions of authorship attribution in the case of the Greek tragedian Euripides, to instances of intertextuality and influence in the poetry of the Roman statesman Seneca the Younger, and to cases of "interpolated" text with respect to the histories of Livy.