 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHARBOR: Holistic Adaptive Risk assessment model for BehaviORal healthcare
Dec 21, 2025Behavioral healthcare risk assessment remains a challenging problem due to the highly multimodal nature of patient data and the temporal dynamics of mood and affective disorders. While large language models (LLMs) have demonstrated strong reasoning capabilities, their effectiveness in structured clinical risk scoring remains unclear. In this work, we introduce HARBOR, a behavioral health aware language model designed to predict a discrete mood and risk score, termed the Harbor Risk Score (HRS), on an integer scale from -3 (severe depression) to +3 (mania). We also release PEARL, a longitudinal behavioral healthcare dataset spanning four years of monthly observations from three patients, containing physiological, behavioral, and self reported mental health signals. We benchmark traditional machine learning models, proprietary LLMs, and HARBOR across multiple evaluation settings and ablations. Our results show that HARBOR outperforms classical baselines and off the shelf LLMs, achieving 69 percent accuracy compared to 54 percent for logistic regression and 29 percent for the strongest proprietary LLM baseline.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Reinforced Self-Training (ReST) for Language Modeling
Aug 21, 2023Reinforcement learning from human feedback (RLHF) can improve the quality of large language model's (LLM) outputs by aligning them with human preferences. We propose a simple algorithm for aligning LLMs with human preferences inspired by growing batch reinforcement learning (RL), which we call Reinforced Self-Training (ReST). Given an initial LLM policy, ReST produces a dataset by generating samples from the policy, which are then used to improve the LLM policy using offline RL algorithms. ReST is more efficient than typical online RLHF methods because the training dataset is produced offline, which allows data reuse. While ReST is a general approach applicable to all generative learning settings, we focus on its application to machine translation. Our results show that ReST can substantially improve translation quality, as measured by automated metrics and human evaluation on machine translation benchmarks in a compute and sample-efficient manner.
SEAHORSE: A Multilingual, Multifaceted Dataset for Summarization Evaluation
May 22, 2023



Reliable automatic evaluation of summarization systems is challenging due to the multifaceted and subjective nature of the task. This is especially the case for languages other than English, where human evaluations are scarce. In this work, we introduce SEAHORSE, a dataset for multilingual, multifaceted summarization evaluation. SEAHORSE consists of 96K summaries with human ratings along 6 quality dimensions: comprehensibility, repetition, grammar, attribution, main ideas, and conciseness, covering 6 languages, 9 systems and 4 datasets. As a result of its size and scope, SEAHORSE can serve both as a benchmark to evaluate learnt metrics, as well as a large-scale resource for training such metrics. We show that metrics trained with SEAHORSE achieve strong performance on the out-of-domain meta-evaluation benchmarks TRUE (Honovich et al., 2022) and mFACE (Aharoni et al., 2022). We make SEAHORSE publicly available for future research on multilingual and multifaceted summarization evaluation.
Dialect-robust Evaluation of Generated Text
Nov 02, 2022



Evaluation metrics that are not robust to dialect variation make it impossible to tell how well systems perform for many groups of users, and can even penalize systems for producing text in lower-resource dialects. However, currently, there exists no way to quantify how metrics respond to change in the dialect of a generated utterance. We thus formalize dialect robustness and dialect awareness as goals for NLG evaluation metrics. We introduce a suite of methods and corresponding statistical tests one can use to assess metrics in light of the two goals. Applying the suite to current state-of-the-art metrics, we demonstrate that they are not dialect-robust and that semantic perturbations frequently lead to smaller decreases in a metric than the introduction of dialect features. As a first step to overcome this limitation, we propose a training schema, NANO, which introduces regional and language information to the pretraining process of a metric. We demonstrate that NANO provides a size-efficient way for models to improve the dialect robustness while simultaneously improving their performance on the standard metric benchmark.
Building Machine Translation Systems for the Next Thousand Languages
May 16, 2022

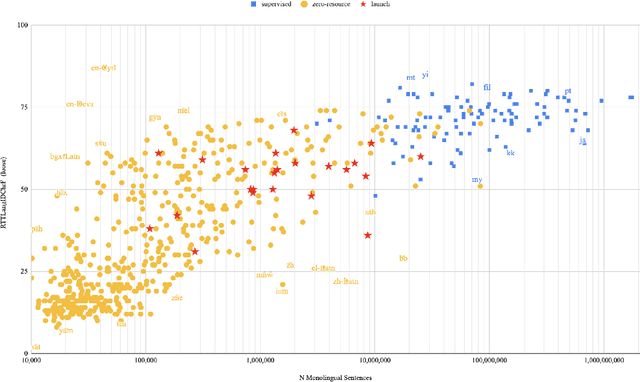
In this paper we share findings from our effort to build practical machine translation (MT) systems capable of translating across over one thousand languages. We describe results in three research domains: (i) Building clean, web-mined datasets for 1500+ languages by leveraging semi-supervised pre-training for language identification and developing data-driven filtering techniques; (ii) Developing practical MT models for under-served languages by leveraging massively multilingual models trained with supervised parallel data for over 100 high-resource languages and monolingual datasets for an additional 1000+ languages; and (iii) Studying the limitations of evaluation metrics for these languages and conducting qualitative analysis of the outputs from our MT models, highlighting several frequent error modes of these types of models. We hope that our work provides useful insights to practitioners working towards building MT systems for currently understudied languages, and highlights research directions that can complement the weaknesses of massively multilingual models in data-sparse settings.
Towards the Next 1000 Languages in Multilingual Machine Translation: Exploring the Synergy Between Supervised and Self-Supervised Learning
Jan 13, 2022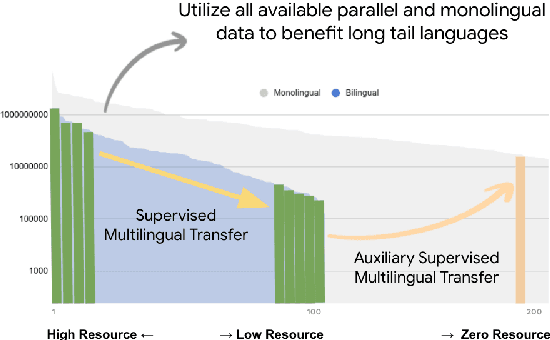
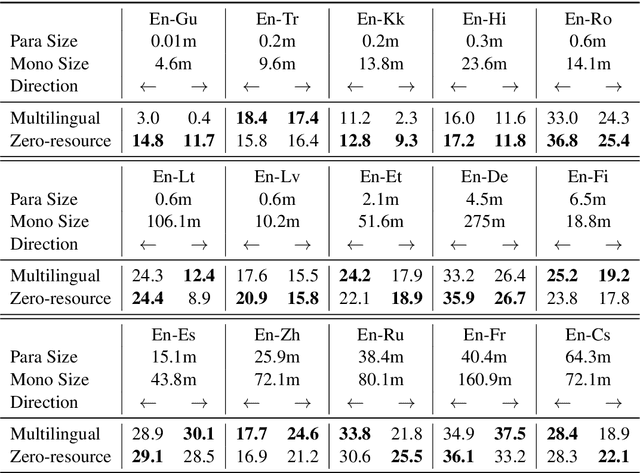
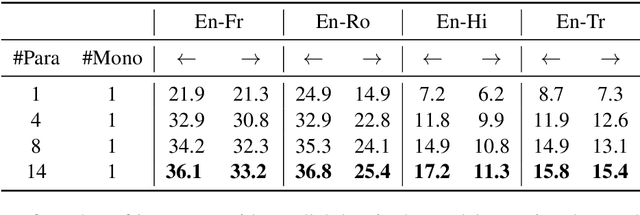
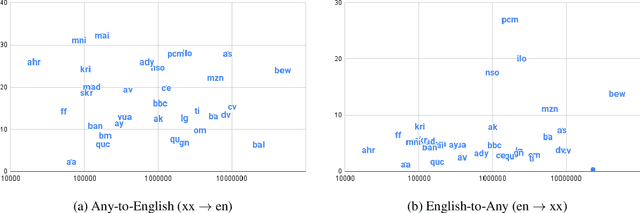
Achieving universal translation between all human language pairs is the holy-grail of machine translation (MT) research. While recent progress in massively multilingual MT is one step closer to reaching this goal, it is becoming evident that extending a multilingual MT system simply by training on more parallel data is unscalable, since the availability of labeled data for low-resource and non-English-centric language pairs is forbiddingly limited. To this end, we present a pragmatic approach towards building a multilingual MT model that covers hundreds of languages, using a mixture of supervised and self-supervised objectives, depending on the data availability for different language pairs. We demonstrate that the synergy between these two training paradigms enables the model to produce high-quality translations in the zero-resource setting, even surpassing supervised translation quality for low- and mid-resource languages. We conduct a wide array of experiments to understand the effect of the degree of multilingual supervision, domain mismatches and amounts of parallel and monolingual data on the quality of our self-supervised multilingual models. To demonstrate the scalability of the approach, we train models with over 200 languages and demonstrate high performance on zero-resource translation on several previously under-studied languages. We hope our findings will serve as a stepping stone towards enabling translation for the next thousand languages.
DOCmT5: Document-Level Pretraining of Multilingual Language Models
Dec 16, 2021
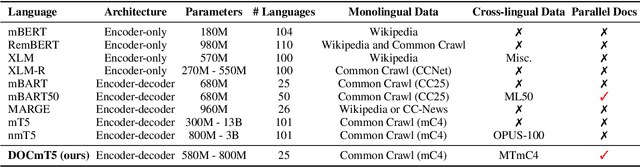

In this paper, we introduce DOCmT5, a multilingual sequence-to-sequence language model pre-trained with large scale parallel documents. While previous approaches have focused on leveraging sentence-level parallel data, we try to build a general-purpose pre-trained model that can understand and generate long documents. We propose a simple and effective pre-training objective - Document Reordering Machine Translation (DrMT), in which the input documents that are shuffled and masked need to be translated. DrMT brings consistent improvements over strong baselines on a variety of document-level generation tasks, including over 12 BLEU points for seen-language-pair document-level MT, over 7 BLEU points for unseen-language-pair document-level MT and over 3 ROUGE-1 points for seen-language-pair cross-lingual summarization. We achieve state-of-the-art (SOTA) on WMT20 De-En and IWSLT15 Zh-En document translation tasks. We also conduct extensive analysis on various factors for document pre-training, including (1) the effects of pre-training data quality and (2) The effects of combining mono-lingual and cross-lingual pre-training. We plan to make our model checkpoints publicly available.
nmT5 -- Is parallel data still relevant for pre-training massively multilingual language models?
Jun 03, 2021
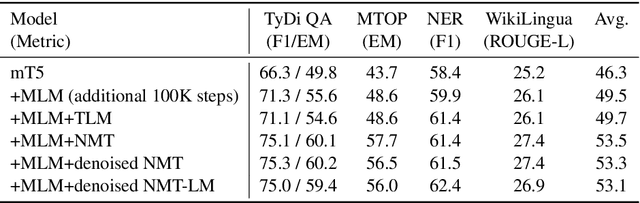
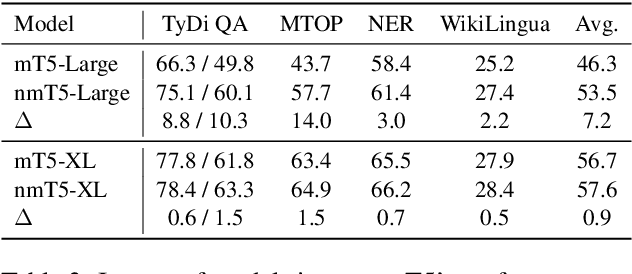
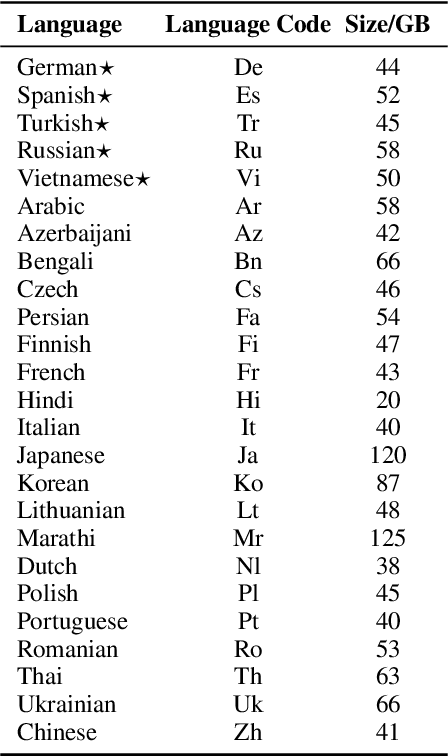
Recently, mT5 - a massively multilingual version of T5 - leveraged a unified text-to-text format to attain state-of-the-art results on a wide variety of multilingual NLP tasks. In this paper, we investigate the impact of incorporating parallel data into mT5 pre-training. We find that multi-tasking language modeling with objectives such as machine translation during pre-training is a straightforward way to improve performance on downstream multilingual and cross-lingual tasks. However, the gains start to diminish as the model capacity increases, suggesting that parallel data might not be as essential for larger models. At the same time, even at larger model sizes, we find that pre-training with parallel data still provides benefits in the limited labelled data regime.