 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Discovery of New Behaviors using Diffusion Policies
Jun 07, 2026Diffusion models have become a powerful tool for generative modeling in robotics, with diffusion policies excelling at modeling multimodal action-trajectory distributions. However, when demonstrations are limited, standard sampling often reproduces dominant behaviors while neglecting valid but rare modes, limiting the discovery of novel solutions. Existing approaches, such as guidance methods or combining reinforcement learning with diffusion, either push samples into infeasible regions or struggle to escape local minima, failing to systematically uncover diverse behaviors. To address these challenges, we propose a framework that combines Feynman-Kac correctors with a novel guiding potential that systematically guides diffusion policy samples towards promising yet underrepresented samples. These trajectories are refined using sampling-based trajectory optimization and reincorporated into the training set to retrain the diffusion policy. Our method effectively mines and repairs novel trajectories, enabling the systematic discovery of diverse and executable behaviors. We demonstrate the effectiveness of our framework across a range of manipulation environments, consistently discovering new behaviors.
Learning to Build the Environment: Self-Evolving Reasoning RL via Verifiable Environment Synthesis
May 14, 2026We pursue a vision for self-improving language models in which the model does not merely generate problems or traces to imitate, but constructs the environments that train it. In zero-data reasoning RL, this reframes self-improvement from a data-generation loop into an environment-construction loop, where each artifact is a reusable executable object that samples instances, computes references, and scores responses. Whether this vision sustains improvement hinges on a single property: the environments must exhibit stable solve--verify asymmetry, the model must be able to write an oracle once that it cannot reliably execute in natural language on fresh instances. This asymmetry takes two complementary forms. Some tasks are algorithmically hard to reason through but trivial as code: a dynamic program or graph traversal, compiled once, yields unboundedly many calibrated instances. Others are intrinsically hard to solve but easy to verify, like planted subset-sum or constraint satisfaction. Both create a durable gap between proposing and solving that the policy cannot close by gaming the verifier, and it is this gap that keeps reward informative as the learner improves. We instantiate this view in EvoEnv, a single-policy generator, solver method that synthesizes Python environments from ten seeds and admits them only after staged validation, semantic self-review, solver-relative difficulty calibration, and novelty checks. The strongest evidence comes from the already-strong regime: on Qwen3-4B-Thinking, fixed public-data RLVR and fixed hand-crafted environment RLVR reduce the average, while EvoEnv improves it from 72.4 to 74.8, a relative gain of 3.3%. Stable self-improvement, we suggest, depends not on producing more synthetic data, but on models learning to construct worlds whose difficulty stays structurally beyond their own reach.
Reinforcing Multimodal Reasoning Against Visual Degradation
May 10, 2026Reinforcement Learning has significantly advanced the reasoning capabilities of Multimodal Large Language Models (MLLMs), yet the resulting policies remain brittle against real-world visual degradations such as blur, compression artifacts, and low-resolution scans. Prior robustness techniques from vision and deep RL rely on static data augmentation or value-based regularization, neither of which transfers cleanly to critic-free RL fine-tuning of autoregressive MLLMs. Reinforcing reasoning against such corruptions is non-trivial: naively injecting degraded views during rollout induces reward poisoning, where perceptual occlusions trigger hallucinated trajectories and destabilize optimization. We propose ROMA, an RL fine-tuning framework that modifies the optimization dynamics to reinforce reasoning against visual degradation while preserving clean-input performance. A dual-forward-pass strategy uses teacher forcing to evaluate corrupted views against clean-image trajectories, avoiding new rollouts on degraded inputs. For distributional consistency, we apply a token-level surrogate KL penalty against the worst-case augmentation; to prevent policy collapse under regularization, an auxiliary policy gradient loss anchored to clean-image advantages preserves a reliable reward signal; and to avoid systematically incorrect invariance, correctness-conditioned regularization restricts enforcement to successful trajectories. On Qwen3-VL 4B/8B across seven multimodal reasoning benchmarks, our method improves robustness by +2.4% on seen and +2.3% on unseen corruptions over GRPO while matching clean accuracy.
DeltaRubric: Generative Multimodal Reward Modeling via Joint Planning and Verification
May 10, 2026Aligning Multimodal Large Language Models (MLLMs) requires reliable reward models, yet existing single-step evaluators can suffer from lazy judging, exploiting language priors over fine-grained visual verification. While rubric-based evaluation mitigates these biases in text-only settings, extending it to multimodal tasks is bottlenecked by the complexity of visual reasoning. The critical differences between responses often depend on instance-specific visual details. Robust evaluation requires dynamically synthesizing rubrics that isolate spatial and factual discrepancies. To address this, we introduce $\textbf{DeltaRubric}$, an approach that reformulates multimodal preference evaluation as a plan-and-execute process within a single MLLM. DeltaRubric operates in two steps: acting first as a $\textit{Disagreement Planner}$, the model generates a neutral, instance-specific verification checklist. Transitioning into a $\textit{Checklist Verifier}$, it executes these self-generated checks against the image and question to produce the final grounded judgment. We formulate DeltaRubric as a multi-role reinforcement learning problem, jointly optimizing planning and verification capabilities. Validated on Qwen3-VL 4B and 8B Instruct models, DeltaRubric achieves solid empirical gains. For instance, On VL-RewardBench, it improves base model overall accuracy by $\textbf{+22.6}$ (4B) and $\textbf{+18.8}$ (8B) points, largely outperforming standard no-rubric baselines. The results demonstrate that decomposing evaluation into structured, verifiable steps leads to more reliable and generalizable multimodal reward modeling.
DynaRetarget: Dynamically-Feasible Retargeting using Sampling-Based Trajectory Optimization
Feb 06, 2026In this paper, we introduce DynaRetarget, a complete pipeline for retargeting human motions to humanoid control policies. The core component of DynaRetarget is a novel Sampling-Based Trajectory Optimization (SBTO) framework that refines imperfect kinematic trajectories into dynamically feasible motions. SBTO incrementally advances the optimization horizon, enabling optimization over the entire trajectory for long-horizon tasks. We validate DynaRetarget by successfully retargeting hundreds of humanoid-object demonstrations and achieving higher success rates than the state of the art. The framework also generalizes across varying object properties, such as mass, size, and geometry, using the same tracking objective. This ability to robustly retarget diverse demonstrations opens the door to generating large-scale synthetic datasets of humanoid loco-manipulation trajectories, addressing a major bottleneck in real-world data collection.
Save the Good Prefix: Precise Error Penalization via Process-Supervised RL to Enhance LLM Reasoning
Jan 26, 2026Reinforcement learning (RL) has emerged as a powerful framework for improving the reasoning capabilities of large language models (LLMs). However, most existing RL approaches rely on sparse outcome rewards, which fail to credit correct intermediate steps in partially successful solutions. Process reward models (PRMs) offer fine-grained step-level supervision, but their scores are often noisy and difficult to evaluate. As a result, recent PRM benchmarks focus on a more objective capability: detecting the first incorrect step in a reasoning path. However, this evaluation target is misaligned with how PRMs are typically used in RL, where their step-wise scores are treated as raw rewards to maximize. To bridge this gap, we propose Verifiable Prefix Policy Optimization (VPPO), which uses PRMs only to localize the first error during RL. Given an incorrect rollout, VPPO partitions the trajectory into a verified correct prefix and an erroneous suffix based on the first error, rewarding the former while applying targeted penalties only after the detected mistake. This design yields stable, interpretable learning signals and improves credit assignment. Across multiple reasoning benchmarks, VPPO consistently outperforms sparse-reward RL and prior PRM-guided baselines on both Pass@1 and Pass@K.
Stable and Efficient Single-Rollout RL for Multimodal Reasoning
Dec 20, 2025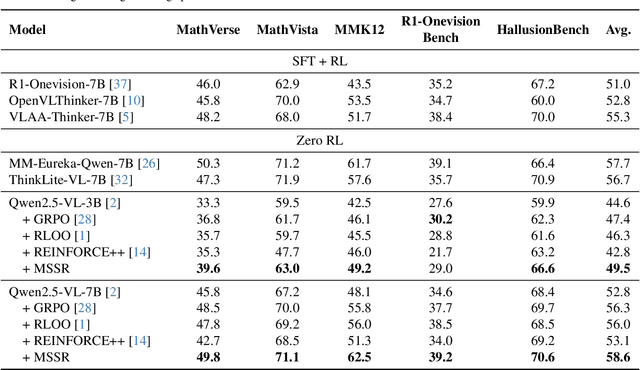
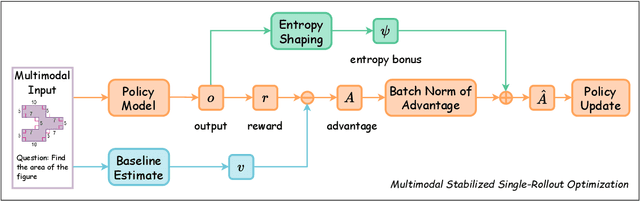

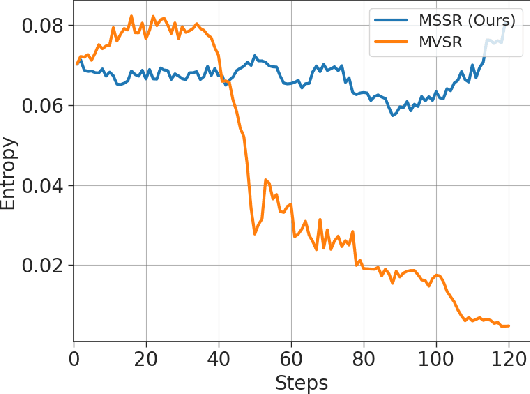
Reinforcement Learning with Verifiable Rewards (RLVR) has become a key paradigm to improve the reasoning capabilities of Multimodal Large Language Models (MLLMs). However, prevalent group-based algorithms such as GRPO require multi-rollout sampling for each prompt. While more efficient single-rollout variants have recently been explored in text-only settings, we find that they suffer from severe instability in multimodal contexts, often leading to training collapse. To address this training efficiency-stability trade-off, we introduce $\textbf{MSSR}$ (Multimodal Stabilized Single-Rollout), a group-free RLVR framework that achieves both stable optimization and effective multimodal reasoning performance. MSSR achieves this via an entropy-based advantage-shaping mechanism that adaptively regularizes advantage magnitudes, preventing collapse and maintaining training stability. While such mechanisms have been used in group-based RLVR, we show that in the multimodal single-rollout setting they are not merely beneficial but essential for stability. In in-distribution evaluations, MSSR demonstrates superior training compute efficiency, achieving similar validation accuracy to the group-based baseline with half the training steps. When trained for the same number of steps, MSSR's performance surpasses the group-based baseline and shows consistent generalization improvements across five diverse reasoning-intensive benchmarks. Together, these results demonstrate that MSSR enables stable, compute-efficient, and effective RLVR for complex multimodal reasoning tasks.
CLUE: Non-parametric Verification from Experience via Hidden-State Clustering
Oct 02, 2025



Assessing the quality of Large Language Model (LLM) outputs presents a critical challenge. Previous methods either rely on text-level information (e.g., reward models, majority voting), which can overfit to superficial cues, or on calibrated confidence from token probabilities, which would fail on less-calibrated models. Yet both of these signals are, in fact, partial projections of a richer source of information: the model's internal hidden states. Early layers, closer to token embeddings, preserve semantic and lexical features that underpin text-based judgments, while later layers increasingly align with output logits, embedding confidence-related information. This paper explores hidden states directly as a unified foundation for verification. We show that the correctness of a solution is encoded as a geometrically separable signature within the trajectory of hidden activations. To validate this, we present Clue (Clustering and Experience-based Verification), a deliberately minimalist, non-parametric verifier. With no trainable parameters, CLUE only summarizes each reasoning trace by an hidden state delta and classifies correctness via nearest-centroid distance to ``success'' and ``failure'' clusters formed from past experience. The simplicity of this method highlights the strength of the underlying signal. Empirically, CLUE consistently outperforms LLM-as-a-judge baselines and matches or exceeds modern confidence-based methods in reranking candidates, improving both top-1 and majority-vote accuracy across AIME 24/25 and GPQA. As a highlight, on AIME 24 with a 1.5B model, CLUE boosts accuracy from 56.7% (majority@64) to 70.0% (top-maj@16).
VOGUE: Guiding Exploration with Visual Uncertainty Improves Multimodal Reasoning
Oct 01, 2025



Reinforcement learning with verifiable rewards (RLVR) improves reasoning in large language models (LLMs) but struggles with exploration, an issue that still persists for multimodal LLMs (MLLMs). Current methods treat the visual input as a fixed, deterministic condition, overlooking a critical source of ambiguity and struggling to build policies robust to plausible visual variations. We introduce $\textbf{VOGUE (Visual Uncertainty Guided Exploration)}$, a novel method that shifts exploration from the output (text) to the input (visual) space. By treating the image as a stochastic context, VOGUE quantifies the policy's sensitivity to visual perturbations using the symmetric KL divergence between a "raw" and "noisy" branch, creating a direct signal for uncertainty-aware exploration. This signal shapes the learning objective via an uncertainty-proportional bonus, which, combined with a token-entropy bonus and an annealed sampling schedule, effectively balances exploration and exploitation. Implemented within GRPO on two model scales (Qwen2.5-VL-3B/7B), VOGUE boosts pass@1 accuracy by an average of 2.6% on three visual math benchmarks and 3.7% on three general-domain reasoning benchmarks, while simultaneously increasing pass@4 performance and mitigating the exploration decay commonly observed in RL fine-tuning. Our work shows that grounding exploration in the inherent uncertainty of visual inputs is an effective strategy for improving multimodal reasoning.
Evolving Language Models without Labels: Majority Drives Selection, Novelty Promotes Variation
Sep 18, 2025Large language models (LLMs) are increasingly trained with reinforcement learning from verifiable rewards (RLVR), yet real-world deployment demands models that can self-improve without labels or external judges. Existing label-free methods, confidence minimization, self-consistency, or majority-vote objectives, stabilize learning but steadily shrink exploration, causing an entropy collapse: generations become shorter, less diverse, and brittle. Unlike prior approaches such as Test-Time Reinforcement Learning (TTRL), which primarily adapt models to the immediate unlabeled dataset at hand, our goal is broader: to enable general improvements without sacrificing the model's inherent exploration capacity and generalization ability, i.e., evolving. We formalize this issue and propose EVolution-Oriented and Label-free Reinforcement Learning (EVOL-RL), a simple rule that couples stability with variation under a label-free setting. EVOL-RL keeps the majority-voted answer as a stable anchor (selection) while adding a novelty-aware reward that favors responses whose reasoning differs from what has already been produced (variation), measured in semantic space. Implemented with GRPO, EVOL-RL also uses asymmetric clipping to preserve strong signals and an entropy regularizer to sustain search. This majority-for-selection + novelty-for-variation design prevents collapse, maintains longer and more informative chains of thought, and improves both pass@1 and pass@n. EVOL-RL consistently outperforms the majority-only TTRL baseline; e.g., training on label-free AIME24 lifts Qwen3-4B-Base AIME25 pass@1 from TTRL's 4.6% to 16.4%, and pass@16 from 18.5% to 37.9%. EVOL-RL not only prevents diversity collapse but also unlocks stronger generalization across domains (e.g., GPQA). Furthermore, we demonstrate that EVOL-RL also boosts performance in the RLVR setting, highlighting its broad applicability.