 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAstra: a generalizable report generation foundation model for 3D computed tomography
Jun 01, 2026CT interpretation requires radiologists to review hundreds of volumetric slices per examination, making reporting time-consuming and highly expertise-dependent. Automated CT report generation offers a promising route to improving clinical efficiency, yet the field still lacks a generalizable CT report generation foundation model that supports multi-region reporting and remains robust across external real-world cohorts. Intrinsic inconsistencies in reporting style and diagnostic terminology across cohorts make naive joint training prone to noisy textual supervision, thereby limiting model generalizability. Here we present Astra, a generalizable CT report generation foundation model trained on 90,678 thoracoabdominal CT-report pairs (CTRgDB) with 353,671 abnormalities spanning eight organ systems. By harmonizing report style and further refining diagnostic consistency via reinforcement learning, Astra achieves style-consistent and diagnostically accurate report generation across diverse anatomical regions and institutions. Evaluating on CTRgDB and six external cohorts, Astra achieves state-of-the-art performance with a 44.1% average improvement in fine-grained diagnostic metrics (P<0.001). In real-world clinical workflows, Astra assistance accelerates chest report drafting by 29.6% and improves abdominal report completeness by 11.3% (P<0.001). Furthermore, Astra also demonstrates broad utility as a foundation for CT AI development, improving downstream diagnostic performance and scaling vision-language pretrain through high-quality report synthesis. Overall, Astra serves as a broadly accessible clinical assistant and a pivotal infrastructure for the next generation of AI-powered healthcare.
UltraVSR: Achieving Ultra-Realistic Video Super-Resolution with Efficient One-Step Diffusion Space
May 26, 2025Diffusion models have shown great potential in generating realistic image detail. However, adapting these models to video super-resolution (VSR) remains challenging due to their inherent stochasticity and lack of temporal modeling. In this paper, we propose UltraVSR, a novel framework that enables ultra-realistic and temporal-coherent VSR through an efficient one-step diffusion space. A central component of UltraVSR is the Degradation-aware Restoration Schedule (DRS), which estimates a degradation factor from the low-resolution input and transforms iterative denoising process into a single-step reconstruction from from low-resolution to high-resolution videos. This design eliminates randomness from diffusion noise and significantly speeds up inference. To ensure temporal consistency, we propose a lightweight yet effective Recurrent Temporal Shift (RTS) module, composed of an RTS-convolution unit and an RTS-attention unit. By partially shifting feature components along the temporal dimension, these two units collaboratively facilitate effective feature propagation, fusion, and alignment across neighboring frames, without relying on explicit temporal layers. The RTS module is integrated into a pretrained text-to-image diffusion model and is further enhanced through Spatio-temporal Joint Distillation (SJD), which improves temporal coherence while preserving realistic details. Additionally, we introduce a Temporally Asynchronous Inference (TAI) strategy to capture long-range temporal dependencies under limited memory constraints. Extensive experiments show that UltraVSR achieves state-of-the-art performance, both qualitatively and quantitatively, in a single sampling step.
KunPeng: A Global Ocean Environmental Model
Apr 07, 2025Inspired by the similarity of the atmosphere-ocean physical coupling mechanism, this study innovatively migrates meteorological large-model techniques to the ocean domain, constructing the KunPeng global ocean environmental prediction model. Aimed at the discontinuous characteristics of marine space, we propose a terrain-adaptive mask constraint mechanism to mitigate effectively training divergence caused by abrupt gradients at land-sea boundaries. To fully integrate far-, medium-, and close-range marine features, a longitude-cyclic deformable convolution network (LC-DCN) is employed to enhance the dynamic receptive field, achieving refined modeling of multi-scale oceanic characteristics. A Deformable Convolution-enhanced Multi-Step Prediction module (DC-MTP) is employed to strengthen temporal dependency feature extraction capabilities. Experimental results demonstrate that this model achieves an average ACC of 0.80 in 15-day global predictions at 0.25$^\circ$ resolution, outperforming comparative models by 0.01-0.08. The average mean squared error (MSE) is 0.41 (representing a 5%-31% reduction) and the average mean absolute error (MAE) is 0.44 (0.6%-21% reduction) compared to other models. Significant improvements are particularly observed in sea surface parameter prediction, deep-sea region characterization, and current velocity field forecasting. Through a horizontal comparison of the applicability of operators at different scales in the marine domain, this study reveals that local operators significantly outperform global operators under slow-varying oceanic processes, demonstrating the effectiveness of dynamic feature pyramid representations in predicting marine physical parameters.
HA-FGOVD: Highlighting Fine-grained Attributes via Explicit Linear Composition for Open-Vocabulary Object Detection
Sep 24, 2024



Open-vocabulary object detection (OVD) models are considered to be Large Multi-modal Models (LMM), due to their extensive training data and a large number of parameters. Mainstream OVD models prioritize object coarse-grained category rather than focus on their fine-grained attributes, e.g., colors or materials, thus failed to identify objects specified with certain attributes. However, OVD models are pretrained on large-scale image-text pairs with rich attribute words, whose latent feature space can represent the global text feature as a linear composition of fine-grained attribute tokens without highlighting them. Therefore, we propose in this paper a universal and explicit approach for frozen mainstream OVD models that boosts their attribute-level detection capabilities by highlighting fine-grained attributes in explicit linear space. Firstly, a LLM is leveraged to highlight attribute words within the input text as a zero-shot prompted task. Secondly, by strategically adjusting the token masks, the text encoders of OVD models extract both global text and attribute-specific features, which are then explicitly composited as two vectors in linear space to form the new attribute-highlighted feature for detection tasks, where corresponding scalars are hand-crafted or learned to reweight both two vectors. Notably, these scalars can be seamlessly transferred among different OVD models, which proves that such an explicit linear composition is universal. Empirical evaluation on the FG-OVD dataset demonstrates that our proposed method uniformly improves fine-grained attribute-level OVD of various mainstream models and achieves new state-of-the-art performance.
Adaptive Transformer Modelling of Density Function for Nonparametric Survival Analysis
Sep 10, 2024Survival analysis holds a crucial role across diverse disciplines, such as economics, engineering and healthcare. It empowers researchers to analyze both time-invariant and time-varying data, encompassing phenomena like customer churn, material degradation and various medical outcomes. Given the complexity and heterogeneity of such data, recent endeavors have demonstrated successful integration of deep learning methodologies to address limitations in conventional statistical approaches. However, current methods typically involve cluttered probability distribution function (PDF), have lower sensitivity in censoring prediction, only model static datasets, or only rely on recurrent neural networks for dynamic modelling. In this paper, we propose a novel survival regression method capable of producing high-quality unimodal PDFs without any prior distribution assumption, by optimizing novel Margin-Mean-Variance loss and leveraging the flexibility of Transformer to handle both temporal and non-temporal data, coined UniSurv. Extensive experiments on several datasets demonstrate that UniSurv places a significantly higher emphasis on censoring compared to other methods.
YAYI 2: Multilingual Open-Source Large Language Models
Dec 22, 2023As the latest advancements in natural language processing, large language models (LLMs) have achieved human-level language understanding and generation abilities in many real-world tasks, and even have been regarded as a potential path to the artificial general intelligence. To better facilitate research on LLMs, many open-source LLMs, such as Llama 2 and Falcon, have recently been proposed and gained comparable performances to proprietary models. However, these models are primarily designed for English scenarios and exhibit poor performances in Chinese contexts. In this technical report, we propose YAYI 2, including both base and chat models, with 30 billion parameters. YAYI 2 is pre-trained from scratch on a multilingual corpus which contains 2.65 trillion tokens filtered by our pre-training data processing pipeline. The base model is aligned with human values through supervised fine-tuning with millions of instructions and reinforcement learning from human feedback. Extensive experiments on multiple benchmarks, such as MMLU and CMMLU, consistently demonstrate that the proposed YAYI 2 outperforms other similar sized open-source models.
Unsupervised Multi-view Pedestrian Detection
May 21, 2023



With the prosperity of the video surveillance, multiple visual sensors have been applied for an accurate localization of pedestrians in a specific area, which facilitate various applications like intelligent safety or new retailing. However, previous methods rely on the supervision from the human annotated pedestrian positions in every video frame and camera view, which is a heavy burden in addition to the necessary camera calibration and synchronization. Therefore, we propose in this paper an Unsupervised Multi-view Pedestrian Detection approach (UMPD) to eliminate the need of annotations to learn a multi-view pedestrian detector. 1) Firstly, Semantic-aware Iterative Segmentation (SIS) is proposed to extract discriminative visual representations of the input images from different camera views via an unsupervised pretrained model, then convert them into 2D segments of pedestrians, based on our proposed iterative Principal Component Analysis and the zero-shot semantic classes from the vision-language pretrained models. 2) Secondly, we propose Vertical-aware Differential Rendering (VDR) to not only learn the densities and colors of 3D voxels by the masks of SIS, images and camera poses, but also constraint the voxels to be vertical towards the ground plane, following the physical characteristics of pedestrians. 3) Thirdly, the densities of 3D voxels learned by VDR are projected onto Bird-Eyes-View as the final detection results. Extensive experiments on popular multi-view pedestrian detection benchmarks, i.e., Wildtrack and MultiviewX, show that our proposed UMPD approach, as the first unsupervised method to our best knowledge, performs competitively with the previous state-of-the-art supervised techniques. Code will be available.
VLPD: Context-Aware Pedestrian Detection via Vision-Language Semantic Self-Supervision
Apr 06, 2023



Detecting pedestrians accurately in urban scenes is significant for realistic applications like autonomous driving or video surveillance. However, confusing human-like objects often lead to wrong detections, and small scale or heavily occluded pedestrians are easily missed due to their unusual appearances. To address these challenges, only object regions are inadequate, thus how to fully utilize more explicit and semantic contexts becomes a key problem. Meanwhile, previous context-aware pedestrian detectors either only learn latent contexts with visual clues, or need laborious annotations to obtain explicit and semantic contexts. Therefore, we propose in this paper a novel approach via Vision-Language semantic self-supervision for context-aware Pedestrian Detection (VLPD) to model explicitly semantic contexts without any extra annotations. Firstly, we propose a self-supervised Vision-Language Semantic (VLS) segmentation method, which learns both fully-supervised pedestrian detection and contextual segmentation via self-generated explicit labels of semantic classes by vision-language models. Furthermore, a self-supervised Prototypical Semantic Contrastive (PSC) learning method is proposed to better discriminate pedestrians and other classes, based on more explicit and semantic contexts obtained from VLS. Extensive experiments on popular benchmarks show that our proposed VLPD achieves superior performances over the previous state-of-the-arts, particularly under challenging circumstances like small scale and heavy occlusion. Code is available at https://github.com/lmy98129/VLPD.
Boosting Video Super Resolution with Patch-Based Temporal Redundancy Optimization
Jul 18, 2022

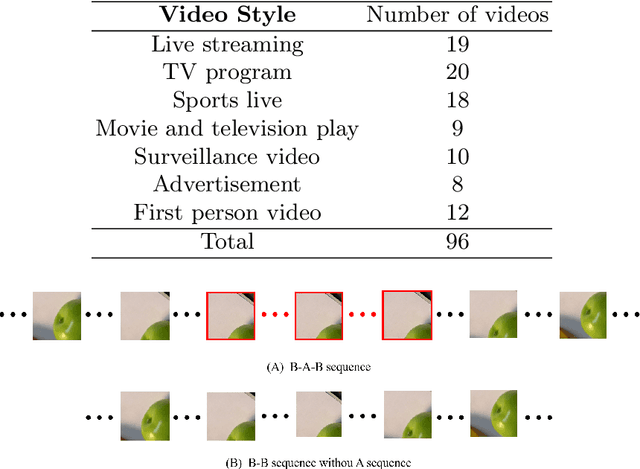

The success of existing video super-resolution (VSR) algorithms stems mainly exploiting the temporal information from the neighboring frames. However, none of these methods have discussed the influence of the temporal redundancy in the patches with stationary objects and background and usually use all the information in the adjacent frames without any discrimination. In this paper, we observe that the temporal redundancy will bring adverse effect to the information propagation,which limits the performance of the most existing VSR methods. Motivated by this observation, we aim to improve existing VSR algorithms by handling the temporal redundancy patches in an optimized manner. We develop two simple yet effective plug and play methods to improve the performance of existing local and non-local propagation-based VSR algorithms on widely-used public videos. For more comprehensive evaluating the robustness and performance of existing VSR algorithms, we also collect a new dataset which contains a variety of public videos as testing set. Extensive evaluations show that the proposed methods can significantly improve the performance of existing VSR methods on the collected videos from wild scenarios while maintain their performance on existing commonly used datasets. The code is available at https://github.com/HYHsimon/Boosted-VSR.
Boosting Multi-Modal E-commerce Attribute Value Extraction via Unified Learning Scheme and Dynamic Range Minimization
Jul 15, 2022
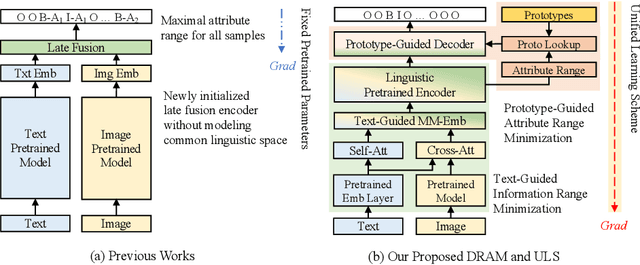
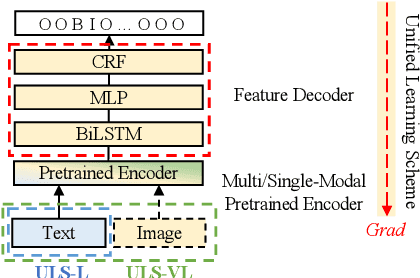

With the prosperity of e-commerce industry, various modalities, e.g., vision and language, are utilized to describe product items. It is an enormous challenge to understand such diversified data, especially via extracting the attribute-value pairs in text sequences with the aid of helpful image regions. Although a series of previous works have been dedicated to this task, there remain seldomly investigated obstacles that hinder further improvements: 1) Parameters from up-stream single-modal pretraining are inadequately applied, without proper jointly fine-tuning in a down-stream multi-modal task. 2) To select descriptive parts of images, a simple late fusion is widely applied, regardless of priori knowledge that language-related information should be encoded into a common linguistic embedding space by stronger encoders. 3) Due to diversity across products, their attribute sets tend to vary greatly, but current approaches predict with an unnecessary maximal range and lead to more potential false positives. To address these issues, we propose in this paper a novel approach to boost multi-modal e-commerce attribute value extraction via unified learning scheme and dynamic range minimization: 1) Firstly, a unified scheme is designed to jointly train a multi-modal task with pretrained single-modal parameters. 2) Secondly, a text-guided information range minimization method is proposed to adaptively encode descriptive parts of each modality into an identical space with a powerful pretrained linguistic model. 3) Moreover, a prototype-guided attribute range minimization method is proposed to first determine the proper attribute set of the current product, and then select prototypes to guide the prediction of the chosen attributes. Experiments on the popular multi-modal e-commerce benchmarks show that our approach achieves superior performance over the other state-of-the-art techniques.