 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Vision-Language Models as a Source of Rewards
Dec 14, 2023



Building generalist agents that can accomplish many goals in rich open-ended environments is one of the research frontiers for reinforcement learning. A key limiting factor for building generalist agents with RL has been the need for a large number of reward functions for achieving different goals. We investigate the feasibility of using off-the-shelf vision-language models, or VLMs, as sources of rewards for reinforcement learning agents. We show how rewards for visual achievement of a variety of language goals can be derived from the CLIP family of models, and used to train RL agents that can achieve a variety of language goals. We showcase this approach in two distinct visual domains and present a scaling trend showing how larger VLMs lead to more accurate rewards for visual goal achievement, which in turn produces more capable RL agents.
Zorro: the masked multimodal transformer
Jan 23, 2023



Attention-based models are appealing for multimodal processing because inputs from multiple modalities can be concatenated and fed to a single backbone network - thus requiring very little fusion engineering. The resulting representations are however fully entangled throughout the network, which may not always be desirable: in learning, contrastive audio-visual self-supervised learning requires independent audio and visual features to operate, otherwise learning collapses; in inference, evaluation of audio-visual models should be possible on benchmarks having just audio or just video. In this paper, we introduce Zorro, a technique that uses masks to control how inputs from each modality are routed inside Transformers, keeping some parts of the representation modality-pure. We apply this technique to three popular transformer-based architectures (ViT, Swin and HiP) and show that with contrastive pre-training Zorro achieves state-of-the-art results on most relevant benchmarks for multimodal tasks (AudioSet and VGGSound). Furthermore, the resulting models are able to perform unimodal inference on both video and audio benchmarks such as Kinetics-400 or ESC-50.
In-context Reinforcement Learning with Algorithm Distillation
Oct 25, 2022



We propose Algorithm Distillation (AD), a method for distilling reinforcement learning (RL) algorithms into neural networks by modeling their training histories with a causal sequence model. Algorithm Distillation treats learning to reinforcement learn as an across-episode sequential prediction problem. A dataset of learning histories is generated by a source RL algorithm, and then a causal transformer is trained by autoregressively predicting actions given their preceding learning histories as context. Unlike sequential policy prediction architectures that distill post-learning or expert sequences, AD is able to improve its policy entirely in-context without updating its network parameters. We demonstrate that AD can reinforcement learn in-context in a variety of environments with sparse rewards, combinatorial task structure, and pixel-based observations, and find that AD learns a more data-efficient RL algorithm than the one that generated the source data.
Towards Learning Universal Audio Representations
Dec 01, 2021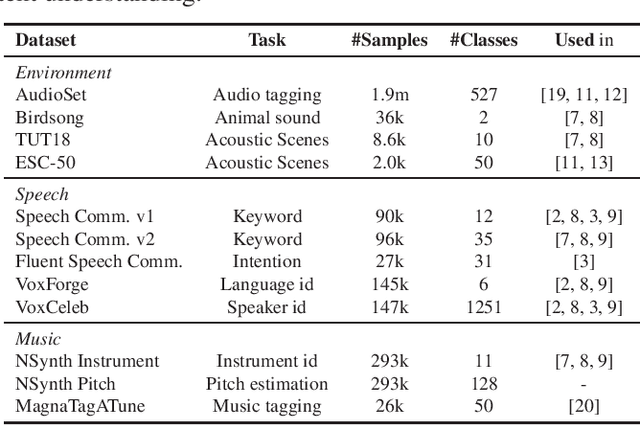
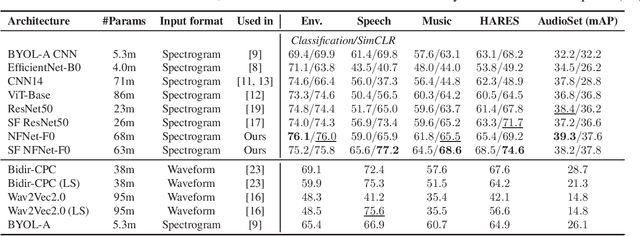
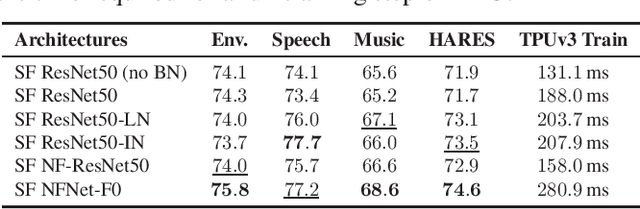
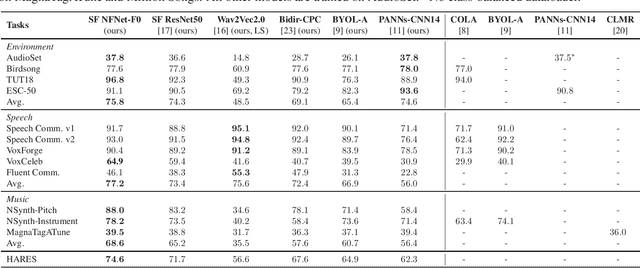
The ability to learn universal audio representations that can solve diverse speech, music, and environment tasks can spur many applications that require general sound content understanding. In this work, we introduce a holistic audio representation evaluation suite (HARES) spanning 12 downstream tasks across audio domains and provide a thorough empirical study of recent sound representation learning systems on that benchmark. We discover that previous sound event classification or speech models do not generalize outside of their domains. We observe that more robust audio representations can be learned with the SimCLR objective; however, the model's transferability depends heavily on the model architecture. We find the Slowfast architecture is good at learning rich representations required by different domains, but its performance is affected by the normalization scheme. Based on these findings, we propose a novel normalizer-free Slowfast NFNet and achieve state-of-the-art performance across all domains.
WikiGraphs: A Wikipedia Text - Knowledge Graph Paired Dataset
Jul 20, 2021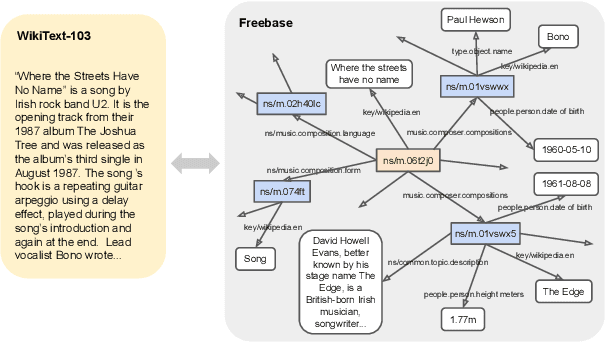
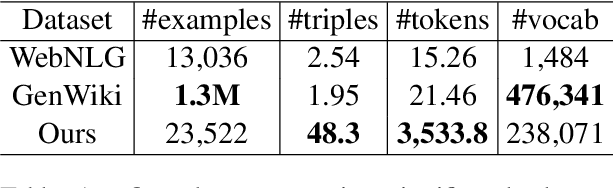
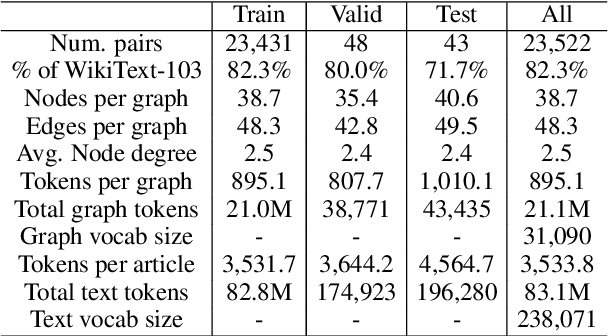
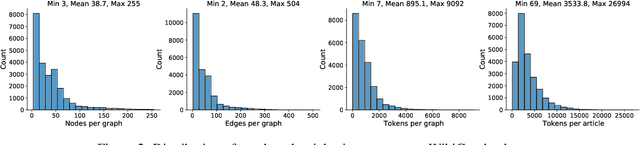
We present a new dataset of Wikipedia articles each paired with a knowledge graph, to facilitate the research in conditional text generation, graph generation and graph representation learning. Existing graph-text paired datasets typically contain small graphs and short text (1 or few sentences), thus limiting the capabilities of the models that can be learned on the data. Our new dataset WikiGraphs is collected by pairing each Wikipedia article from the established WikiText-103 benchmark (Merity et al., 2016) with a subgraph from the Freebase knowledge graph (Bollacker et al., 2008). This makes it easy to benchmark against other state-of-the-art text generative models that are capable of generating long paragraphs of coherent text. Both the graphs and the text data are of significantly larger scale compared to prior graph-text paired datasets. We present baseline graph neural network and transformer model results on our dataset for 3 tasks: graph -> text generation, graph -> text retrieval and text -> graph retrieval. We show that better conditioning on the graph provides gains in generation and retrieval quality but there is still large room for improvement.
Multimodal Self-Supervised Learning of General Audio Representations
Apr 28, 2021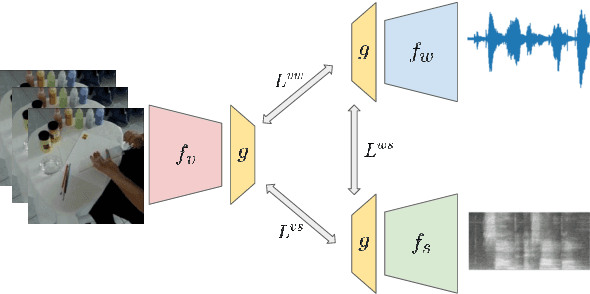

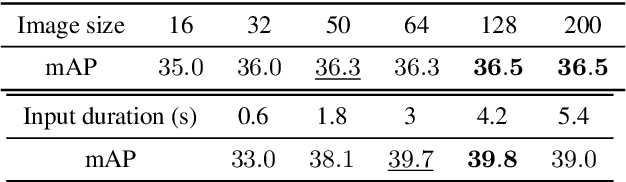

We present a multimodal framework to learn general audio representations from videos. Existing contrastive audio representation learning methods mainly focus on using the audio modality alone during training. In this work, we show that additional information contained in video can be utilized to greatly improve the learned features. First, we demonstrate that our contrastive framework does not require high resolution images to learn good audio features. This allows us to scale up the training batch size, while keeping the computational load incurred by the additional video modality to a reasonable level. Second, we use augmentations that mix together different samples. We show that this is effective to make the proxy task harder, which leads to substantial performance improvements when increasing the batch size. As a result, our audio model achieves a state-of-the-art of 42.4 mAP on the AudioSet classification downstream task, closing the gap between supervised and self-supervised methods trained on the same dataset. Moreover, we show that our method is advantageous on a broad range of non-semantic audio tasks, including speaker identification, keyword spotting, language identification, and music instrument classification.
Broaden Your Views for Self-Supervised Video Learning
Mar 30, 2021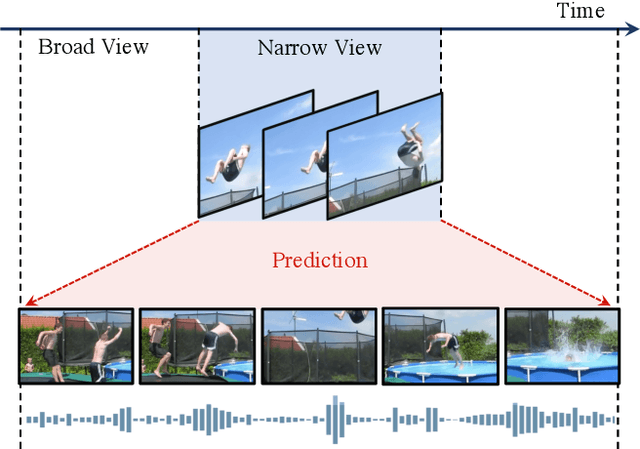
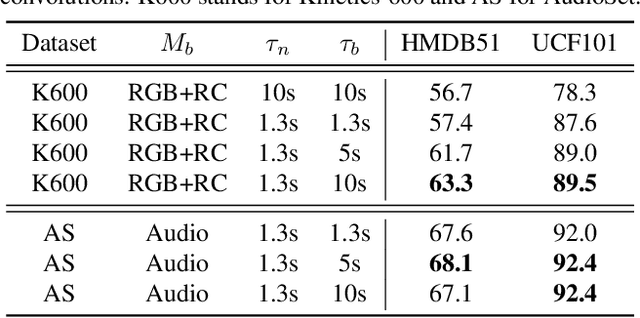
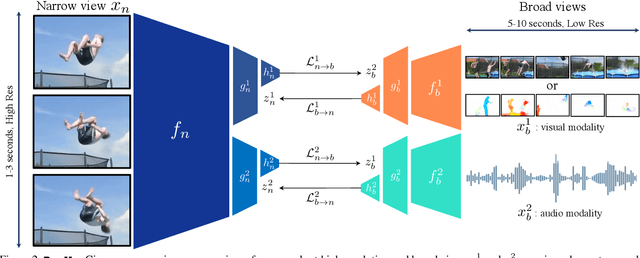
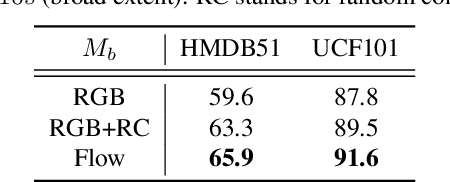
Most successful self-supervised learning methods are trained to align the representations of two independent views from the data. State-of-the-art methods in video are inspired by image techniques, where these two views are similarly extracted by cropping and augmenting the resulting crop. However, these methods miss a crucial element in the video domain: time. We introduce BraVe, a self-supervised learning framework for video. In BraVe, one of the views has access to a narrow temporal window of the video while the other view has a broad access to the video content. Our models learn to generalise from the narrow view to the general content of the video. Furthermore, BraVe processes the views with different backbones, enabling the use of alternative augmentations or modalities into the broad view such as optical flow, randomly convolved RGB frames, audio or their combinations. We demonstrate that BraVe achieves state-of-the-art results in self-supervised representation learning on standard video and audio classification benchmarks including UCF101, HMDB51, Kinetics, ESC-50 and AudioSet.
Multi-Format Contrastive Learning of Audio Representations
Mar 24, 2021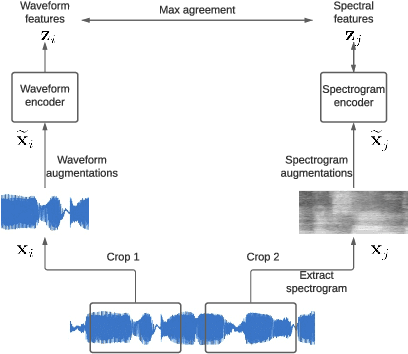
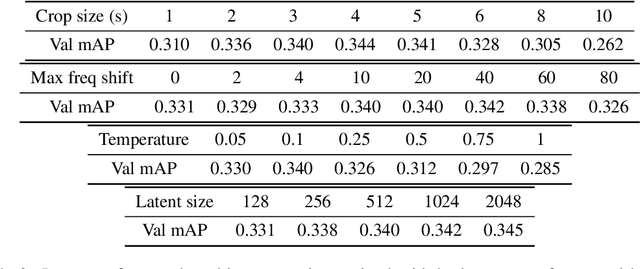
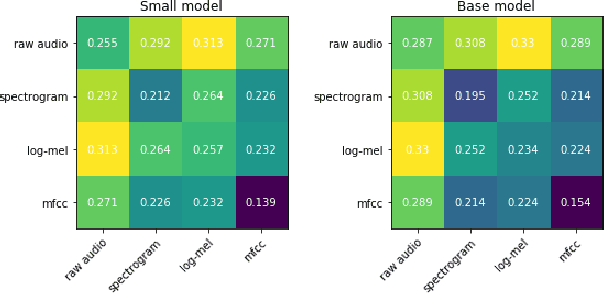
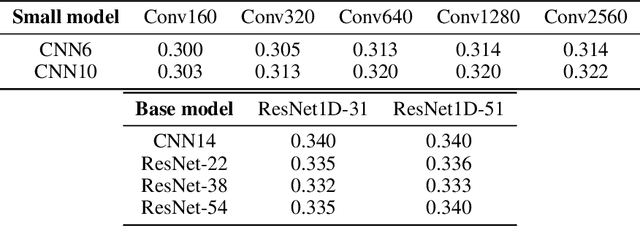
Recent advances suggest the advantage of multi-modal training in comparison with single-modal methods. In contrast to this view, in our work we find that similar gain can be obtained from training with different formats of a single modality. In particular, we investigate the use of the contrastive learning framework to learn audio representations by maximizing the agreement between the raw audio and its spectral representation. We find a significant gain using this multi-format strategy against the single-format counterparts. Moreover, on the downstream AudioSet and ESC-50 classification task, our audio-only approach achieves new state-of-the-art results with a mean average precision of 0.376 and an accuracy of 90.5%, respectively.