 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo LLMs Really Need 10+ Thoughts for "Find the Time 1000 Days Later"? Towards Structural Understanding of LLM Overthinking
Oct 09, 2025



Models employing long chain-of-thought (CoT) reasoning have shown superior performance on complex reasoning tasks. Yet, this capability introduces a critical and often overlooked inefficiency -- overthinking -- models often engage in unnecessarily extensive reasoning even for simple queries, incurring significant computations without accuracy improvements. While prior work has explored solutions to mitigate overthinking, a fundamental gap remains in our understanding of its underlying causes. Most existing analyses are limited to superficial, profiling-based observations, failing to delve into LLMs' inner workings. This study introduces a systematic, fine-grained analyzer of LLMs' thought process to bridge the gap, TRACE. We first benchmark the overthinking issue, confirming that long-thinking models are five to twenty times slower on simple tasks with no substantial gains. We then use TRACE to first decompose the thought process into minimally complete sub-thoughts. Next, by inferring discourse relationships among sub-thoughts, we construct granular thought progression graphs and subsequently identify common thinking patterns for topically similar queries. Our analysis reveals two major patterns for open-weight thinking models -- Explorer and Late Landing. This finding provides evidence that over-verification and over-exploration are the primary drivers of overthinking in LLMs. Grounded in thought structures, we propose a utility-based definition of overthinking, which moves beyond length-based metrics. This revised definition offers a more insightful understanding of LLMs' thought progression, as well as practical guidelines for principled overthinking management.
Vibe Checker: Aligning Code Evaluation with Human Preference
Oct 08, 2025



Large Language Models (LLMs) have catalyzed vibe coding, where users leverage LLMs to generate and iteratively refine code through natural language interactions until it passes their vibe check. Vibe check is tied to real-world human preference and goes beyond functionality: the solution should feel right, read cleanly, preserve intent, and remain correct. However, current code evaluation remains anchored to pass@k and captures only functional correctness, overlooking the non-functional instructions that users routinely apply. In this paper, we hypothesize that instruction following is the missing piece underlying vibe check that represents human preference in coding besides functional correctness. To quantify models' code instruction following capabilities with measurable signals, we present VeriCode, a taxonomy of 30 verifiable code instructions together with corresponding deterministic verifiers. We use the taxonomy to augment established evaluation suites, resulting in Vibe Checker, a testbed to assess both code instruction following and functional correctness. Upon evaluating 31 leading LLMs, we show that even the strongest models struggle to comply with multiple instructions and exhibit clear functional regression. Most importantly, a composite score of functional correctness and instruction following correlates the best with human preference, with the latter emerging as the primary differentiator on real-world programming tasks. Our work identifies core factors of the vibe check, providing a concrete path for benchmarking and developing models that better align with user preferences in coding.
Multi-Turn Puzzles: Evaluating Interactive Reasoning and Strategic Dialogue in LLMs
Aug 13, 2025Large language models (LLMs) excel at solving problems with clear and complete statements, but often struggle with nuanced environments or interactive tasks which are common in most real-world scenarios. This highlights the critical need for developing LLMs that can effectively engage in logically consistent multi-turn dialogue, seek information and reason with incomplete data. To this end, we introduce a novel benchmark comprising a suite of multi-turn tasks each designed to test specific reasoning, interactive dialogue, and information-seeking abilities. These tasks have deterministic scoring mechanisms, thus eliminating the need for human intervention. Evaluating frontier models on our benchmark reveals significant headroom. Our analysis shows that most errors emerge from poor instruction following, reasoning failures, and poor planning. This benchmark provides valuable insights into the strengths and weaknesses of current LLMs in handling complex, interactive scenarios and offers a robust platform for future research aimed at improving these critical capabilities.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
AutoMix: Automatically Mixing Language Models
Oct 19, 2023



Large language models (LLMs) are now available in various sizes and configurations from cloud API providers. While this diversity offers a broad spectrum of choices, effectively leveraging the options to optimize computational cost and performance remains challenging. In this work, we present AutoMix, an approach that strategically routes queries to larger LMs, based on the approximate correctness of outputs from a smaller LM. Central to AutoMix is a few-shot self-verification mechanism, which estimates the reliability of its own outputs without requiring training. Given that verifications can be noisy, we employ a meta verifier in AutoMix to refine the accuracy of these assessments. Our experiments using LLAMA2-13/70B, on five context-grounded reasoning datasets demonstrate that AutoMix surpasses established baselines, improving the incremental benefit per cost by up to 89%. Our code and data are available at https://github.com/automix-llm/automix.
How FaR Are Large Language Models From Agents with Theory-of-Mind?
Oct 04, 2023



"Thinking is for Doing." Humans can infer other people's mental states from observations--an ability called Theory-of-Mind (ToM)--and subsequently act pragmatically on those inferences. Existing question answering benchmarks such as ToMi ask models questions to make inferences about beliefs of characters in a story, but do not test whether models can then use these inferences to guide their actions. We propose a new evaluation paradigm for large language models (LLMs): Thinking for Doing (T4D), which requires models to connect inferences about others' mental states to actions in social scenarios. Experiments on T4D demonstrate that LLMs such as GPT-4 and PaLM 2 seemingly excel at tracking characters' beliefs in stories, but they struggle to translate this capability into strategic action. Our analysis reveals the core challenge for LLMs lies in identifying the implicit inferences about mental states without being explicitly asked about as in ToMi, that lead to choosing the correct action in T4D. To bridge this gap, we introduce a zero-shot prompting framework, Foresee and Reflect (FaR), which provides a reasoning structure that encourages LLMs to anticipate future challenges and reason about potential actions. FaR boosts GPT-4's performance from 50% to 71% on T4D, outperforming other prompting methods such as Chain-of-Thought and Self-Ask. Moreover, FaR generalizes to diverse out-of-distribution story structures and scenarios that also require ToM inferences to choose an action, consistently outperforming other methods including few-shot in-context learning.
Efficient Encoders for Streaming Sequence Tagging
Jan 23, 2023



A naive application of state-of-the-art bidirectional encoders for streaming sequence tagging would require encoding each token from scratch for each new token in an incremental streaming input (like transcribed speech). The lack of re-usability of previous computation leads to a higher number of Floating Point Operations (or FLOPs) and higher number of unnecessary label flips. Increased FLOPs consequently lead to higher wall-clock time and increased label flipping leads to poorer streaming performance. In this work, we present a Hybrid Encoder with Adaptive Restart (HEAR) that addresses these issues while maintaining the performance of bidirectional encoders over the offline (or complete) inputs while improving performance on streaming (or incomplete) inputs. HEAR has a Hybrid unidirectional-bidirectional encoder architecture to perform sequence tagging, along with an Adaptive Restart Module (ARM) to selectively guide the restart of bidirectional portion of the encoder. Across four sequence tagging tasks, HEAR offers FLOP savings in streaming settings upto 71.1% and also outperforms bidirectional encoders for streaming predictions by upto +10% streaming exact match.
CST5: Data Augmentation for Code-Switched Semantic Parsing
Nov 14, 2022



Extending semantic parsers to code-switched input has been a challenging problem, primarily due to a lack of supervised training data. In this work, we introduce CST5, a new data augmentation technique that finetunes a T5 model using a small seed set ($\approx$100 utterances) to generate code-switched utterances from English utterances. We show that CST5 generates high quality code-switched data, both intrinsically (per human evaluation) and extrinsically by comparing baseline models which are trained without data augmentation to models which are trained with augmented data. Empirically we observe that using CST5, one can achieve the same semantic parsing performance by using up to 20x less labeled data. To aid further research in this area, we are also releasing (a) Hinglish-TOP, the largest human annotated code-switched semantic parsing dataset to date, containing 10k human annotated Hindi-English (Hinglish) code-switched utterances, and (b) Over 170K CST5 generated code-switched utterances from the TOPv2 dataset. Human evaluation shows that both the human annotated data as well as the CST5 generated data is of good quality.
Streaming Intended Query Detection using E2E Modeling for Continued Conversation
Aug 29, 2022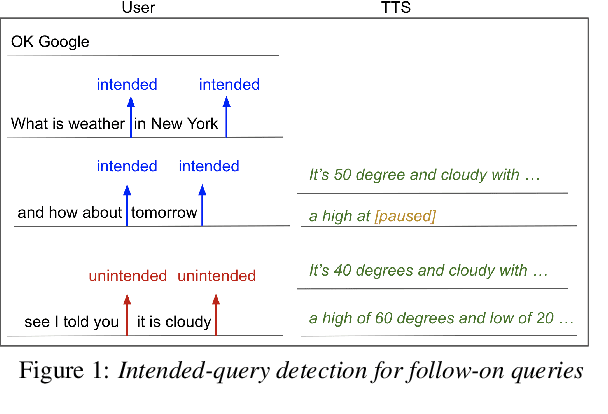

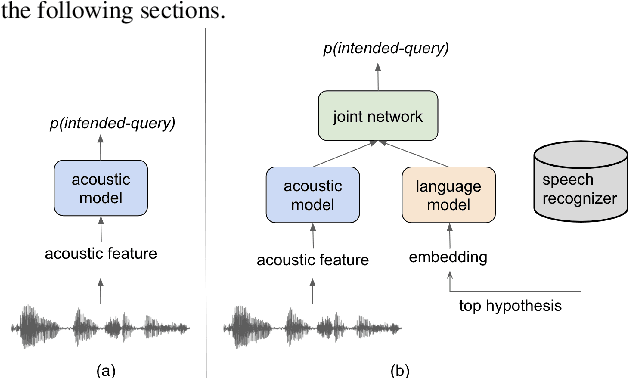
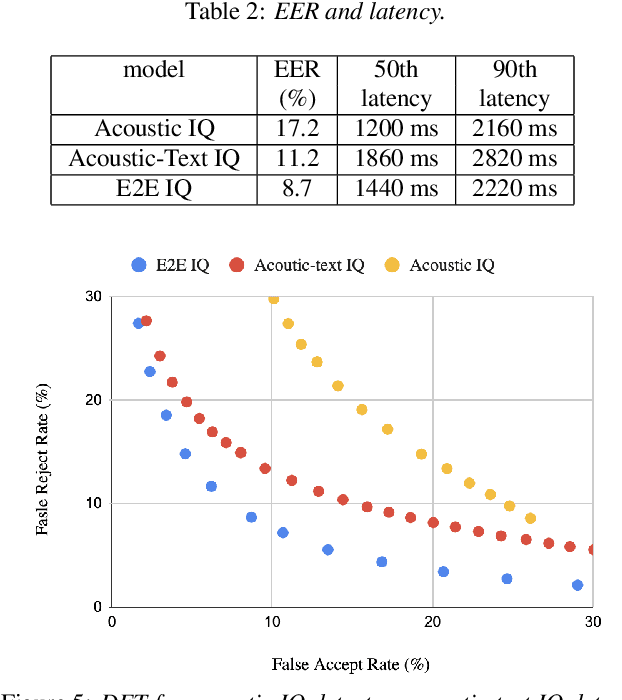
In voice-enabled applications, a predetermined hotword isusually used to activate a device in order to attend to the query.However, speaking queries followed by a hotword each timeintroduces a cognitive burden in continued conversations. Toavoid repeating a hotword, we propose a streaming end-to-end(E2E) intended query detector that identifies the utterancesdirected towards the device and filters out other utterancesnot directed towards device. The proposed approach incor-porates the intended query detector into the E2E model thatalready folds different components of the speech recognitionpipeline into one neural network.The E2E modeling onspeech decoding and intended query detection also allows us todeclare a quick intended query detection based on early partialrecognition result, which is important to decrease latencyand make the system responsive. We demonstrate that theproposed E2E approach yields a 22% relative improvement onequal error rate (EER) for the detection accuracy and 600 mslatency improvement compared with an independent intendedquery detector. In our experiment, the proposed model detectswhether the user is talking to the device with a 8.7% EERwithin 1.4 seconds of median latency after user starts speaking.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.