 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomata-based constraints for language model decoding
Jul 11, 2024



LMs are often expected to generate strings in some formal language; for example, structured data, API calls, or code snippets. Although LMs can be tuned to improve their adherence to formal syntax, this does not guarantee conformance, especially with smaller LMs suitable for large-scale deployment. In addition, tuning requires significant resources, making it impractical for uncommon or task-specific formats. To prevent downstream parsing errors we would ideally constrain the LM to only produce valid output, but this is severely complicated by tokenization, which is typically both ambiguous and misaligned with the formal grammar. We solve these issues through the application of automata theory, deriving an efficient closed-form solution for the regular languages, a broad class of formal languages with many practical applications, including API calls or schema-guided JSON and YAML. We also discuss pragmatic extensions for coping with the issue of high branching factor. Finally, we extend our techniques to deterministic context-free languages, which similarly admit an efficient closed-form solution. In spite of its flexibility and representative power, our approach only requires access to per-token decoding logits and lowers into simple calculations that are independent of LM size, making it both efficient and easy to apply to almost any LM architecture.
Capabilities of Gemini Models in Medicine
May 01, 2024



Excellence in a wide variety of medical applications poses considerable challenges for AI, requiring advanced reasoning, access to up-to-date medical knowledge and understanding of complex multimodal data. Gemini models, with strong general capabilities in multimodal and long-context reasoning, offer exciting possibilities in medicine. Building on these core strengths of Gemini, we introduce Med-Gemini, a family of highly capable multimodal models that are specialized in medicine with the ability to seamlessly use web search, and that can be efficiently tailored to novel modalities using custom encoders. We evaluate Med-Gemini on 14 medical benchmarks, establishing new state-of-the-art (SoTA) performance on 10 of them, and surpass the GPT-4 model family on every benchmark where a direct comparison is viable, often by a wide margin. On the popular MedQA (USMLE) benchmark, our best-performing Med-Gemini model achieves SoTA performance of 91.1% accuracy, using a novel uncertainty-guided search strategy. On 7 multimodal benchmarks including NEJM Image Challenges and MMMU (health & medicine), Med-Gemini improves over GPT-4V by an average relative margin of 44.5%. We demonstrate the effectiveness of Med-Gemini's long-context capabilities through SoTA performance on a needle-in-a-haystack retrieval task from long de-identified health records and medical video question answering, surpassing prior bespoke methods using only in-context learning. Finally, Med-Gemini's performance suggests real-world utility by surpassing human experts on tasks such as medical text summarization, alongside demonstrations of promising potential for multimodal medical dialogue, medical research and education. Taken together, our results offer compelling evidence for Med-Gemini's potential, although further rigorous evaluation will be crucial before real-world deployment in this safety-critical domain.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
TableFormer: Robust Transformer Modeling for Table-Text Encoding
Mar 01, 2022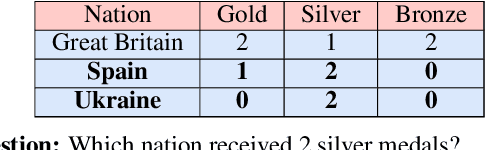
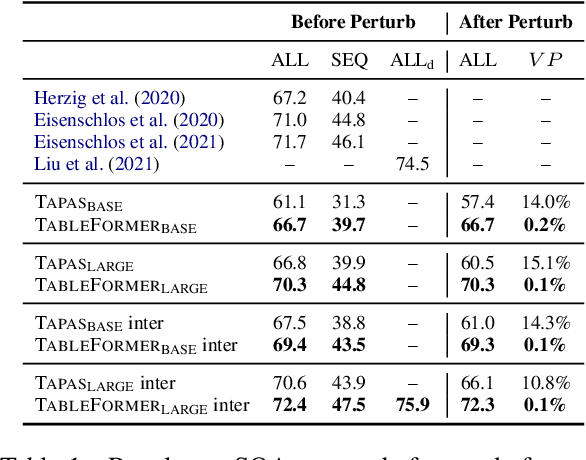
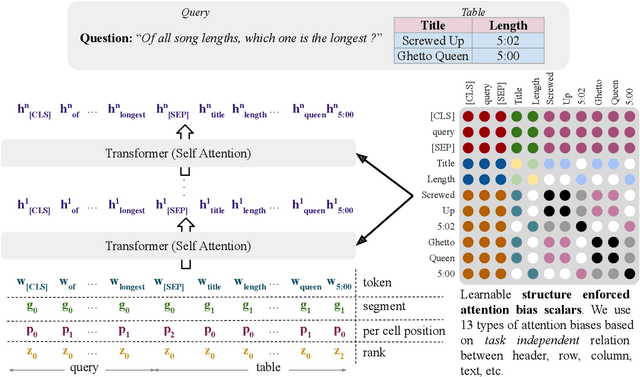
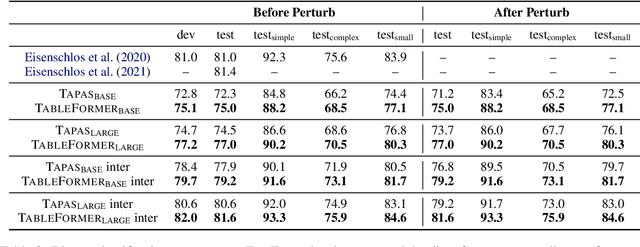
Understanding tables is an important aspect of natural language understanding. Existing models for table understanding require linearization of the table structure, where row or column order is encoded as an unwanted bias. Such spurious biases make the model vulnerable to row and column order perturbations. Additionally, prior work has not thoroughly modeled the table structures or table-text alignments, hindering the table-text understanding ability. In this work, we propose a robust and structurally aware table-text encoding architecture TableFormer, where tabular structural biases are incorporated completely through learnable attention biases. TableFormer is (1) strictly invariant to row and column orders, and, (2) could understand tables better due to its tabular inductive biases. Our evaluations showed that TableFormer outperforms strong baselines in all settings on SQA, WTQ and TabFact table reasoning datasets, and achieves state-of-the-art performance on SQA, especially when facing answer-invariant row and column order perturbations (6% improvement over the best baseline), because previous SOTA models' performance drops by 4% - 6% when facing such perturbations while TableFormer is not affected.
Graph-Based Decoding for Task Oriented Semantic Parsing
Sep 09, 2021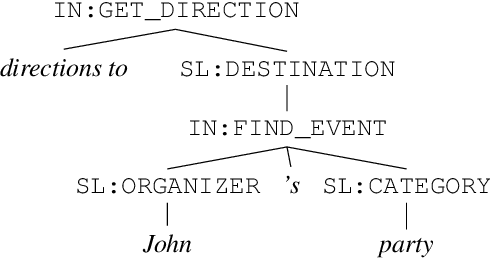
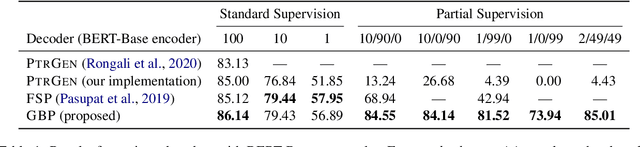

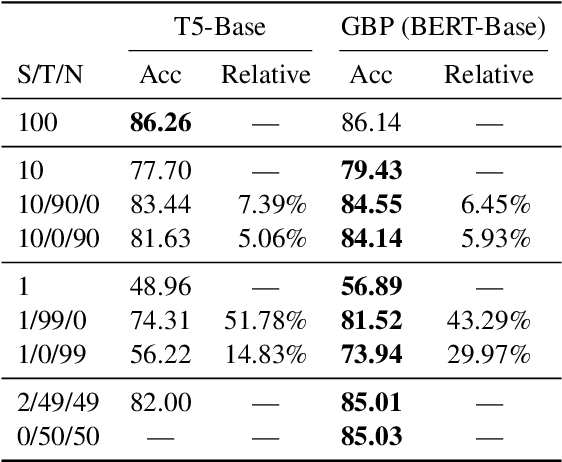
The dominant paradigm for semantic parsing in recent years is to formulate parsing as a sequence-to-sequence task, generating predictions with auto-regressive sequence decoders. In this work, we explore an alternative paradigm. We formulate semantic parsing as a dependency parsing task, applying graph-based decoding techniques developed for syntactic parsing. We compare various decoding techniques given the same pre-trained Transformer encoder on the TOP dataset, including settings where training data is limited or contains only partially-annotated examples. We find that our graph-based approach is competitive with sequence decoders on the standard setting, and offers significant improvements in data efficiency and settings where partially-annotated data is available.
TIMEDIAL: Temporal Commonsense Reasoning in Dialog
Jun 08, 2021
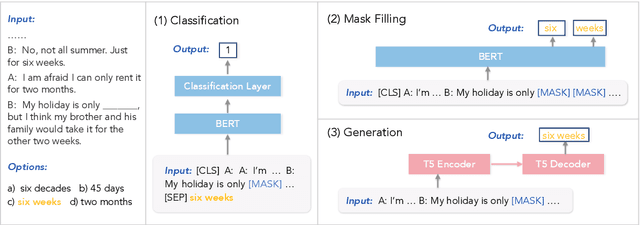

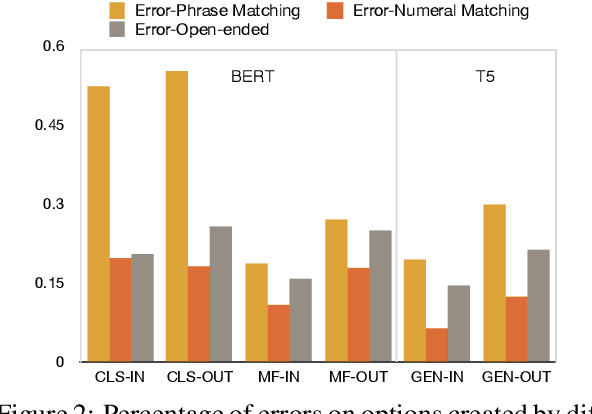
Everyday conversations require understanding everyday events, which in turn, requires understanding temporal commonsense concepts interwoven with those events. Despite recent progress with massive pre-trained language models (LMs) such as T5 and GPT-3, their capability of temporal reasoning in dialogs remains largely under-explored. In this paper, we present the first study to investigate pre-trained LMs for their temporal reasoning capabilities in dialogs by introducing a new task and a crowd-sourced English challenge set, TIMEDIAL. We formulate TIME-DIAL as a multiple-choice cloze task with over 1.1K carefully curated dialogs. Empirical results demonstrate that even the best performing models struggle on this task compared to humans, with 23 absolute points of gap in accuracy. Furthermore, our analysis reveals that the models fail to reason about dialog context correctly; instead, they rely on shallow cues based on existing temporal patterns in context, motivating future research for modeling temporal concepts in text and robust contextual reasoning about them. The dataset is publicly available at: https://github.com/google-research-datasets/timedial.
Few-shot Intent Classification and Slot Filling with Retrieved Examples
Apr 12, 2021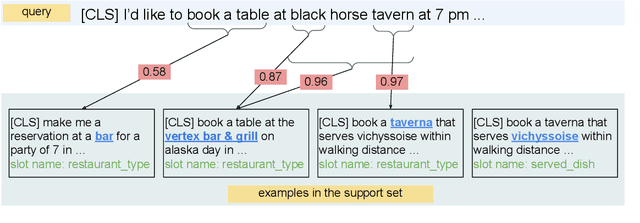
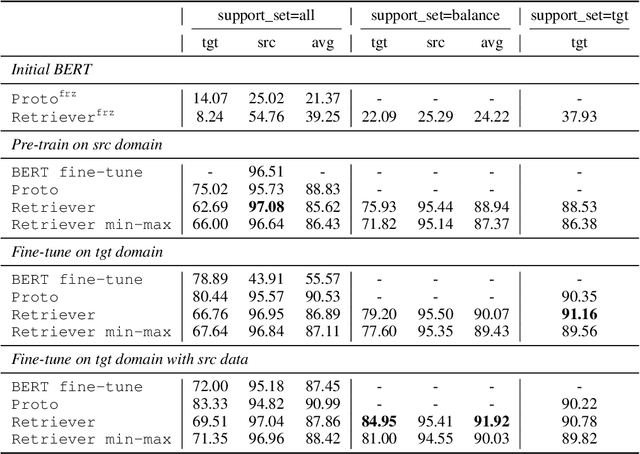
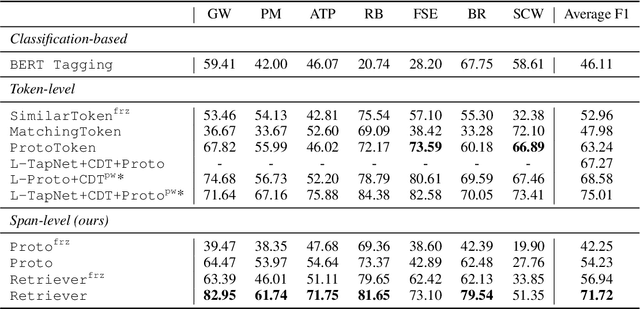

Few-shot learning arises in important practical scenarios, such as when a natural language understanding system needs to learn new semantic labels for an emerging, resource-scarce domain. In this paper, we explore retrieval-based methods for intent classification and slot filling tasks in few-shot settings. Retrieval-based methods make predictions based on labeled examples in the retrieval index that are similar to the input, and thus can adapt to new domains simply by changing the index without having to retrain the model. However, it is non-trivial to apply such methods on tasks with a complex label space like slot filling. To this end, we propose a span-level retrieval method that learns similar contextualized representations for spans with the same label via a novel batch-softmax objective. At inference time, we use the labels of the retrieved spans to construct the final structure with the highest aggregated score. Our method outperforms previous systems in various few-shot settings on the CLINC and SNIPS benchmarks.
Neural Data Augmentation via Example Extrapolation
Feb 02, 2021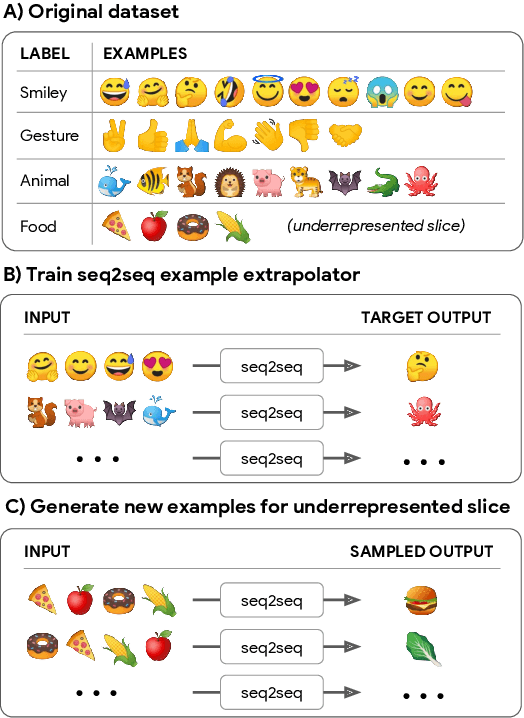

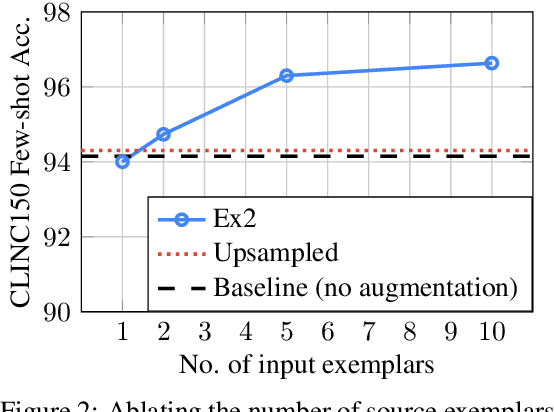
In many applications of machine learning, certain categories of examples may be underrepresented in the training data, causing systems to underperform on such "few-shot" cases at test time. A common remedy is to perform data augmentation, such as by duplicating underrepresented examples, or heuristically synthesizing new examples. But these remedies often fail to cover the full diversity and complexity of real examples. We propose a data augmentation approach that performs neural Example Extrapolation (Ex2). Given a handful of exemplars sampled from some distribution, Ex2 synthesizes new examples that also belong to the same distribution. The Ex2 model is learned by simulating the example generation procedure on data-rich slices of the data, and it is applied to underrepresented, few-shot slices. We apply Ex2 to a range of language understanding tasks and significantly improve over state-of-the-art methods on multiple few-shot learning benchmarks, including for relation extraction (FewRel) and intent classification + slot filling (SNIPS).