 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeeXmY: A Data Type and Technique for Arbitrary Bit Precision Quantization
May 22, 2024



eXmY is a novel data type for quantization of ML models. It supports both arbitrary bit widths and arbitrary integer and floating point formats. For example, it seamlessly supports 3, 5, 6, 7, 9 bit formats. For a specific bit width, say 7, it defines all possible formats e.g. e0m6, e1m5, e2m4, e3m3, e4m2, e5m1 and e6m0. For non-power of two bit widths e.g. 5, 6, 7, we created a novel encoding and decoding scheme which achieves perfect compression, byte addressability and is amenable to sharding and vector processing. We implemented libraries for emulation, encoding and decoding tensors and checkpoints in C++, TensorFlow, JAX and PAX. For optimal performance, the codecs use SIMD instructions on CPUs and vector instructions on TPUs and GPUs. eXmY is also a technique and exploits the statistical distribution of exponents in tensors. It can be used to quantize weights, static and dynamic activations, gradients, master weights and optimizer state. It can reduce memory (CPU DRAM and accelerator HBM), network and disk storage and transfers. It can increase multi tenancy and accelerate compute. eXmY has been deployed in production for almost 2 years.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
TPU-KNN: K Nearest Neighbor Search at Peak FLOP/s
Jun 30, 2022
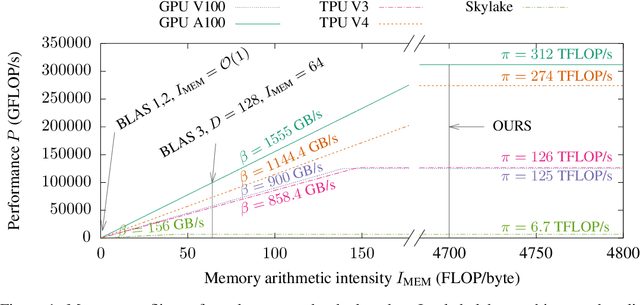
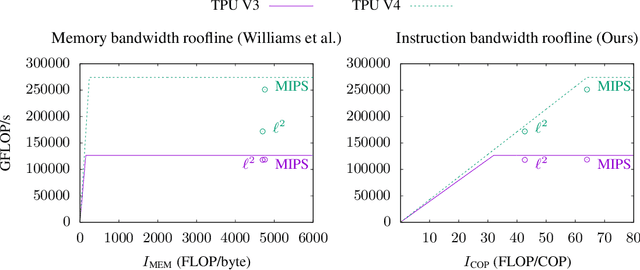
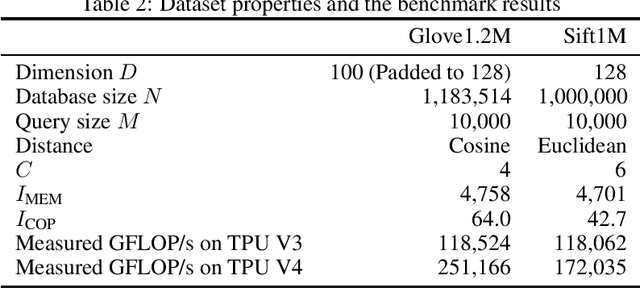
This paper presents a novel nearest neighbor search algorithm achieving TPU (Google Tensor Processing Unit) peak performance, outperforming state-of-the-art GPU algorithms with similar level of recall. The design of the proposed algorithm is motivated by an accurate accelerator performance model that takes into account both the memory and instruction bottlenecks. Our algorithm comes with an analytical guarantee of recall in expectation and does not require maintaining sophisticated index data structure or tuning, making it suitable for applications with frequent updates. Our work is available in the open-source package of Jax and Tensorflow on TPU.
Unified Scaling Laws for Routed Language Models
Feb 09, 2022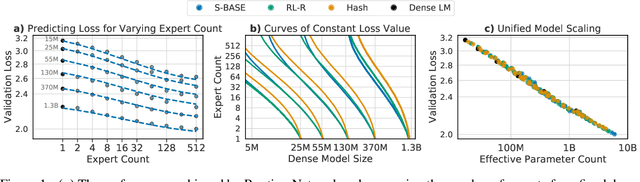

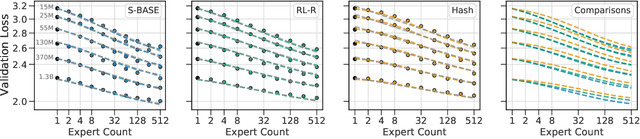
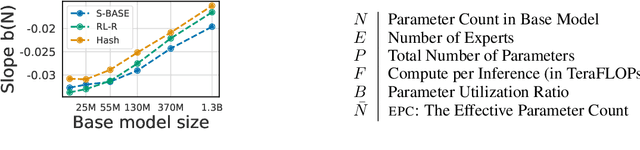
The performance of a language model has been shown to be effectively modeled as a power-law in its parameter count. Here we study the scaling behaviors of Routing Networks: architectures that conditionally use only a subset of their parameters while processing an input. For these models, parameter count and computational requirement form two independent axes along which an increase leads to better performance. In this work we derive and justify scaling laws defined on these two variables which generalize those known for standard language models and describe the performance of a wide range of routing architectures trained via three different techniques. Afterwards we provide two applications of these laws: first deriving an Effective Parameter Count along which all models scale at the same rate, and then using the scaling coefficients to give a quantitative comparison of the three routing techniques considered. Our analysis derives from an extensive evaluation of Routing Networks across five orders of magnitude of size, including models with hundreds of experts and hundreds of billions of parameters.
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Dec 08, 2021



Language modelling provides a step towards intelligent communication systems by harnessing large repositories of written human knowledge to better predict and understand the world. In this paper, we present an analysis of Transformer-based language model performance across a wide range of model scales -- from models with tens of millions of parameters up to a 280 billion parameter model called Gopher. These models are evaluated on 152 diverse tasks, achieving state-of-the-art performance across the majority. Gains from scale are largest in areas such as reading comprehension, fact-checking, and the identification of toxic language, but logical and mathematical reasoning see less benefit. We provide a holistic analysis of the training dataset and model's behaviour, covering the intersection of model scale with bias and toxicity. Finally we discuss the application of language models to AI safety and the mitigation of downstream harms.
GSPMD: General and Scalable Parallelization for ML Computation Graphs
May 10, 2021

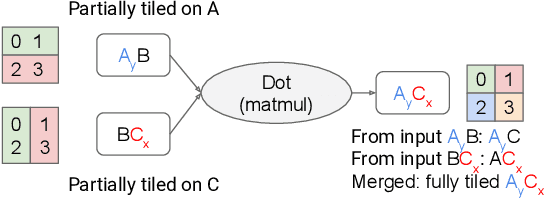
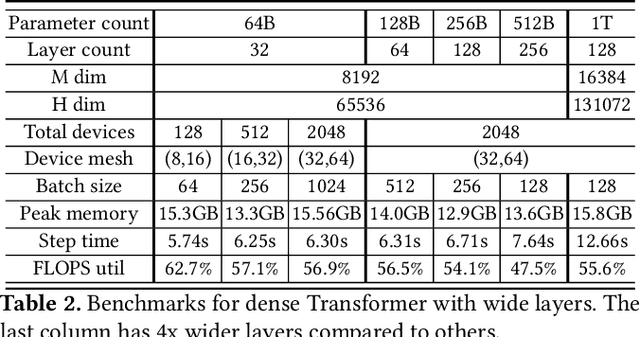
We present GSPMD, an automatic, compiler-based parallelization system for common machine learning computation graphs. It allows users to write programs in the same way as for a single device, then give hints through a few annotations on how to distribute tensors, based on which GSPMD will parallelize the computation. Its representation of partitioning is simple yet general, allowing it to express different or mixed paradigms of parallelism on a wide variety of models. GSPMD infers the partitioning for every operator in the graph based on limited user annotations, making it convenient to scale up existing single-device programs. It solves several technical challenges for production usage, such as static shape constraints, uneven partitioning, exchange of halo data, and nested operator partitioning. These techniques allow GSPMD to achieve 50% to 62% compute utilization on 128 to 2048 Cloud TPUv3 cores for models with up to one trillion parameters. GSPMD produces a single program for all devices, which adjusts its behavior based on a run-time partition ID, and uses collective operators for cross-device communication. This property allows the system itself to be scalable: the compilation time stays constant with increasing number of devices.
Scaling Local Self-Attention for Parameter Efficient Visual Backbones
Mar 30, 2021
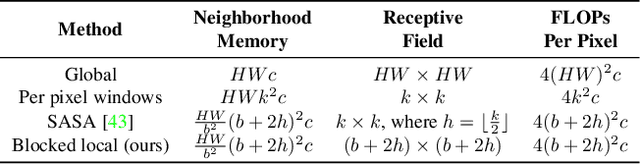
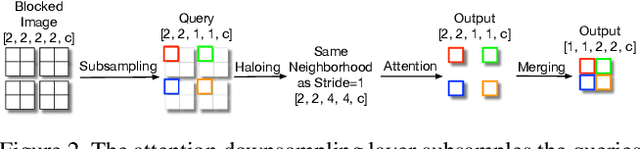

Self-attention has the promise of improving computer vision systems due to parameter-independent scaling of receptive fields and content-dependent interactions, in contrast to parameter-dependent scaling and content-independent interactions of convolutions. Self-attention models have recently been shown to have encouraging improvements on accuracy-parameter trade-offs compared to baseline convolutional models such as ResNet-50. In this work, we aim to develop self-attention models that can outperform not just the canonical baseline models, but even the high-performing convolutional models. We propose two extensions to self-attention that, in conjunction with a more efficient implementation of self-attention, improve the speed, memory usage, and accuracy of these models. We leverage these improvements to develop a new self-attention model family, HaloNets, which reach state-of-the-art accuracies on the parameter-limited setting of the ImageNet classification benchmark. In preliminary transfer learning experiments, we find that HaloNet models outperform much larger models and have better inference performance. On harder tasks such as object detection and instance segmentation, our simple local self-attention and convolutional hybrids show improvements over very strong baselines. These results mark another step in demonstrating the efficacy of self-attention models on settings traditionally dominated by convolutional models.
Exploring the limits of Concurrency in ML Training on Google TPUs
Nov 07, 2020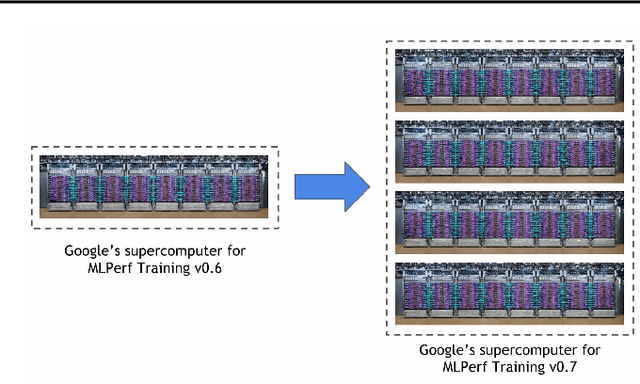
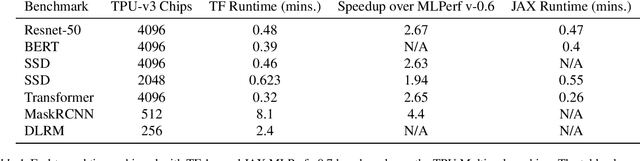
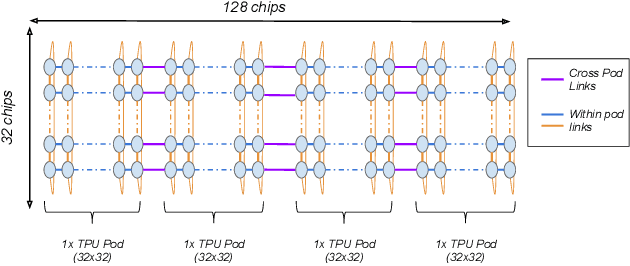
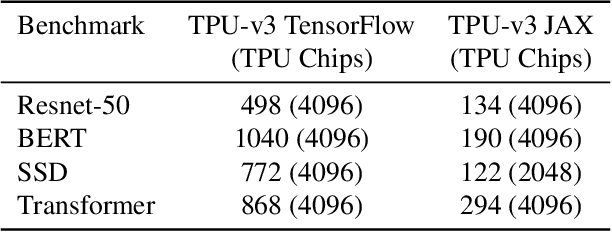
Recent results in language understanding using neural networks have required training hardware of unprecedentedscale, with thousands of chips cooperating on a single training run. This paper presents techniques to scaleML models on the Google TPU Multipod, a mesh with 4096 TPU-v3 chips. We discuss model parallelism toovercome scaling limitations from the fixed batch size in data parallelism, communication/collective optimizations,distributed evaluation of training metrics, and host input processing scaling optimizations. These techniques aredemonstrated in both the TensorFlow and JAX programming frameworks. We also present performance resultsfrom the recent Google submission to the MLPerf-v0.7 benchmark contest, achieving record training times from16 to 28 seconds in four MLPerf models on the Google TPU-v3 Multipod machine.
Automatic Cross-Replica Sharding of Weight Update in Data-Parallel Training
Apr 28, 2020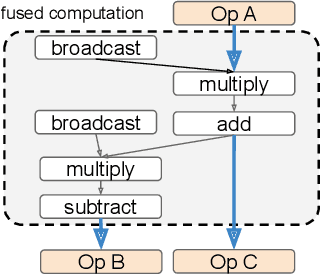
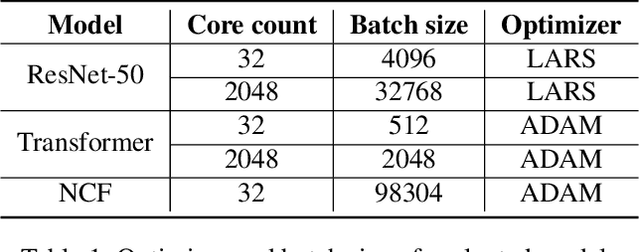
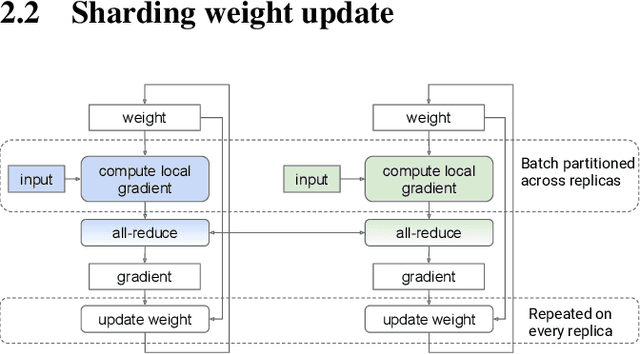
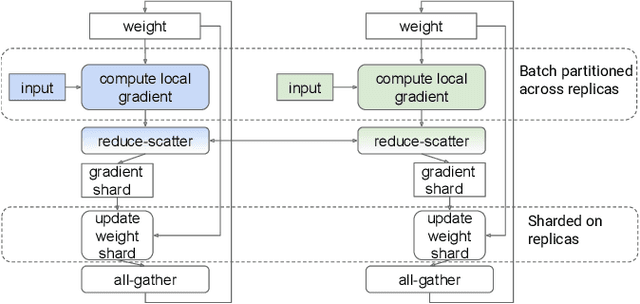
In data-parallel synchronous training of deep neural networks, different devices (replicas) run the same program with different partitions of the training batch, but weight update computation is repeated on all replicas, because the weights do not have a batch dimension to partition. This can be a bottleneck for performance and scalability in typical language models with large weights, and models with small per-replica batch size which is typical in large-scale training. This paper presents an approach to automatically shard the weight update computation across replicas with efficient communication primitives and data formatting, using static analysis and transformations on the training computation graph. We show this technique achieves substantial speedups on typical image and language models on Cloud TPUs, requiring no change to model code. This technique helps close the gap between traditionally expensive (ADAM) and cheap (SGD) optimizers, as they will only take a small part of training step time and have similar peak memory usage. It helped us to achieve state-of-the-art training performance in Google's MLPerf 0.6 submission.
Scale MLPerf-0.6 models on Google TPU-v3 Pods
Oct 02, 2019
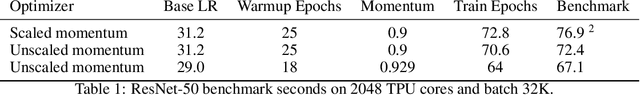

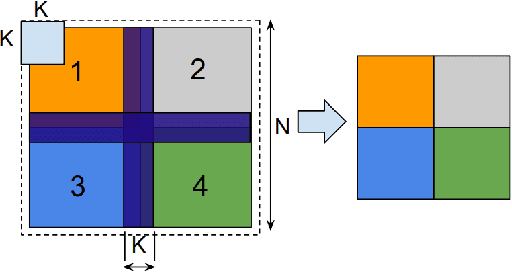
The recent submission of Google TPU-v3 Pods to the industry wide MLPerf v0.6 training benchmark demonstrates the scalability of a suite of industry relevant ML models. MLPerf defines a suite of models, datasets and rules to follow when benchmarking to ensure results are comparable across hardware, frameworks and companies. Using this suite of models, we discuss the optimizations and techniques including choice of optimizer, spatial partitioning and weight update sharding necessary to scale to 1024 TPU chips. Furthermore, we identify properties of models that make scaling them challenging, such as limited data parallelism and unscaled weights. These optimizations contribute to record performance in transformer, Resnet-50 and SSD in the Google MLPerf-0.6 submission.