 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Conversations Beneath the Code: Triadic Data for Long-Horizon Software Engineering Agents
May 04, 2026Frontier software engineering agents have saturated short-horizon benchmarks while regressing on the work that constitutes senior engineering: long-horizon, multi-engineer, ambiguous-specification deliverables. This paper takes a position on what training data is needed to close the gap. The substrate for the next generation of SWE agents is neither larger GitHub scrapes nor more solo-agent trajectories nor -- sufficient by itself -- open human-AI dialogue logs. It is triadic data: synchronized capture of the human-human conversations where engineering context is formed, the human-AI sessions where that context is partially consumed, and the multi-week cross-functional work that surrounds both. We argue that the canonical instantiation of triadic data is two complementary products: long-horizon expert trajectories captured under stimulated-recall protocols, and simulated cross-functional companies -- instrumented teams of senior engineers, product managers, designers, and data scientists working through ambiguous deliverables on shared infrastructure. We further specify a four-tier evidence framework through which any such corpus -- triadic or otherwise -- must justify its quality to a fine-tuning researcher: mechanical verification, statistical corpus characterization, probe experiments, and pre-registered blind evaluation. We argue that this data is capturable in 12-18 months with methods already mature in adjacent fields, that it is the empirical key to four open questions in agent training, and that the field's near-term research agenda should include it explicitly.
AsymLoc: Towards Asymmetric Feature Matching for Efficient Visual Localization
Apr 10, 2026Precise and real-time visual localization is critical for applications like AR/VR and robotics, especially on resource-constrained edge devices such as smart glasses, where battery life and heat dissipation can be a primary concerns. While many efficient models exist, further reducing compute without sacrificing accuracy is essential for practical deployment. To address this, we propose asymmetric visual localization: a large Teacher model processes pre-mapped database images offline, while a lightweight Student model processes the query image online. This creates a challenge in matching features from two different models without resorting to heavy, learned matchers. We introduce AsymLoc, a novel distillation framework that aligns a Student to its Teacher through a combination of a geometry-driven matching objective and a joint detector-descriptor distillation objective, enabling fast, parameter-less nearest-neighbor matching. Extensive experiments on HPatches, ScanNet, IMC2022, and Aachen show that AsymLoc achieves up to 95% of the teacher's localization accuracy using an order of magnitude smaller models, significantly outperforming existing baselines and establishing a new state-of-the-art efficiency-accuracy trade-off.
studentSplat: Your Student Model Learns Single-view 3D Gaussian Splatting
Jan 16, 2026Recent advance in feed-forward 3D Gaussian splatting has enable remarkable multi-view 3D scene reconstruction or single-view 3D object reconstruction but single-view 3D scene reconstruction remain under-explored due to inherited ambiguity in single-view. We present \textbf{studentSplat}, a single-view 3D Gaussian splatting method for scene reconstruction. To overcome the scale ambiguity and extrapolation problems inherent in novel-view supervision from a single input, we introduce two techniques: 1) a teacher-student architecture where a multi-view teacher model provides geometric supervision to the single-view student during training, addressing scale ambiguity and encourage geometric validity; and 2) an extrapolation network that completes missing scene context, enabling high-quality extrapolation. Extensive experiments show studentSplat achieves state-of-the-art single-view novel-view reconstruction quality and comparable performance to multi-view methods at the scene level. Furthermore, studentSplat demonstrates competitive performance as a self-supervised single-view depth estimation method, highlighting its potential for general single-view 3D understanding tasks.
Robust Egocentric Visual Attention Prediction Through Language-guided Scene Context-aware Learning
Jan 05, 2026As the demand for analyzing egocentric videos grows, egocentric visual attention prediction, anticipating where a camera wearer will attend, has garnered increasing attention. However, it remains challenging due to the inherent complexity and ambiguity of dynamic egocentric scenes. Motivated by evidence that scene contextual information plays a crucial role in modulating human attention, in this paper, we present a language-guided scene context-aware learning framework for robust egocentric visual attention prediction. We first design a context perceiver which is guided to summarize the egocentric video based on a language-based scene description, generating context-aware video representations. We then introduce two training objectives that: 1) encourage the framework to focus on the target point-of-interest regions and 2) suppress distractions from irrelevant regions which are less likely to attract first-person attention. Extensive experiments on Ego4D and Aria Everyday Activities (AEA) datasets demonstrate the effectiveness of our approach, achieving state-of-the-art performance and enhanced robustness across diverse, dynamic egocentric scenarios.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Acted vs. Improvised: Domain Adaptation for Elicitation Approaches in Audio-Visual Emotion Recognition
Apr 05, 2021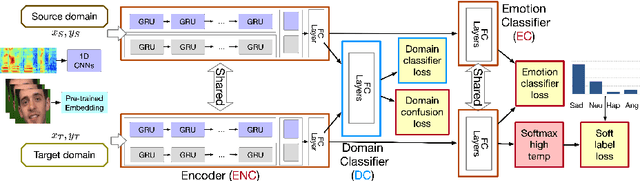
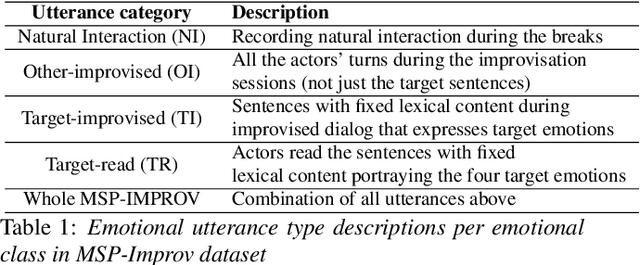
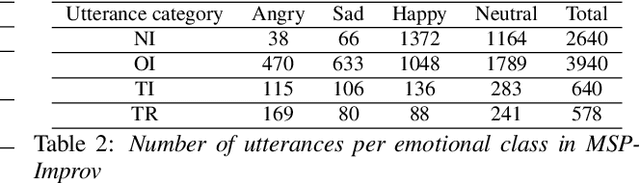
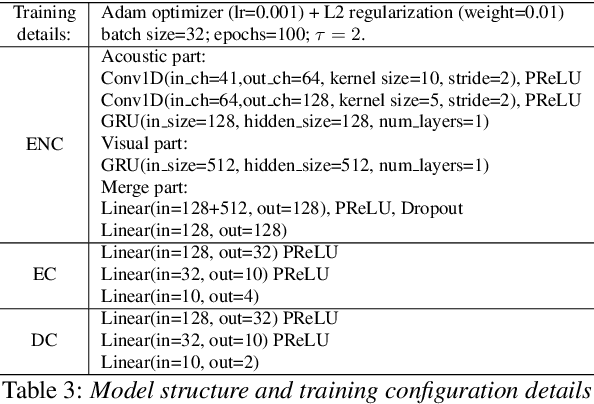
Key challenges in developing generalized automatic emotion recognition systems include scarcity of labeled data and lack of gold-standard references. Even for the cues that are labeled as the same emotion category, the variability of associated expressions can be high depending on the elicitation context e.g., emotion elicited during improvised conversations vs. acted sessions with predefined scripts. In this work, we regard the emotion elicitation approach as domain knowledge, and explore domain transfer learning techniques on emotional utterances collected under different emotion elicitation approaches, particularly with limited labeled target samples. Our emotion recognition model combines the gradient reversal technique with an entropy loss function as well as the softlabel loss, and the experiment results show that domain transfer learning methods can be employed to alleviate the domain mismatch between different elicitation approaches. Our work provides new insights into emotion data collection, particularly the impact of its elicitation strategies, and the importance of domain adaptation in emotion recognition aiming for generalized systems.