 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Simplex: 2-Simplicial Attention in Triton
Jul 03, 2025Recent work has shown that training loss scales as a power law with both model size and the number of tokens, and that achieving compute-optimal models requires scaling model size and token count together. However, these scaling laws assume an infinite supply of data and apply primarily in compute-bound settings. As modern large language models increasingly rely on massive internet-scale datasets, the assumption that they are compute-bound is becoming less valid. This shift highlights the need for architectures that prioritize token efficiency. In this work, we investigate the use of the 2-simplicial Transformer, an architecture that generalizes standard dot-product attention to trilinear functions through an efficient Triton kernel implementation. We demonstrate that the 2-simplicial Transformer achieves better token efficiency than standard Transformers: for a fixed token budget, similarly sized models outperform their dot-product counterparts on tasks involving mathematics, coding, reasoning, and logic. We quantify these gains by demonstrating that $2$-simplicial attention changes the exponent in the scaling laws for knowledge and reasoning tasks compared to dot product attention.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
PaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.
N-Grammer: Augmenting Transformers with latent n-grams
Jul 13, 2022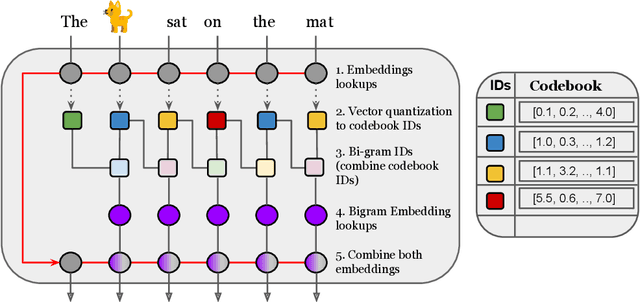
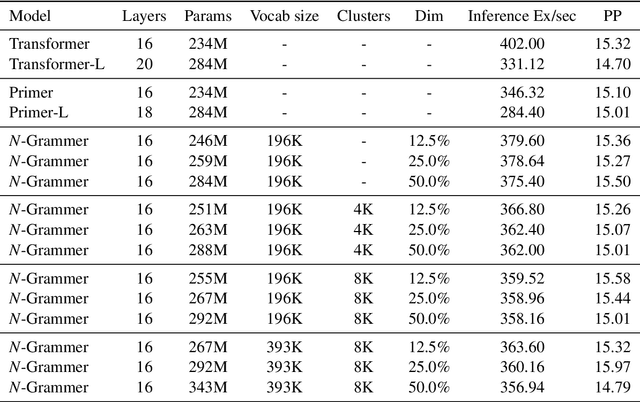

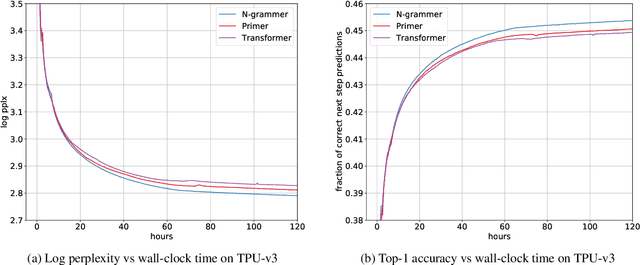
Transformer models have recently emerged as one of the foundational models in natural language processing, and as a byproduct, there is significant recent interest and investment in scaling these models. However, the training and inference costs of these large Transformer language models are prohibitive, thus necessitating more research in identifying more efficient variants. In this work, we propose a simple yet effective modification to the Transformer architecture inspired by the literature in statistical language modeling, by augmenting the model with n-grams that are constructed from a discrete latent representation of the text sequence. We evaluate our model, the N-Grammer on language modeling on the C4 data-set as well as text classification on the SuperGLUE data-set, and find that it outperforms several strong baselines such as the Transformer and the Primer. We open-source our model for reproducibility purposes in Jax.
Hurdles to Progress in Long-form Question Answering
Mar 10, 2021
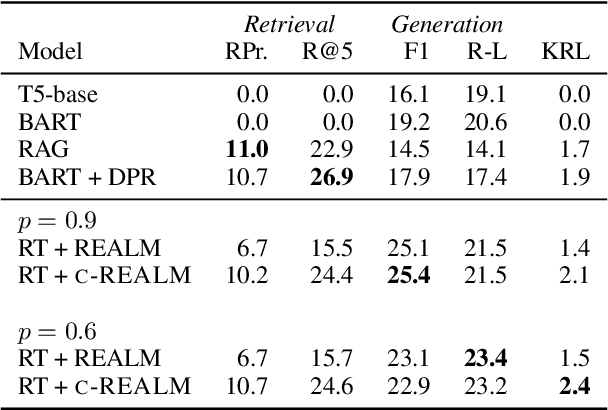

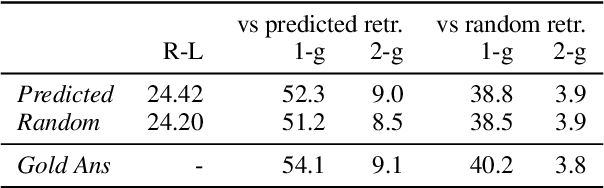
The task of long-form question answering (LFQA) involves retrieving documents relevant to a given question and using them to generate a paragraph-length answer. While many models have recently been proposed for LFQA, we show in this paper that the task formulation raises fundamental challenges regarding evaluation and dataset creation that currently preclude meaningful modeling progress. To demonstrate these challenges, we first design a new system that relies on sparse attention and contrastive retriever learning to achieve state-of-the-art performance on the ELI5 LFQA dataset. While our system tops the public leaderboard, a detailed analysis reveals several troubling trends: (1) our system's generated answers are not actually grounded in the documents that it retrieves; (2) ELI5 contains significant train / test overlap, as at least 81% of ELI5 validation questions occur in paraphrased form in the training set; (3) ROUGE-L is not an informative metric of generated answer quality and can be easily gamed; and (4) human evaluations used for other text generation tasks are unreliable for LFQA. We provide suggestions to mitigate each of these issues, which we hope will lead to more rigorous LFQA research and meaningful progress in the future.
Efficient Content-Based Sparse Attention with Routing Transformers
Mar 12, 2020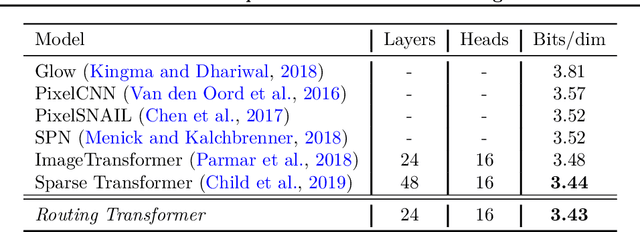
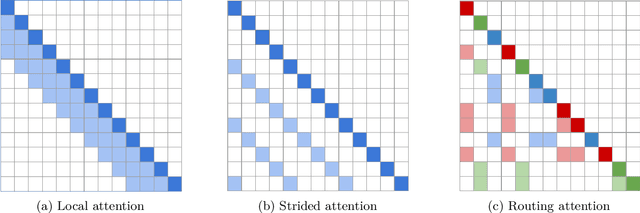
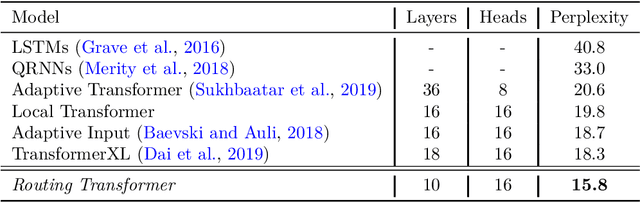

Self-attention has recently been adopted for a wide range of sequence modeling problems. Despite its effectiveness, self-attention suffers from quadratic compute and memory requirements with respect to sequence length. Successful approaches to reduce this complexity focused on attending to local sliding windows or a small set of locations independent of content. Our work proposes to learn dynamic sparse attention patterns that avoid allocating computation and memory to attend to content unrelated to the query of interest. This work builds upon two lines of research: it combines the modeling flexibility of prior work on content-based sparse attention with the efficiency gains from approaches based on local, temporal sparse attention. Our model, the Routing Transformer, endows self-attention with a sparse routing module based on online k-means while reducing the overall complexity of attention to $O\left(n^{1.5}d\right)$ from $O\left(n^2d\right)$ for sequence length $n$ and hidden dimension $d$. We show that our model outperforms comparable sparse attention models on language modeling on Wikitext-103 (15.8 vs 18.3 perplexity) as well as on image generation on ImageNet-64 (3.43 vs 3.44 bits/dim) while using fewer self-attention layers.
Unsupervised Paraphrasing without Translation
May 29, 2019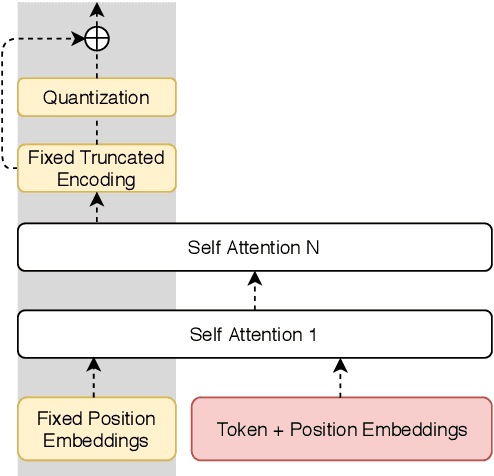
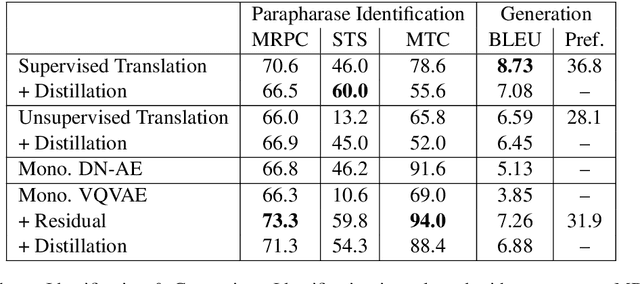
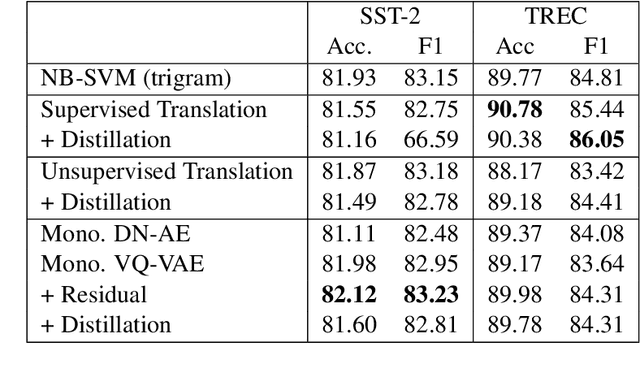
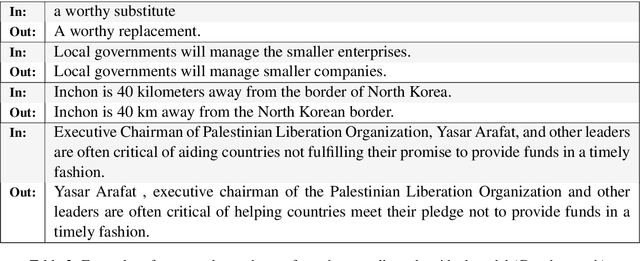
Paraphrasing exemplifies the ability to abstract semantic content from surface forms. Recent work on automatic paraphrasing is dominated by methods leveraging Machine Translation (MT) as an intermediate step. This contrasts with humans, who can paraphrase without being bilingual. This work proposes to learn paraphrasing models from an unlabeled monolingual corpus only. To that end, we propose a residual variant of vector-quantized variational auto-encoder. We compare with MT-based approaches on paraphrase identification, generation, and training augmentation. Monolingual paraphrasing outperforms unsupervised translation in all settings. Comparisons with supervised translation are more mixed: monolingual paraphrasing is interesting for identification and augmentation; supervised translation is superior for generation.
Understanding and Improving Interpolation in Autoencoders via an Adversarial Regularizer
Jul 23, 2018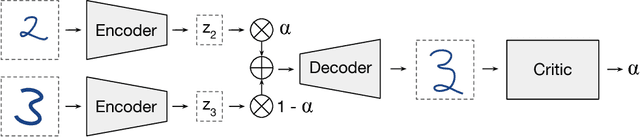
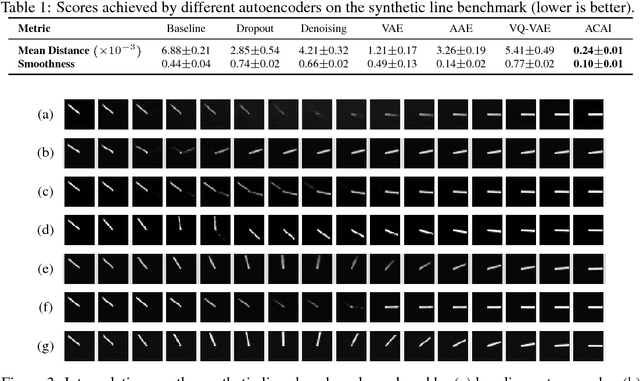

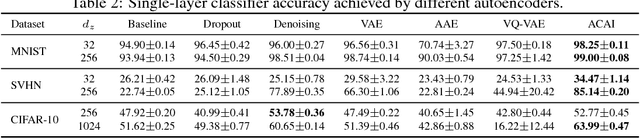
Autoencoders provide a powerful framework for learning compressed representations by encoding all of the information needed to reconstruct a data point in a latent code. In some cases, autoencoders can "interpolate": By decoding the convex combination of the latent codes for two datapoints, the autoencoder can produce an output which semantically mixes characteristics from the datapoints. In this paper, we propose a regularization procedure which encourages interpolated outputs to appear more realistic by fooling a critic network which has been trained to recover the mixing coefficient from interpolated data. We then develop a simple benchmark task where we can quantitatively measure the extent to which various autoencoders can interpolate and show that our regularizer dramatically improves interpolation in this setting. We also demonstrate empirically that our regularizer produces latent codes which are more effective on downstream tasks, suggesting a possible link between interpolation abilities and learning useful representations.
Theory and Experiments on Vector Quantized Autoencoders
Jul 20, 2018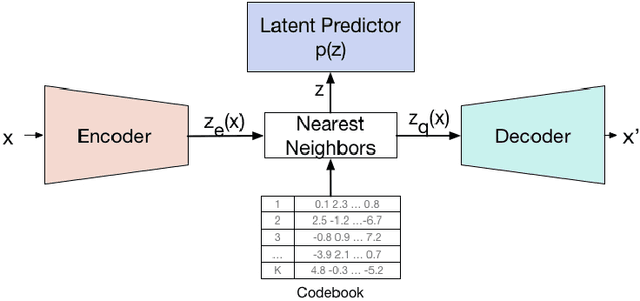
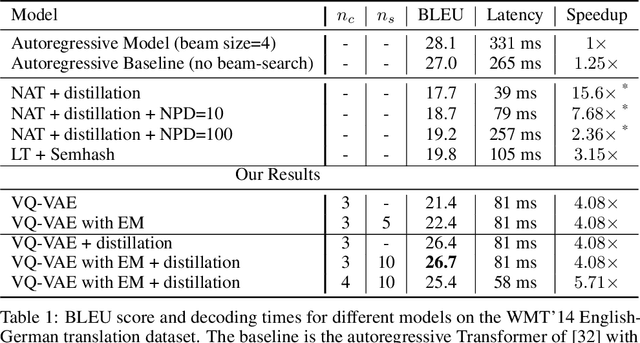
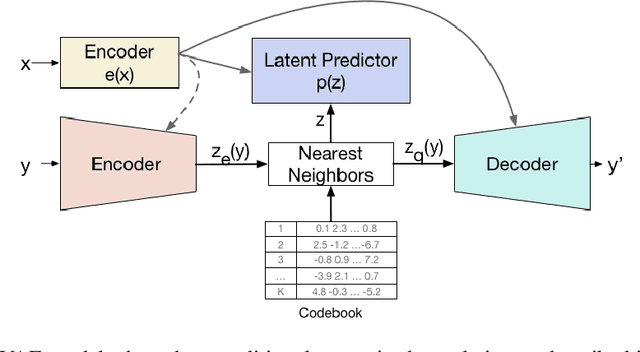

Deep neural networks with discrete latent variables offer the promise of better symbolic reasoning, and learning abstractions that are more useful to new tasks. There has been a surge in interest in discrete latent variable models, however, despite several recent improvements, the training of discrete latent variable models has remained challenging and their performance has mostly failed to match their continuous counterparts. Recent work on vector quantized autoencoders (VQ-VAE) has made substantial progress in this direction, with its perplexity almost matching that of a VAE on datasets such as CIFAR-10. In this work, we investigate an alternate training technique for VQ-VAE, inspired by its connection to the Expectation Maximization (EM) algorithm. Training the discrete bottleneck with EM helps us achieve better image generation results on CIFAR-10, and together with knowledge distillation, allows us to develop a non-autoregressive machine translation model whose accuracy almost matches a strong greedy autoregressive baseline Transformer, while being 3.3 times faster at inference.