 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVibe Checker: Aligning Code Evaluation with Human Preference
Oct 08, 2025



Large Language Models (LLMs) have catalyzed vibe coding, where users leverage LLMs to generate and iteratively refine code through natural language interactions until it passes their vibe check. Vibe check is tied to real-world human preference and goes beyond functionality: the solution should feel right, read cleanly, preserve intent, and remain correct. However, current code evaluation remains anchored to pass@k and captures only functional correctness, overlooking the non-functional instructions that users routinely apply. In this paper, we hypothesize that instruction following is the missing piece underlying vibe check that represents human preference in coding besides functional correctness. To quantify models' code instruction following capabilities with measurable signals, we present VeriCode, a taxonomy of 30 verifiable code instructions together with corresponding deterministic verifiers. We use the taxonomy to augment established evaluation suites, resulting in Vibe Checker, a testbed to assess both code instruction following and functional correctness. Upon evaluating 31 leading LLMs, we show that even the strongest models struggle to comply with multiple instructions and exhibit clear functional regression. Most importantly, a composite score of functional correctness and instruction following correlates the best with human preference, with the latter emerging as the primary differentiator on real-world programming tasks. Our work identifies core factors of the vibe check, providing a concrete path for benchmarking and developing models that better align with user preferences in coding.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
How to Ask Better Questions? A Large-Scale Multi-Domain Dataset for Rewriting Ill-Formed Questions
Nov 21, 2019
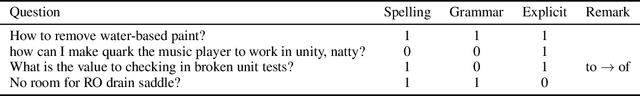


We present a large-scale dataset for the task of rewriting an ill-formed natural language question to a well-formed one. Our multi-domain question rewriting MQR dataset is constructed from human contributed Stack Exchange question edit histories. The dataset contains 427,719 question pairs which come from 303 domains. We provide human annotations for a subset of the dataset as a quality estimate. When moving from ill-formed to well-formed questions, the question quality improves by an average of 45 points across three aspects. We train sequence-to-sequence neural models on the constructed dataset and obtain an improvement of 13.2% in BLEU-4 over baseline methods built from other data resources. We release the MQR dataset to encourage research on the problem of question rewriting.