 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond English: Uncovering the Multilingual Gap in Vision-Language-Action Models
Jun 14, 2026Vision-Language-Action models have recently demonstrated promising capabilities in learning generalist robot policies from large-scale multimodal data. However, most existing VLA systems are trained and evaluated primarily with English instructions, leaving their ability to understand and execute instructions in other languages largely unexplored. While the underlying large language models often possess multilingual capabilities, it remains unclear whether these multilingual capabilities transfer to VLAs during training. In this work, we present the first systematic study of multilingual instruction following in VLA models. We first construct multilingual instructions by extending existing benchmarks with translations of their instructions. Using these instructions, we evaluate several representative VLA models across a range of tasks in simulation settings. Our experiments reveal a significant multilingual gap: models trained primarily on English instructions exhibit substantial performance degradation when evaluated on other languages, even when the underlying language backbone is multilingual. We provide several findings and analyses to understand the multilingual gap. Cross-lingual transfer behavior analysis shows that performance drops correlate with both instruction understanding and action execution. Representation analyses suggest that multilingual instruction-caused representation shifts may contribute to the multilingual gap. Motivated by these findings, we further explore strategies to improve multilingual performance in VLAs. We propose a simple yet effective multilingual fine-tuning approach, Multilingual Principal Component Alignment, which leverages Principal Component Analysis to get the principal component subspace and align projected multilingual representations, effectively reducing the multilingual performance gap.
HiFloat4 Format for Language Model Pre-training on Ascend NPUs
Apr 09, 2026Large foundation models have become central to modern machine learning, with performance scaling predictably with model size and data. However, training and deploying such models incur substantial computational and memory costs, motivating the development of low-precision training techniques. Recent work has demonstrated that 4-bit floating-point (FP4) formats--such as MXFP4 and NVFP4--can be successfully applied to linear GEMM operations in large language models (LLMs), achieving up to 4x improvements in compute throughput and memory efficiency compared to higher-precision baselines. In this work, we investigate the recently proposed HiFloat4 FP4 format for Huawei Ascend NPUs and systematically compare it with MXFP4 in large-scale training settings. All experiments are conducted on Ascend NPU clusters, with linear and expert GEMM operations performed entirely in FP4 precision. We evaluate both dense architectures (e.g., Pangu and LLaMA-style models) and mixture-of-experts (MoE) models, where both standard linear layers and expert-specific GEMMs operate in FP4. Furthermore, we explore stabilization techniques tailored to FP4 training that significantly reduce numerical degradation, maintaining relative error within 1% of full-precision baselines while preserving the efficiency benefits of 4-bit computation. Our results provide a comprehensive empirical study of FP4 training on NPUs and highlight the practical trade-offs between FP4 formats in large-scale dense and MoE models.
SAVA-X: Ego-to-Exo Imitation Error Detection via Scene-Adaptive View Alignment and Bidirectional Cross View Fusion
Mar 13, 2026Error detection is crucial in industrial training, healthcare, and assembly quality control. Most existing work assumes a single-view setting and cannot handle the practical case where a third-person (exo) demonstration is used to assess a first-person (ego) imitation. We formalize Ego$\rightarrow$Exo Imitation Error Detection: given asynchronous, length-mismatched ego and exo videos, the model must localize procedural steps on the ego timeline and decide whether each is erroneous. This setting introduces cross-view domain shift, temporal misalignment, and heavy redundancy. Under a unified protocol, we adapt strong baselines from dense video captioning and temporal action detection and show that they struggle in this cross-view regime. We then propose SAVA-X, an Align-Fuse-Detect framework with (i) view-conditioned adaptive sampling, (ii) scene-adaptive view embeddings, and (iii) bidirectional cross-attention fusion. On the EgoMe benchmark, SAVA-X consistently improves AUPRC and mean tIoU over all baselines, and ablations confirm the complementary benefits of its components. Code is available at https://github.com/jack1ee/SAVAX.
Continual Learning with Vision-Language Models via Semantic-Geometry Preservation
Mar 12, 2026Continual learning of pretrained vision-language models (VLMs) is prone to catastrophic forgetting, yet current approaches adapt to new tasks without explicitly preserving the cross-modal semantic geometry inherited from pretraining and previous stages, allowing new-task supervision to induce geometric distortion. We observe that the most pronounced drift tends to concentrate in vulnerable neighborhoods near the old-new semantic interface, where shared visual patterns are easily re-explained by new textual semantics. To address this under an exemplar-free constraint, we propose Semantic Geometry Preservation for Continual Learning (SeGP-CL). SeGP-CL first probes the drift-prone region by constructing a compact set of adversarial anchors with dual-targeted projected gradient descent (DPGD), which drives selected new-task seeds toward old-class semantics while remaining faithful in raw visual space. During training, we preserve cross-modal structure by anchor-guided cross-modal geometry distillation (ACGD), and stabilize the textual reference frame across tasks via a lightweight text semantic-geometry regularization (TSGR). After training, we estimate anchor-induced raw-space drift to transfer old visual prototypes and perform dual-path inference by fusing cross-modal and visual cues. Extensive experiments on five continual learning benchmarks demonstrate that SeGP-CL consistently improves stability and forward transfer, achieving state-of-the-art performance while better preserving semantic geometry of VLMs.
CoViLLM: An Adaptive Human-Robot Collaborative Assembly Framework Using Large Language Models for Manufacturing
Mar 12, 2026With increasing demand for mass customization, traditional manufacturing robots that rely on rule-based operations lack the flexibility to accommodate customized or new product variants. Human-Robot Collaboration (HRC) has demonstrated potential to improve system adaptability by leveraging human versatility and decision-making capabilities. However, existing HRC frame- works typically depend on predefined perception-manipulation pipelines, limiting their ability to autonomously generate task plans for new product assembly. In this work, we propose CoViLLM, an adaptive human-robot collaborative assembly frame- work that supports the assembly of customized and previously unseen products. CoViLLM combines depth-camera-based localization for object position estimation, human operator classification for identifying new components, and an Large Language Model (LLM) for assembly task planning based on natural language instructions. The framework is validated on the NIST Assembly Task Board for known, customized, and new product cases. Experimental results show that the proposed framework enables flexible collaborative assembly by extending HRC beyond predefined product and task settings.
Test-time Ego-Exo-centric Adaptation for Action Anticipation via Multi-Label Prototype Growing and Dual-Clue Consistency
Mar 10, 2026Efficient adaptation between Egocentric (Ego) and Exocentric (Exo) views is crucial for applications such as human-robot cooperation. However, the success of most existing Ego-Exo adaptation methods relies heavily on target-view data for training, thereby increasing computational and data collection costs. In this paper, we make the first exploration of a Test-time Ego-Exo Adaptation for Action Anticipation (TE$^{2}$A$^{3}$) task, which aims to adjust the source-view-trained model online during test time to anticipate target-view actions. It is challenging for existing Test-Time Adaptation (TTA) methods to address this task due to the multi-action candidates and significant temporal-spatial inter-view gap. Hence, we propose a novel Dual-Clue enhanced Prototype Growing Network (DCPGN), which accumulates multi-label knowledge and integrates cross-modality clues for effective test-time Ego-Exo adaptation and action anticipation. Specifically, we propose a Multi-Label Prototype Growing Module (ML-PGM) to balance multiple positive classes via multi-label assignment and confidence-based reweighting for class-wise memory banks, which are updated by an entropy priority queue strategy. Then, the Dual-Clue Consistency Module (DCCM) introduces a lightweight narrator to generate textual clues indicating action progressions, which complement the visual clues containing various objects. Moreover, we constrain the inferred textual and visual logits to construct dual-clue consistency for temporally and spatially bridging Ego and Exo views. Extensive experiments on the newly proposed EgoMe-anti and the existing EgoExoLearn benchmarks show the effectiveness of our method, which outperforms related state-of-the-art methods by a large margin. Code is available at \href{https://github.com/ZhaofengSHI/DCPGN}{https://github.com/ZhaofengSHI/DCPGN}.
Training-Free Acceleration for Document Parsing Vision-Language Model with Hierarchical Speculative Decoding
Feb 13, 2026Document parsing is a fundamental task in multimodal understanding, supporting a wide range of downstream applications such as information extraction and intelligent document analysis. Benefiting from strong semantic modeling and robust generalization, VLM-based end-to-end approaches have emerged as the mainstream paradigm in recent years. However, these models often suffer from substantial inference latency, as they must auto-regressively generate long token sequences when processing long-form documents. In this work, motivated by the extremely long outputs and complex layout structures commonly found in document parsing, we propose a training-free and highly efficient acceleration method. Inspired by speculative decoding, we employ a lightweight document parsing pipeline as a draft model to predict batches of future tokens, while the more accurate VLM verifies these draft predictions in parallel. Moreover, we further exploit the layout-structured nature of documents by partitioning each page into independent regions, enabling parallel decoding of each region using the same draft-verify strategy. The final predictions are then assembled according to the natural reading order. Experimental results demonstrate the effectiveness of our approach: on the general-purpose OmniDocBench, our method provides a 2.42x lossless acceleration for the dots.ocr model, and achieves up to 4.89x acceleration on long-document parsing tasks. We will release our code to facilitate reproducibility and future research.
Toward Enhancing Representation Learning in Federated Multi-Task Settings
Feb 02, 2026Federated multi-task learning (FMTL) seeks to collaboratively train customized models for users with different tasks while preserving data privacy. Most existing approaches assume model congruity (i.e., the use of fully or partially homogeneous models) across users, which limits their applicability in realistic settings. To overcome this limitation, we aim to learn a shared representation space across tasks rather than shared model parameters. To this end, we propose Muscle loss, a novel contrastive learning objective that simultaneously aligns representations from all participating models. Unlike existing multi-view or multi-model contrastive methods, which typically align models pairwise, Muscle loss can effectively capture dependencies across tasks because its minimization is equivalent to the maximization of mutual information among all the models' representations. Building on this principle, we develop FedMuscle, a practical and communication-efficient FMTL algorithm that naturally handles both model and task heterogeneity. Experiments on diverse image and language tasks demonstrate that FedMuscle consistently outperforms state-of-the-art baselines, delivering substantial improvements and robust performance across heterogeneous settings.
Language-Coupled Reinforcement Learning for Multilingual Retrieval-Augmented Generation
Jan 21, 2026Multilingual retrieval-augmented generation (MRAG) requires models to effectively acquire and integrate beneficial external knowledge from multilingual collections. However, most existing studies employ a unitive process where queries of equivalent semantics across different languages are processed through a single-turn retrieval and subsequent optimization. Such a ``one-size-fits-all'' strategy is often suboptimal in multilingual settings, as the models occur to knowledge bias and conflict during the interaction with the search engine. To alleviate the issues, we propose LcRL, a multilingual search-augmented reinforcement learning framework that integrates a language-coupled Group Relative Policy Optimization into the policy and reward models. We adopt the language-coupled group sampling in the rollout module to reduce knowledge bias, and regularize an auxiliary anti-consistency penalty in the reward models to mitigate the knowledge conflict. Experimental results demonstrate that LcRL not only achieves competitive performance but is also appropriate for various practical scenarios such as constrained training data and retrieval over collections encompassing a large number of languages. Our code is available at https://github.com/Cherry-qwq/LcRL-Open.
DK-STN: A Domain Knowledge Embedded Spatio-Temporal Network Model for MJO Forecast
Dec 22, 2025
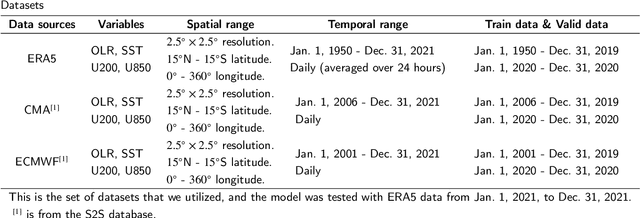
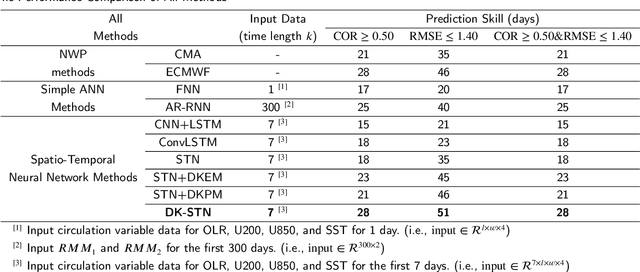

Understanding and predicting the Madden-Julian Oscillation (MJO) is fundamental for precipitation forecasting and disaster prevention. To date, long-term and accurate MJO prediction has remained a challenge for researchers. Conventional MJO prediction methods using Numerical Weather Prediction (NWP) are resource-intensive, time-consuming, and highly unstable (most NWP methods are sensitive to seasons, with better MJO forecast results in winter). While existing Artificial Neural Network (ANN) methods save resources and speed forecasting, their accuracy never reaches the 28 days predicted by the state-of-the-art NWP method, i.e., the operational forecasts from ECMWF, since neural networks cannot handle climate data effectively. In this paper, we present a Domain Knowledge Embedded Spatio-Temporal Network (DK-STN), a stable neural network model for accurate and efficient MJO forecasting. It combines the benefits of NWP and ANN methods and successfully improves the forecast accuracy of ANN methods while maintaining a high level of efficiency and stability. We begin with a spatial-temporal network (STN) and embed domain knowledge in it using two key methods: (i) applying a domain knowledge enhancement method and (ii) integrating a domain knowledge processing method into network training. We evaluated DK-STN with the 5th generation of ECMWF reanalysis (ERA5) data and compared it with ECMWF. Given 7 days of climate data as input, DK-STN can generate reliable forecasts for the following 28 days in 1-2 seconds, with an error of only 2-3 days in different seasons. DK-STN significantly exceeds ECMWF in that its forecast accuracy is equivalent to ECMWF's, while its efficiency and stability are significantly superior.