 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQiaozhu Mei
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 09, 2022
Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Partition-Based Active Learning for Graph Neural Networks
Jan 23, 2022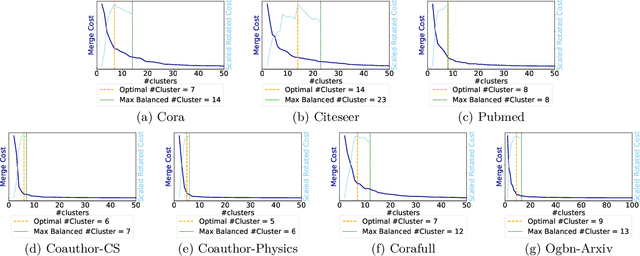
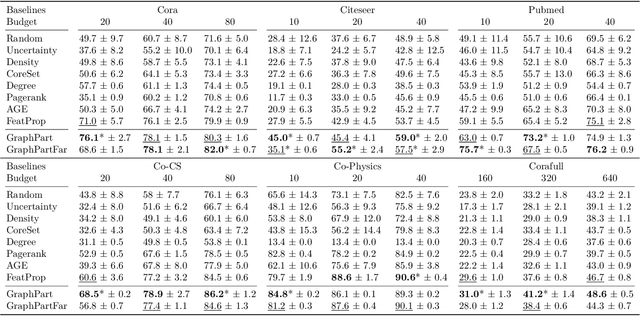
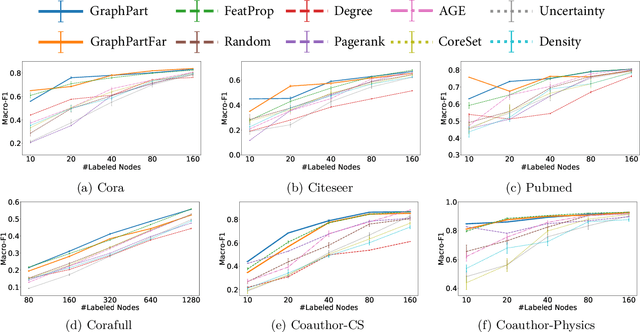
We study the problem of semi-supervised learning with Graph Neural Networks (GNNs) in an active learning setup. We propose GraphPart, a novel partition-based active learning approach for GNNs. GraphPart first splits the graph into disjoint partitions and then selects representative nodes within each partition to query. The proposed method is motivated by a novel analysis of the classification error under realistic smoothness assumptions over the graph and the node features. Extensive experiments on multiple benchmark datasets demonstrate that the proposed method outperforms existing active learning methods for GNNs under a wide range of annotation budget constraints. In addition, the proposed method does not introduce additional hyperparameters, which is crucial for model training, especially in the active learning setting where a labeled validation set may not be available.
Fast Learning of MNL Model from General Partial Rankings with Application to Network Formation Modeling
Dec 31, 2021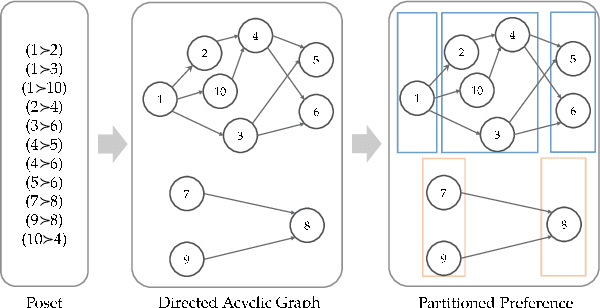
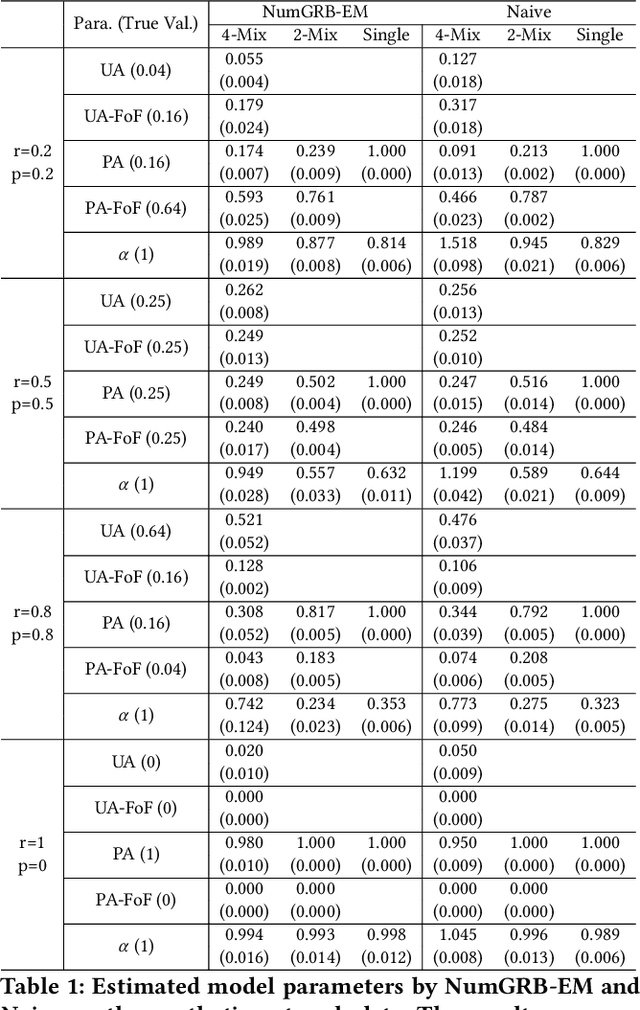
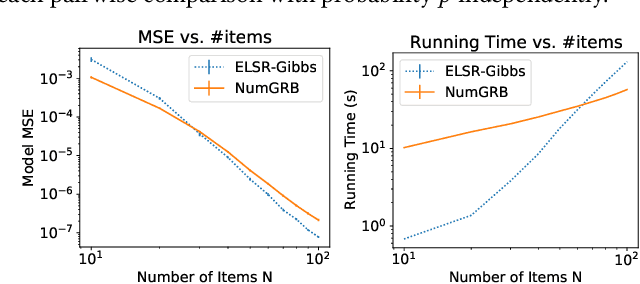
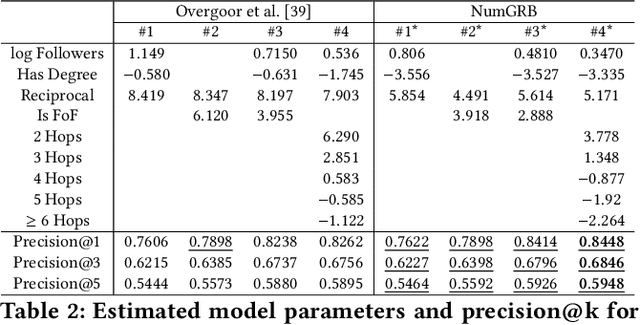
Multinomial Logit (MNL) is one of the most popular discrete choice models and has been widely used to model ranking data. However, there is a long-standing technical challenge of learning MNL from many real-world ranking data: exact calculation of the MNL likelihood of \emph{partial rankings} is generally intractable. In this work, we develop a scalable method for approximating the MNL likelihood of general partial rankings in polynomial time complexity. We also extend the proposed method to learn mixture of MNL. We demonstrate that the proposed methods are particularly helpful for applications to choice-based network formation modeling, where the formation of new edges in a network is viewed as individuals making choices of their friends over a candidate set. The problem of learning mixture of MNL models from partial rankings naturally arises in such applications. And the proposed methods can be used to learn MNL models from network data without the strong assumption that temporal orders of all the edge formation are available. We conduct experiments on both synthetic and real-world network data to demonstrate that the proposed methods achieve more accurate parameter estimation and better fitness of data compared to conventional methods.
How Much of the Chemical Space Has Been Covered? Measuring and Improving the Variety of Candidate Set in Molecular Generation
Dec 22, 2021
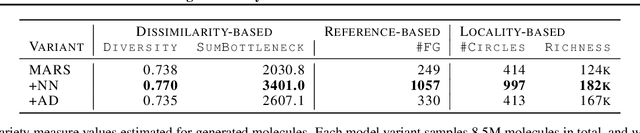
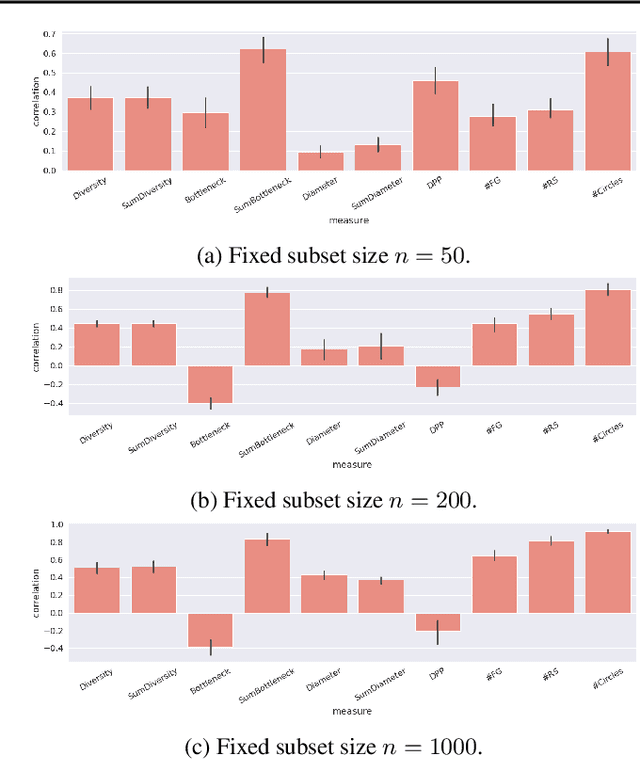
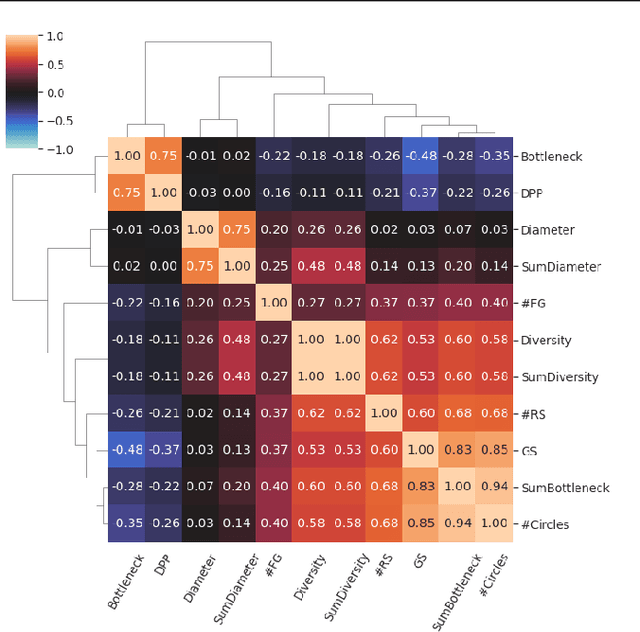
Forming a high-quality molecular candidate set that contains a wide range of dissimilar compounds is crucial to the success of drug discovery. However, comparing to the research aiming at optimizing chemical properties, how to measure and improve the variety of drug candidates is relatively understudied. In this paper, we first investigate the problem of properly measuring the molecular variety through both an axiomatic analysis framework and an empirical study. Our analysis suggests that many existing measures are not suitable for evaluating the variety of molecules. We also propose new variety measures based on our analysis. We further explicitly integrate the proposed variety measures into the optimization objective of molecular generation models. Our experiment results demonstrate that this new optimization objective can guide molecular generation models to find compounds that cover a lager chemical space, providing the downstream phases with more distinctive drug candidate choices.
Subgroup Generalization and Fairness of Graph Neural Networks
Jun 29, 2021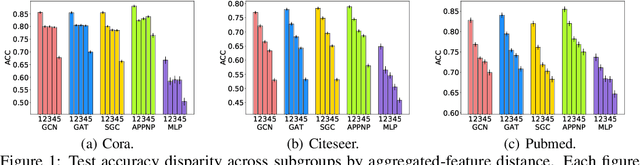

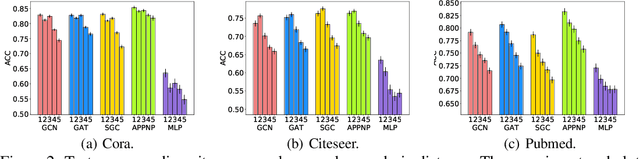
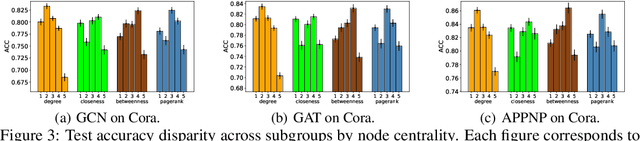
Despite enormous successful applications of graph neural networks (GNNs) recently, theoretical understandings of their generalization ability, especially for node-level tasks where data are not independent and identically-distributed (IID), have been sparse. The theoretical investigation of the generalization performance is beneficial for understanding fundamental issues (such as fairness) of GNN models and designing better learning methods. In this paper, we present a novel PAC-Bayesian analysis for GNNs under a non-IID semi-supervised learning setup. Moreover, we analyze the generalization performances on different subgroups of unlabeled nodes, which allows us to further study an accuracy-(dis)parity-style (un)fairness of GNNs from a theoretical perspective. Under reasonable assumptions, we demonstrate that the distance between a test subgroup and the training set can be a key factor affecting the GNN performance on that subgroup, which calls special attention to the training node selection for fair learning. Experiments across multiple GNN models and datasets support our theoretical results.
Adversarial Attack on Graph Neural Networks as An Influence Maximization Problem
Jun 21, 2021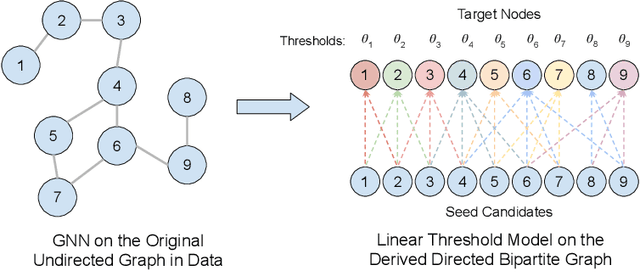
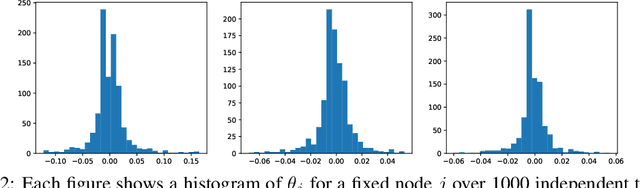
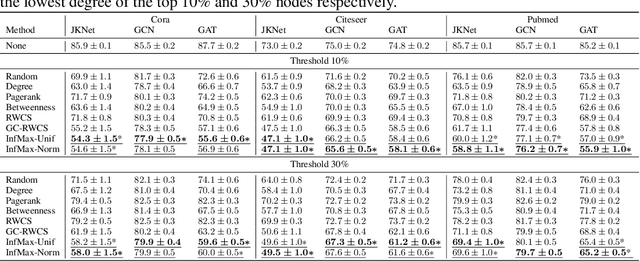
Graph neural networks (GNNs) have attracted increasing interests. With broad deployments of GNNs in real-world applications, there is an urgent need for understanding the robustness of GNNs under adversarial attacks, especially in realistic setups. In this work, we study the problem of attacking GNNs in a restricted and realistic setup, by perturbing the features of a small set of nodes, with no access to model parameters and model predictions. Our formal analysis draws a connection between this type of attacks and an influence maximization problem on the graph. This connection not only enhances our understanding on the problem of adversarial attack on GNNs, but also allows us to propose a group of effective and practical attack strategies. Our experiments verify that the proposed attack strategies significantly degrade the performance of three popular GNN models and outperform baseline adversarial attack strategies.
Emojis Predict Dropouts of Remote Workers: An Empirical Study of Emoji Usage on GitHub
Feb 10, 2021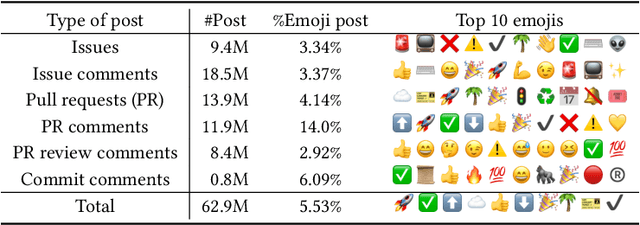
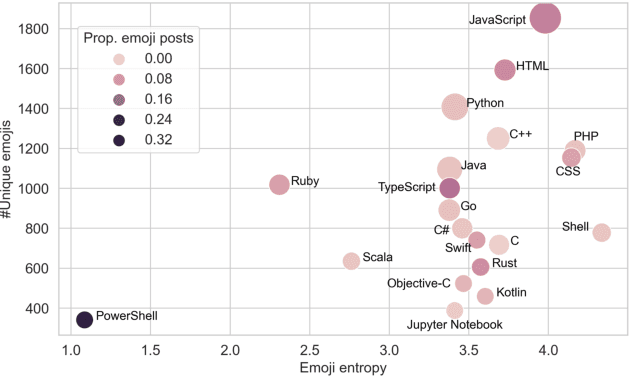
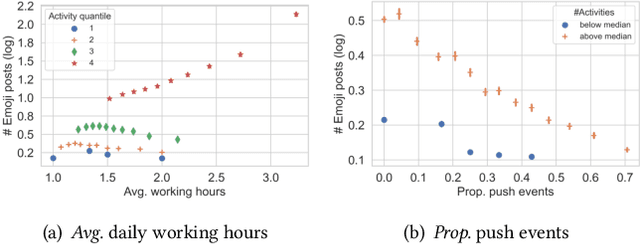
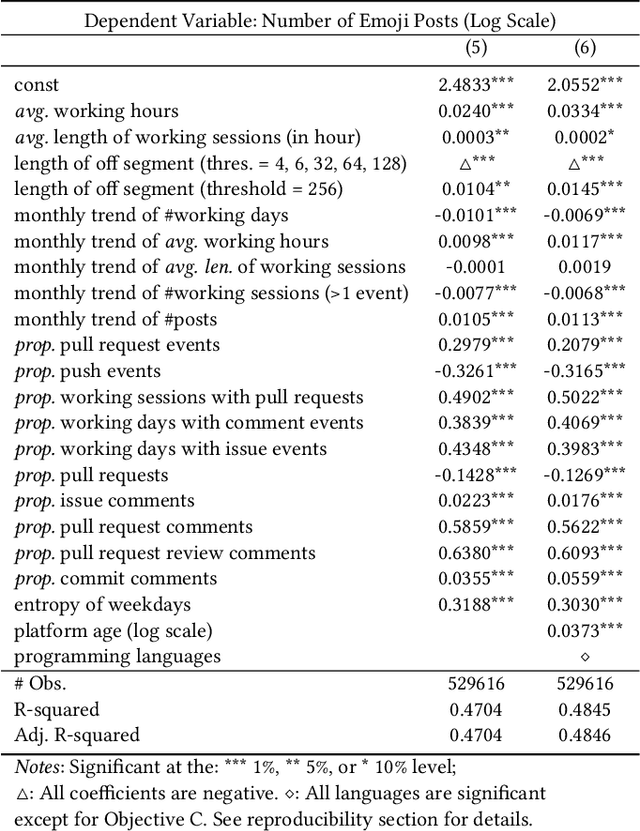
Emotions at work have long been identified as critical signals of work motivations, status, and attitudes, and as predictors of various work-related outcomes. For example, harmonious passion increases commitment at work but stress reduces sustainability and leads to burnouts. When more and more employees work remotely, these emotional and mental health signals of workers become harder to observe through daily, face-to-face communications. The use of online platforms to communicate and collaborate at work provides an alternative channel to monitor the emotions of workers. This paper studies how emojis, as non-verbal cues in online communications, can be used for such purposes. In particular, we study how the developers on GitHub use emojis in their work-related activities. We show that developers have diverse patterns of emoji usage, which highly correlate to their working status including activity levels, types of work, types of communications, time management, and other behavioral patterns. Developers who use emojis in their posts are significantly less likely to dropout from the online work platform. Surprisingly, solely using emoji usage as features, standard machine learning models can predict future dropouts of developers at a satisfactory accuracy.
CopulaGNN: Towards Integrating Representational and Correlational Roles of Graphs in Graph Neural Networks
Oct 05, 2020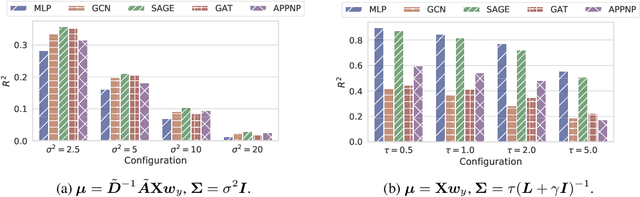
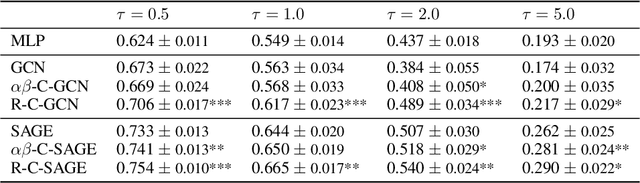
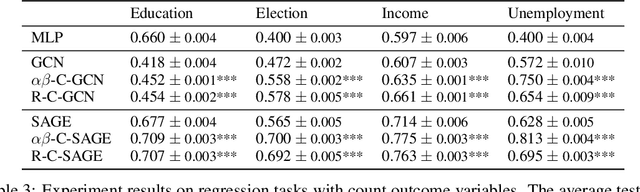
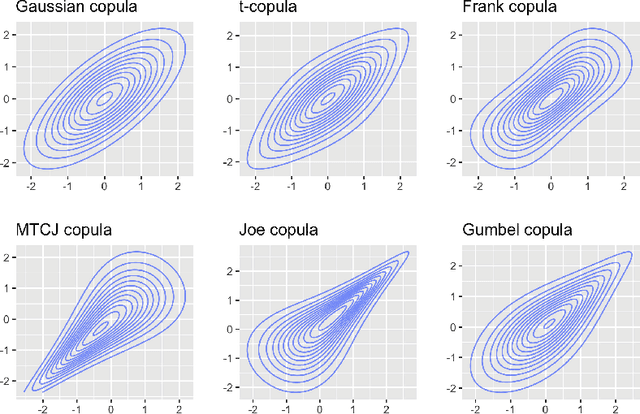
Graph-structured data are ubiquitous. However, graphs encode diverse types of information and thus play different roles in data representation. In this paper, we distinguish the \textit{representational} and the \textit{correlational} roles played by the graphs in node-level prediction tasks, and we investigate how Graph Neural Network (GNN) models can effectively leverage both types of information. Conceptually, the representational information provides guidance for the model to construct better node features; while the correlational information indicates the correlation between node outcomes conditional on node features. Through a simulation study, we find that many popular GNN models are incapable of effectively utilizing the correlational information. By leveraging the idea of the copula, a principled way to describe the dependence among multivariate random variables, we offer a general solution. The proposed Copula Graph Neural Network (CopulaGNN) can take a wide range of GNN models as base models and utilize both representational and correlational information stored in the graphs. Experimental results on two types of regression tasks verify the effectiveness of the proposed method.
SODEN: A Scalable Continuous-Time Survival Model through Ordinary Differential Equation Networks
Aug 19, 2020
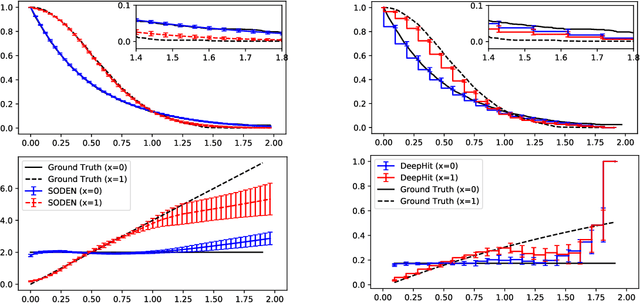
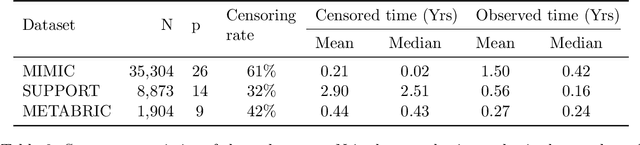
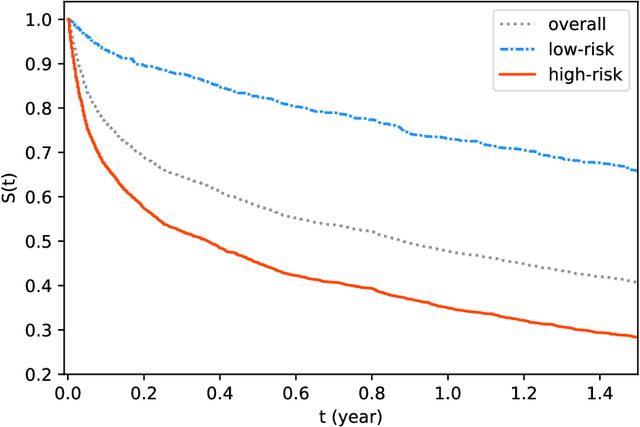
In this paper, we propose a flexible model for survival analysis using neural networks along with scalable optimization algorithms. One key technical challenge for directly applying maximum likelihood estimation (MLE) to censored data is that evaluating the objective function and its gradients with respect to model parameters requires the calculation of integrals. To address this challenge, we recognize that the MLE for censored data can be viewed as a differential-equation constrained optimization problem, a novel perspective. Following this connection, we model the distribution of event time through an ordinary differential equation and utilize efficient ODE solvers and adjoint sensitivity analysis to numerically evaluate the likelihood and the gradients. Using this approach, we are able to 1) provide a broad family of continuous-time survival distributions without strong structural assumptions, 2) obtain powerful feature representations using neural networks, and 3) allow efficient estimation of the model in large-scale applications using stochastic gradient descent. Through both simulation studies and real-world data examples, we demonstrate the effectiveness of the proposed method in comparison to existing state-of-the-art deep learning survival analysis models.
Predicting Individual Treatment Effects of Large-scale Team Competitions in a Ride-sharing Economy
Aug 07, 2020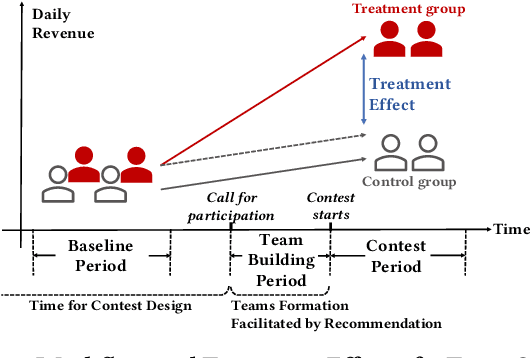

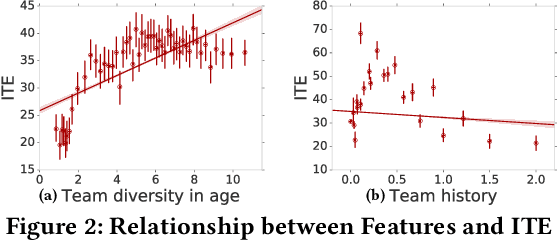
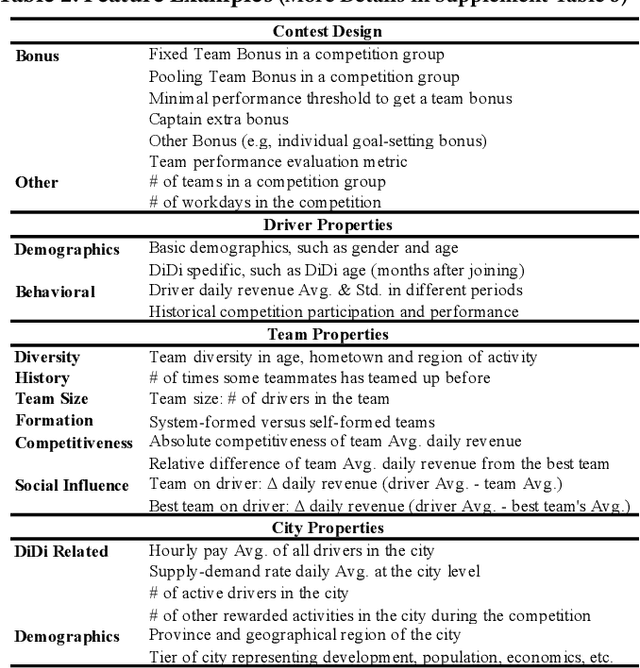
Millions of drivers worldwide have enjoyed financial benefits and work schedule flexibility through a ride-sharing economy, but meanwhile they have suffered from the lack of a sense of identity and career achievement. Equipped with social identity and contest theories, financially incentivized team competitions have been an effective instrument to increase drivers' productivity, job satisfaction, and retention, and to improve revenue over cost for ride-sharing platforms. While these competitions are overall effective, the decisive factors behind the treatment effects and how they affect the outcomes of individual drivers have been largely mysterious. In this study, we analyze data collected from more than 500 large-scale team competitions organized by a leading ride-sharing platform, building machine learning models to predict individual treatment effects. Through a careful investigation of features and predictors, we are able to reduce out-sample prediction error by more than 24%. Through interpreting the best-performing models, we discover many novel and actionable insights regarding how to optimize the design and the execution of team competitions on ride-sharing platforms. A simulated analysis demonstrates that by simply changing a few contest design options, the average treatment effect of a real competition is expected to increase by as much as 26%. Our procedure and findings shed light on how to analyze and optimize large-scale online field experiments in general.