 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal or Fake Text?: Investigating Human Ability to Detect Boundaries Between Human-Written and Machine-Generated Text
Dec 24, 2022



As text generated by large language models proliferates, it becomes vital to understand how humans engage with such text, and whether or not they are able to detect when the text they are reading did not originate with a human writer. Prior work on human detection of generated text focuses on the case where an entire passage is either human-written or machine-generated. In this paper, we study a more realistic setting where text begins as human-written and transitions to being generated by state-of-the-art neural language models. We show that, while annotators often struggle at this task, there is substantial variance in annotator skill and that given proper incentives, annotators can improve at this task over time. Furthermore, we conduct a detailed comparison study and analyze how a variety of variables (model size, decoding strategy, fine-tuning, prompt genre, etc.) affect human detection performance. Finally, we collect error annotations from our participants and use them to show that certain textual genres influence models to make different types of errors and that certain sentence-level features correlate highly with annotator selection. We release the RoFT dataset: a collection of over 21,000 human annotations paired with error classifications to encourage future work in human detection and evaluation of generated text.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
RoFT: A Tool for Evaluating Human Detection of Machine-Generated Text
Oct 06, 2020

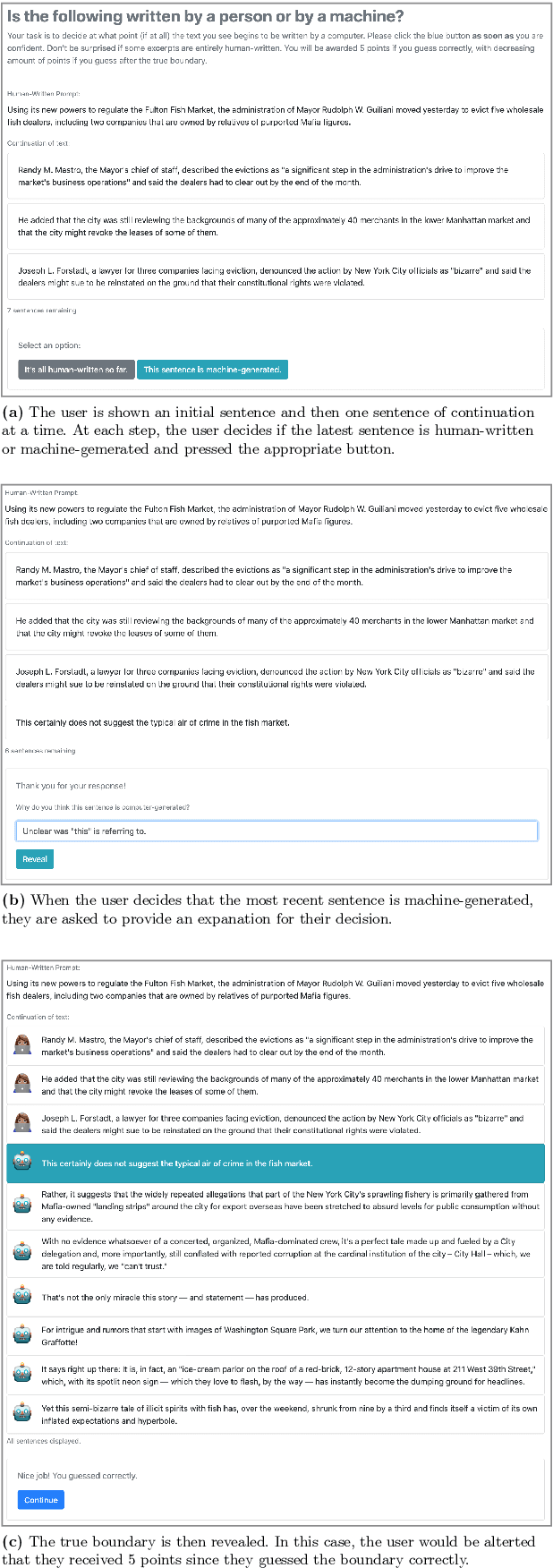
In recent years, large neural networks for natural language generation (NLG) have made leaps and bounds in their ability to generate fluent text. However, the tasks of evaluating quality differences between NLG systems and understanding how humans perceive the generated text remain both crucial and difficult. In this system demonstration, we present Real or Fake Text (RoFT), a website that tackles both of these challenges by inviting users to try their hand at detecting machine-generated text in a variety of domains. We introduce a novel evaluation task based on detecting the boundary at which a text passage that starts off human-written transitions to being machine-generated. We show preliminary results of using RoFT to evaluate detection of machine-generated news articles.