 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Dataset Combination
Feb 09, 2025



Access to diverse, high-quality datasets is crucial for machine learning model performance, yet data sharing remains limited by privacy concerns and competitive interests, particularly in regulated domains like healthcare. This dynamic especially disadvantages smaller organizations that lack resources to purchase data or negotiate favorable sharing agreements. We present SecureKL, a privacy-preserving framework that enables organizations to identify beneficial data partnerships without exposing sensitive information. Building on recent advances in dataset combination methods, we develop a secure multiparty computation protocol that maintains strong privacy guarantees while achieving >90\% correlation with plaintext evaluations. In experiments with real-world hospital data, SecureKL successfully identifies beneficial data partnerships that improve model performance for intensive care unit mortality prediction while preserving data privacy. Our framework provides a practical solution for organizations seeking to leverage collective data resources while maintaining privacy and competitive advantages. These results demonstrate the potential for privacy-preserving data collaboration to advance machine learning applications in high-stakes domains while promoting more equitable access to data resources.
Netflix and Forget: Efficient and Exact Machine Unlearning from Bi-linear Recommendations
Feb 13, 2023People break up, miscarry, and lose loved ones. Their online streaming and shopping recommendations, however, do not necessarily update, and may serve as unhappy reminders of their loss. When users want to renege on their past actions, they expect the recommender platforms to erase selective data at the model level. Ideally, given any specified user history, the recommender can unwind or "forget", as if the record was not part of training. To that end, this paper focuses on simple but widely deployed bi-linear models for recommendations based on matrix completion. Without incurring the cost of re-training, and without degrading the model unnecessarily, we develop Unlearn-ALS by making a few key modifications to the fine-tuning procedure under Alternating Least Squares optimisation, thus applicable to any bi-linear models regardless of the training procedure. We show that Unlearn-ALS is consistent with retraining without \emph{any} model degradation and exhibits rapid convergence, making it suitable for a large class of existing recommenders.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Data Appraisal Without Data Sharing
Dec 11, 2020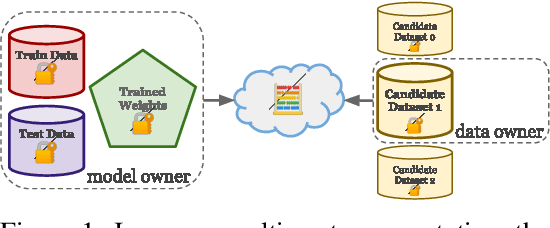

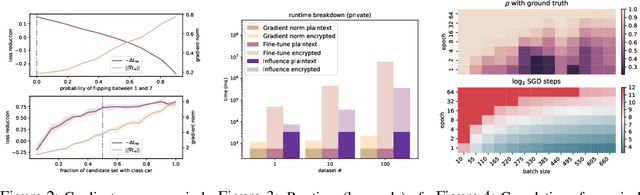
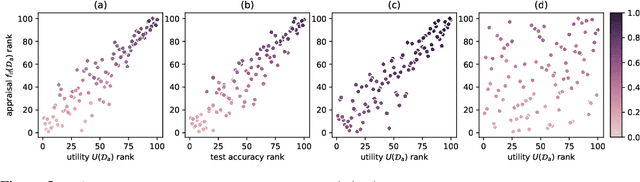
One of the most effective approaches to improving the performance of a machine-learning model is to acquire additional training data. To do so, a model owner may seek to acquire relevant training data from a data owner. Before procuring the data, the model owner needs to appraise the data. However, the data owner generally does not want to share the data until after an agreement is reached. The resulting Catch-22 prevents efficient data markets from forming. To address this problem, we develop data appraisal methods that do not require data sharing by using secure multi-party computation. Specifically, we study methods that: (1) compute parameter gradient norms, (2) perform model fine-tuning, and (3) compute influence functions. Our experiments show that influence functions provide an appealing trade-off between high-quality appraisal and required computation.