 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaST: Feature-aware Sampling and Tuning for Personalized Preference Alignment with Limited Data
Aug 06, 2025LLM-powered conversational assistants are often deployed in a one-size-fits-all manner, which fails to accommodate individual user preferences. Recently, LLM personalization -- tailoring models to align with specific user preferences -- has gained increasing attention as a way to bridge this gap. In this work, we specifically focus on a practical yet challenging setting where only a small set of preference annotations can be collected per user -- a problem we define as Personalized Preference Alignment with Limited Data (PPALLI). To support research in this area, we introduce two datasets -- DnD and ELIP -- and benchmark a variety of alignment techniques on them. We further propose FaST, a highly parameter-efficient approach that leverages high-level features automatically discovered from the data, achieving the best overall performance.
Compositional preference models for aligning LMs
Oct 17, 2023



As language models (LMs) become more capable, it is increasingly important to align them with human preferences. However, the dominant paradigm for training Preference Models (PMs) for that purpose suffers from fundamental limitations, such as lack of transparency and scalability, along with susceptibility to overfitting the preference dataset. We propose Compositional Preference Models (CPMs), a novel PM framework that decomposes one global preference assessment into several interpretable features, obtains scalar scores for these features from a prompted LM, and aggregates these scores using a logistic regression classifier. CPMs allow to control which properties of the preference data are used to train the preference model and to build it based on features that are believed to underlie the human preference judgment. Our experiments show that CPMs not only improve generalization and are more robust to overoptimization than standard PMs, but also that best-of-n samples obtained using CPMs tend to be preferred over samples obtained using conventional PMs. Overall, our approach demonstrates the benefits of endowing PMs with priors about which features determine human preferences while relying on LM capabilities to extract those features in a scalable and robust way.
Should you marginalize over possible tokenizations?
Jun 30, 2023



Autoregressive language models (LMs) map token sequences to probabilities. The usual practice for computing the probability of any character string (e.g. English sentences) is to first transform it into a sequence of tokens that is scored by the model. However, there are exponentially many token sequences that represent any given string. To truly compute the probability of a string one should marginalize over all tokenizations, which is typically intractable. Here, we analyze whether the practice of ignoring the marginalization is justified. To this end, we devise an importance-sampling-based algorithm that allows us to compute estimates of the marginal probabilities and compare them to the default procedure in a range of state-of-the-art models and datasets. Our results show that the gap in log-likelihood is no larger than 0.5% in most cases, but that it becomes more pronounced for data with long complex words.
disco: a toolkit for Distributional Control of Generative Models
Mar 08, 2023



Pre-trained language models and other generative models have revolutionized NLP and beyond. However, these models tend to reproduce undesirable biases present in their training data. Also, they may overlook patterns that are important but challenging to capture. To address these limitations, researchers have introduced distributional control techniques. These techniques, not limited to language, allow controlling the prevalence (i.e., expectations) of any features of interest in the model's outputs. Despite their potential, the widespread adoption of these techniques has been hindered by the difficulty in adapting complex, disconnected code. Here, we present disco, an open-source Python library that brings these techniques to the broader public.
Aligning Language Models with Preferences through f-divergence Minimization
Feb 16, 2023



Aligning language models with preferences can be posed as approximating a target distribution representing some desired behavior. Existing approaches differ both in the functional form of the target distribution and the algorithm used to approximate it. For instance, Reinforcement Learning from Human Feedback (RLHF) corresponds to minimizing a reverse KL from an implicit target distribution arising from a KL penalty in the objective. On the other hand, Generative Distributional Control (GDC) has an explicit target distribution and minimizes a forward KL from it using the Distributional Policy Gradient (DPG) algorithm. In this paper, we propose a new approach, f-DPG, which allows the use of any f-divergence to approximate any target distribution. f-DPG unifies both frameworks (RLHF, GDC) and the approximation methods (DPG, RL with KL penalties). We show the practical benefits of various choices of divergence objectives and demonstrate that there is no universally optimal objective but that different divergences are good for approximating different targets. For instance, we discover that for GDC, the Jensen-Shannon divergence frequently outperforms forward KL divergence by a wide margin, leading to significant improvements over prior work.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
On Reinforcement Learning and Distribution Matching for Fine-Tuning Language Models with no Catastrophic Forgetting
Jun 01, 2022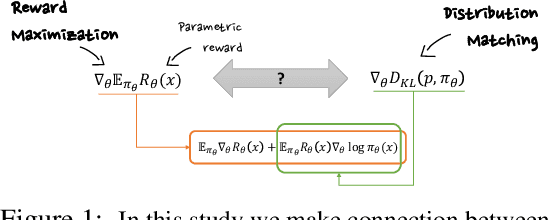
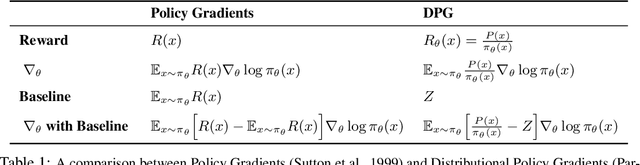
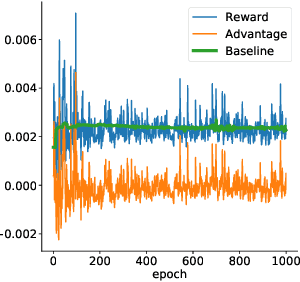

The availability of large pre-trained models is changing the landscape of Machine Learning research and practice, moving from a training-from-scratch to a fine-tuning paradigm. While in some applications the goal is to "nudge" the pre-trained distribution towards preferred outputs, in others it is to steer it towards a different distribution over the sample space. Two main paradigms have emerged to tackle this challenge: Reward Maximization (RM) and, more recently, Distribution Matching (DM). RM applies standard Reinforcement Learning (RL) techniques, such as Policy Gradients, to gradually increase the reward signal. DM prescribes to first make explicit the target distribution that the model is fine-tuned to approximate. Here we explore the theoretical connections between the two paradigms, and show that methods such as KL-control developed for RM can also be construed as belonging to DM. We further observe that while DM differs from RM, it can suffer from similar training difficulties, such as high gradient variance. We leverage connections between the two paradigms to import the concept of baseline into DM methods. We empirically validate the benefits of adding a baseline on an array of controllable language generation tasks such as constraining topic, sentiment, and gender distributions in texts sampled from a language model. We observe superior performance in terms of constraint satisfaction, stability and sample efficiency.
Sampling from Discrete Energy-Based Models with Quality/Efficiency Trade-offs
Dec 10, 2021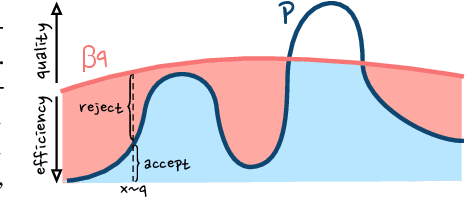

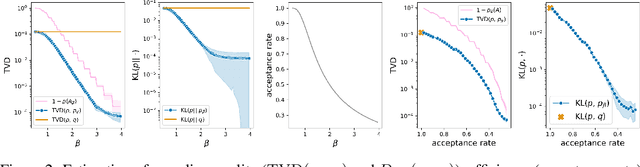
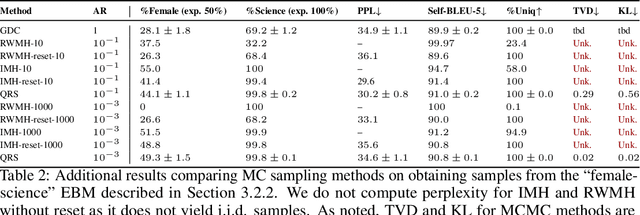
Energy-Based Models (EBMs) allow for extremely flexible specifications of probability distributions. However, they do not provide a mechanism for obtaining exact samples from these distributions. Monte Carlo techniques can aid us in obtaining samples if some proposal distribution that we can easily sample from is available. For instance, rejection sampling can provide exact samples but is often difficult or impossible to apply due to the need to find a proposal distribution that upper-bounds the target distribution everywhere. Approximate Markov chain Monte Carlo sampling techniques like Metropolis-Hastings are usually easier to design, exploiting a local proposal distribution that performs local edits on an evolving sample. However, these techniques can be inefficient due to the local nature of the proposal distribution and do not provide an estimate of the quality of their samples. In this work, we propose a new approximate sampling technique, Quasi Rejection Sampling (QRS), that allows for a trade-off between sampling efficiency and sampling quality, while providing explicit convergence bounds and diagnostics. QRS capitalizes on the availability of high-quality global proposal distributions obtained from deep learning models. We demonstrate the effectiveness of QRS sampling for discrete EBMs over text for the tasks of controlled text generation with distributional constraints and paraphrase generation. We show that we can sample from such EBMs with arbitrary precision at the cost of sampling efficiency.
Unsupervised and Distributional Detection of Machine-Generated Text
Nov 04, 2021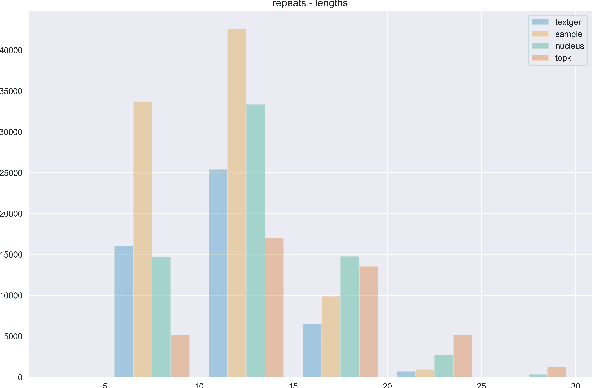
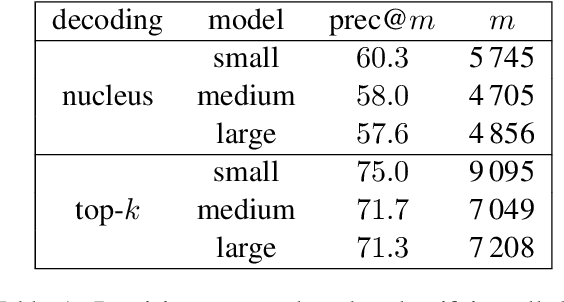

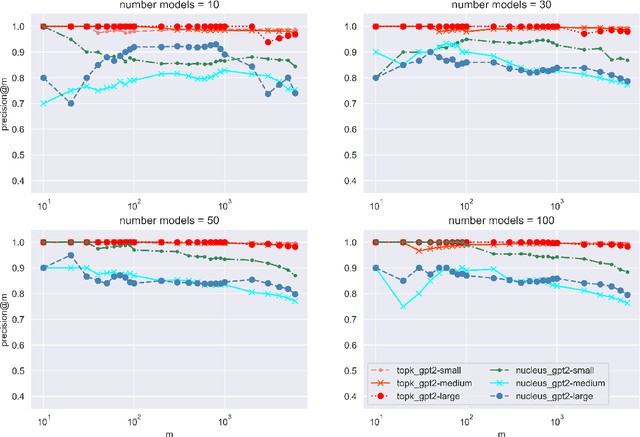
The power of natural language generation models has provoked a flurry of interest in automatic methods to detect if a piece of text is human or machine-authored. The problem so far has been framed in a standard supervised way and consists in training a classifier on annotated data to predict the origin of one given new document. In this paper, we frame the problem in an unsupervised and distributional way: we assume that we have access to a large collection of unannotated documents, a big fraction of which is machine-generated. We propose a method to detect those machine-generated documents leveraging repeated higher-order n-grams, which we show over-appear in machine-generated text as compared to human ones. That weak signal is the starting point of a self-training setting where pseudo-labelled documents are used to train an ensemble of classifiers. Our experiments show that leveraging that signal allows us to rank suspicious documents accurately. Precision at 5000 is over 90% for top-k sampling strategies, and over 80% for nucleus sampling for the largest model we used (GPT2-large). The drop with increased size of model is small, which could indicate that the results hold for other current and future large language models.