 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThrough the Judge's Eyes: Inferred Thinking Traces Improve Reliability of LLM Raters
Oct 29, 2025Large language models (LLMs) are increasingly used as raters for evaluation tasks. However, their reliability is often limited for subjective tasks, when human judgments involve subtle reasoning beyond annotation labels. Thinking traces, the reasoning behind a judgment, are highly informative but challenging to collect and curate. We present a human-LLM collaborative framework to infer thinking traces from label-only annotations. The proposed framework uses a simple and effective rejection sampling method to reconstruct these traces at scale. These inferred thinking traces are applied to two complementary tasks: (1) fine-tuning open LLM raters; and (2) synthesizing clearer annotation guidelines for proprietary LLM raters. Across multiple datasets, our methods lead to significantly improved LLM-human agreement. Additionally, the refined annotation guidelines increase agreement among different LLM models. These results suggest that LLMs can serve as practical proxies for otherwise unrevealed human thinking traces, enabling label-only corpora to be extended into thinking-trace-augmented resources that enhance the reliability of LLM raters.
Predicting Individual Treatment Effects of Large-scale Team Competitions in a Ride-sharing Economy
Aug 07, 2020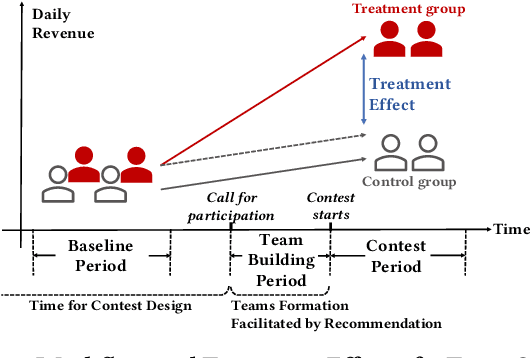

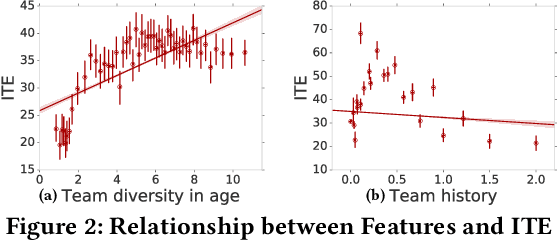
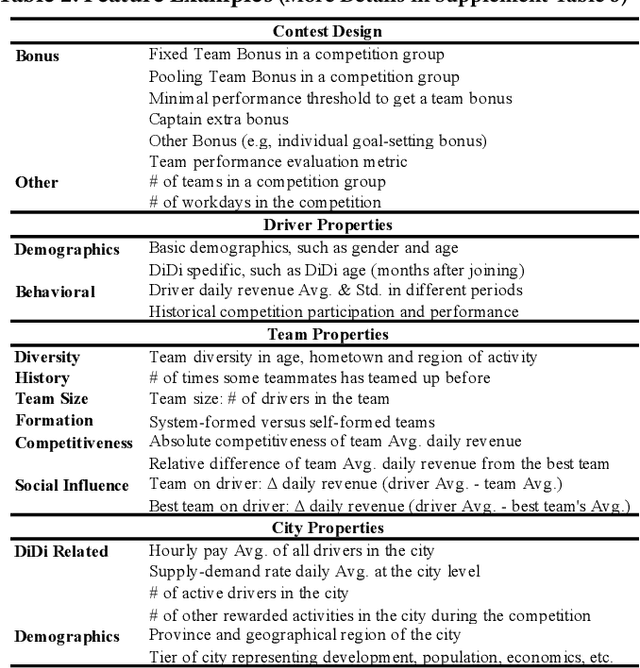
Millions of drivers worldwide have enjoyed financial benefits and work schedule flexibility through a ride-sharing economy, but meanwhile they have suffered from the lack of a sense of identity and career achievement. Equipped with social identity and contest theories, financially incentivized team competitions have been an effective instrument to increase drivers' productivity, job satisfaction, and retention, and to improve revenue over cost for ride-sharing platforms. While these competitions are overall effective, the decisive factors behind the treatment effects and how they affect the outcomes of individual drivers have been largely mysterious. In this study, we analyze data collected from more than 500 large-scale team competitions organized by a leading ride-sharing platform, building machine learning models to predict individual treatment effects. Through a careful investigation of features and predictors, we are able to reduce out-sample prediction error by more than 24%. Through interpreting the best-performing models, we discover many novel and actionable insights regarding how to optimize the design and the execution of team competitions on ride-sharing platforms. A simulated analysis demonstrates that by simply changing a few contest design options, the average treatment effect of a real competition is expected to increase by as much as 26%. Our procedure and findings shed light on how to analyze and optimize large-scale online field experiments in general.