 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEngagement Process: Rethinking the Temporal Interface of Action and Observation
May 12, 2026Task completion in digital and physical environments increasingly involves complex temporal interaction, where actions and observations unfold over different time scales rather than align with fixed observation--action steps. To model such interactions, we propose \emph{Engagement Process} (EP), an interaction formalism that inherits the decision-theoretic structure of POMDPs while making time explicit in the action--observation interface. EP represents actions and observations as decoupled event streams along time, rather than updates paired at fixed decision steps. This interface captures single-agent timing issues such as deliberation latency, delayed feedback, and persistent actions, while supporting richer agent-side organization, multi-rate coordination, and compositional interaction among subsystems. Across toy, LLM-agent, and learning experiments, EP exposes temporal behaviors hidden by step-based interfaces and enables policies to adapt under explicit time costs.
Self-NPO: Negative Preference Optimization of Diffusion Models by Simply Learning from Itself without Explicit Preference Annotations
May 17, 2025Diffusion models have demonstrated remarkable success in various visual generation tasks, including image, video, and 3D content generation. Preference optimization (PO) is a prominent and growing area of research that aims to align these models with human preferences. While existing PO methods primarily concentrate on producing favorable outputs, they often overlook the significance of classifier-free guidance (CFG) in mitigating undesirable results. Diffusion-NPO addresses this gap by introducing negative preference optimization (NPO), training models to generate outputs opposite to human preferences and thereby steering them away from unfavorable outcomes. However, prior NPO approaches, including Diffusion-NPO, rely on costly and fragile procedures for obtaining explicit preference annotations (e.g., manual pairwise labeling or reward model training), limiting their practicality in domains where such data are scarce or difficult to acquire. In this work, we introduce Self-NPO, a Negative Preference Optimization approach that learns exclusively from the model itself, thereby eliminating the need for manual data labeling or reward model training. Moreover, our method is highly efficient and does not require exhaustive data sampling. We demonstrate that Self-NPO integrates seamlessly into widely used diffusion models, including SD1.5, SDXL, and CogVideoX, as well as models already optimized for human preferences, consistently enhancing both their generation quality and alignment with human preferences.
Ideas in Inference-time Scaling can Benefit Generative Pre-training Algorithms
Mar 11, 2025
Recent years have seen significant advancements in foundation models through generative pre-training, yet algorithmic innovation in this space has largely stagnated around autoregressive models for discrete signals and diffusion models for continuous signals. This stagnation creates a bottleneck that prevents us from fully unlocking the potential of rich multi-modal data, which in turn limits the progress on multimodal intelligence. We argue that an inference-first perspective, which prioritizes scaling efficiency during inference time across sequence length and refinement steps, can inspire novel generative pre-training algorithms. Using Inductive Moment Matching (IMM) as a concrete example, we demonstrate how addressing limitations in diffusion models' inference process through targeted modifications yields a stable, single-stage algorithm that achieves superior sample quality with over an order of magnitude greater inference efficiency.
Inductive Moment Matching
Mar 11, 2025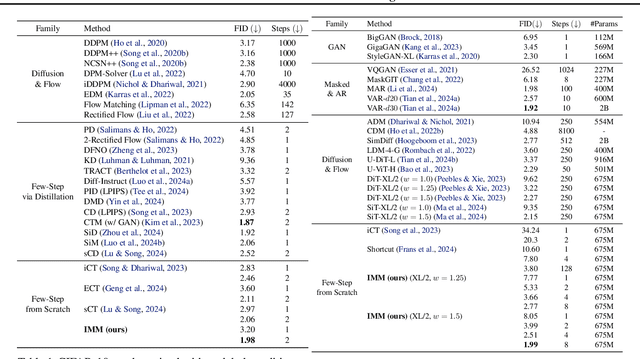
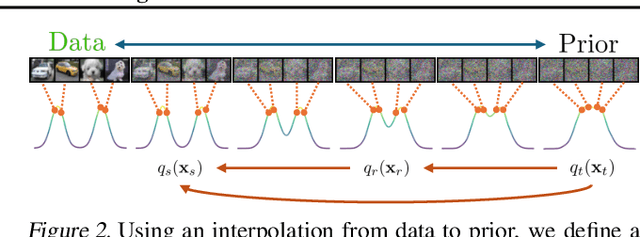
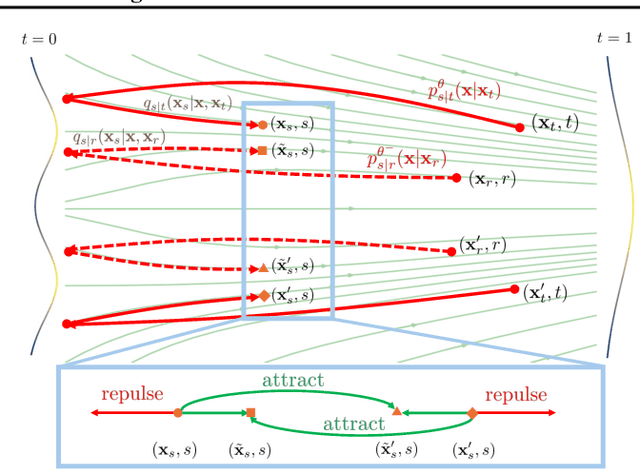
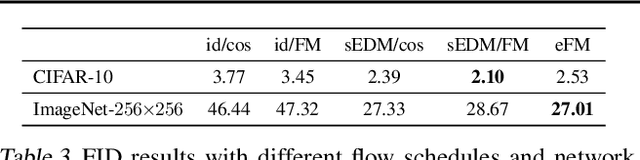
Diffusion models and Flow Matching generate high-quality samples but are slow at inference, and distilling them into few-step models often leads to instability and extensive tuning. To resolve these trade-offs, we propose Inductive Moment Matching (IMM), a new class of generative models for one- or few-step sampling with a single-stage training procedure. Unlike distillation, IMM does not require pre-training initialization and optimization of two networks; and unlike Consistency Models, IMM guarantees distribution-level convergence and remains stable under various hyperparameters and standard model architectures. IMM surpasses diffusion models on ImageNet-256x256 with 1.99 FID using only 8 inference steps and achieves state-of-the-art 2-step FID of 1.98 on CIFAR-10 for a model trained from scratch.
Personalized Preference Fine-tuning of Diffusion Models
Jan 11, 2025



RLHF techniques like DPO can significantly improve the generation quality of text-to-image diffusion models. However, these methods optimize for a single reward that aligns model generation with population-level preferences, neglecting the nuances of individual users' beliefs or values. This lack of personalization limits the efficacy of these models. To bridge this gap, we introduce PPD, a multi-reward optimization objective that aligns diffusion models with personalized preferences. With PPD, a diffusion model learns the individual preferences of a population of users in a few-shot way, enabling generalization to unseen users. Specifically, our approach (1) leverages a vision-language model (VLM) to extract personal preference embeddings from a small set of pairwise preference examples, and then (2) incorporates the embeddings into diffusion models through cross attention. Conditioning on user embeddings, the text-to-image models are fine-tuned with the DPO objective, simultaneously optimizing for alignment with the preferences of multiple users. Empirical results demonstrate that our method effectively optimizes for multiple reward functions and can interpolate between them during inference. In real-world user scenarios, with as few as four preference examples from a new user, our approach achieves an average win rate of 76\% over Stable Cascade, generating images that more accurately reflect specific user preferences.
Decentralized Diffusion Models
Jan 10, 2025Large-scale AI model training divides work across thousands of GPUs, then synchronizes gradients across them at each step. This incurs a significant network burden that only centralized, monolithic clusters can support, driving up infrastructure costs and straining power systems. We propose Decentralized Diffusion Models, a scalable framework for distributing diffusion model training across independent clusters or datacenters by eliminating the dependence on a centralized, high-bandwidth networking fabric. Our method trains a set of expert diffusion models over partitions of the dataset, each in full isolation from one another. At inference time, the experts ensemble through a lightweight router. We show that the ensemble collectively optimizes the same objective as a single model trained over the whole dataset. This means we can divide the training burden among a number of "compute islands," lowering infrastructure costs and improving resilience to localized GPU failures. Decentralized diffusion models empower researchers to take advantage of smaller, more cost-effective and more readily available compute like on-demand GPU nodes rather than central integrated systems. We conduct extensive experiments on ImageNet and LAION Aesthetics, showing that decentralized diffusion models FLOP-for-FLOP outperform standard diffusion models. We finally scale our approach to 24 billion parameters, demonstrating that high-quality diffusion models can now be trained with just eight individual GPU nodes in less than a week.
Edify Image: High-Quality Image Generation with Pixel Space Laplacian Diffusion Models
Nov 11, 2024We introduce Edify Image, a family of diffusion models capable of generating photorealistic image content with pixel-perfect accuracy. Edify Image utilizes cascaded pixel-space diffusion models trained using a novel Laplacian diffusion process, in which image signals at different frequency bands are attenuated at varying rates. Edify Image supports a wide range of applications, including text-to-image synthesis, 4K upsampling, ControlNets, 360 HDR panorama generation, and finetuning for image customization.
AGG: Amortized Generative 3D Gaussians for Single Image to 3D
Jan 08, 2024



Given the growing need for automatic 3D content creation pipelines, various 3D representations have been studied to generate 3D objects from a single image. Due to its superior rendering efficiency, 3D Gaussian splatting-based models have recently excelled in both 3D reconstruction and generation. 3D Gaussian splatting approaches for image to 3D generation are often optimization-based, requiring many computationally expensive score-distillation steps. To overcome these challenges, we introduce an Amortized Generative 3D Gaussian framework (AGG) that instantly produces 3D Gaussians from a single image, eliminating the need for per-instance optimization. Utilizing an intermediate hybrid representation, AGG decomposes the generation of 3D Gaussian locations and other appearance attributes for joint optimization. Moreover, we propose a cascaded pipeline that first generates a coarse representation of the 3D data and later upsamples it with a 3D Gaussian super-resolution module. Our method is evaluated against existing optimization-based 3D Gaussian frameworks and sampling-based pipelines utilizing other 3D representations, where AGG showcases competitive generation abilities both qualitatively and quantitatively while being several orders of magnitude faster. Project page: https://ir1d.github.io/AGG/
DiffiT: Diffusion Vision Transformers for Image Generation
Dec 04, 2023



Diffusion models with their powerful expressivity and high sample quality have enabled many new applications and use-cases in various domains. For sample generation, these models rely on a denoising neural network that generates images by iterative denoising. Yet, the role of denoising network architecture is not well-studied with most efforts relying on convolutional residual U-Nets. In this paper, we study the effectiveness of vision transformers in diffusion-based generative learning. Specifically, we propose a new model, denoted as Diffusion Vision Transformers (DiffiT), which consists of a hybrid hierarchical architecture with a U-shaped encoder and decoder. We introduce a novel time-dependent self-attention module that allows attention layers to adapt their behavior at different stages of the denoising process in an efficient manner. We also introduce latent DiffiT which consists of transformer model with the proposed self-attention layers, for high-resolution image generation. Our results show that DiffiT is surprisingly effective in generating high-fidelity images, and it achieves state-of-the-art (SOTA) benchmarks on a variety of class-conditional and unconditional synthesis tasks. In the latent space, DiffiT achieves a new SOTA FID score of 1.73 on ImageNet-256 dataset. Repository: https://github.com/NVlabs/DiffiT
SMRD: SURE-based Robust MRI Reconstruction with Diffusion Models
Oct 18, 2023Diffusion models have recently gained popularity for accelerated MRI reconstruction due to their high sample quality. They can effectively serve as rich data priors while incorporating the forward model flexibly at inference time, and they have been shown to be more robust than unrolled methods under distribution shifts. However, diffusion models require careful tuning of inference hyperparameters on a validation set and are still sensitive to distribution shifts during testing. To address these challenges, we introduce SURE-based MRI Reconstruction with Diffusion models (SMRD), a method that performs test-time hyperparameter tuning to enhance robustness during testing. SMRD uses Stein's Unbiased Risk Estimator (SURE) to estimate the mean squared error of the reconstruction during testing. SURE is then used to automatically tune the inference hyperparameters and to set an early stopping criterion without the need for validation tuning. To the best of our knowledge, SMRD is the first to incorporate SURE into the sampling stage of diffusion models for automatic hyperparameter selection. SMRD outperforms diffusion model baselines on various measurement noise levels, acceleration factors, and anatomies, achieving a PSNR improvement of up to 6 dB under measurement noise. The code is publicly available at https://github.com/NVlabs/SMRD .