 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the influence of attractor-verb distance on grammatical agreement in humans and language models
Nov 28, 2023



Subject-verb agreement in the presence of an attractor noun located between the main noun and the verb elicits complex behavior: judgments of grammaticality are modulated by the grammatical features of the attractor. For example, in the sentence "The girl near the boys likes climbing", the attractor (boys) disagrees in grammatical number with the verb (likes), creating a locally implausible transition probability. Here, we parametrically modulate the distance between the attractor and the verb while keeping the length of the sentence equal. We evaluate the performance of both humans and two artificial neural network models: both make more mistakes when the attractor is closer to the verb, but neural networks get close to the chance level while humans are mostly able to overcome the attractor interference. Additionally, we report a linear effect of attractor distance on reaction times. We hypothesize that a possible reason for the proximity effect is the calculation of transition probabilities between adjacent words. Nevertheless, classical models of attraction such as the cue-based model might suffice to explain this phenomenon, thus paving the way for new research. Data and analyses available at https://osf.io/d4g6k
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Causal Transformers Perform Below Chance on Recursive Nested Constructions, Unlike Humans
Oct 14, 2021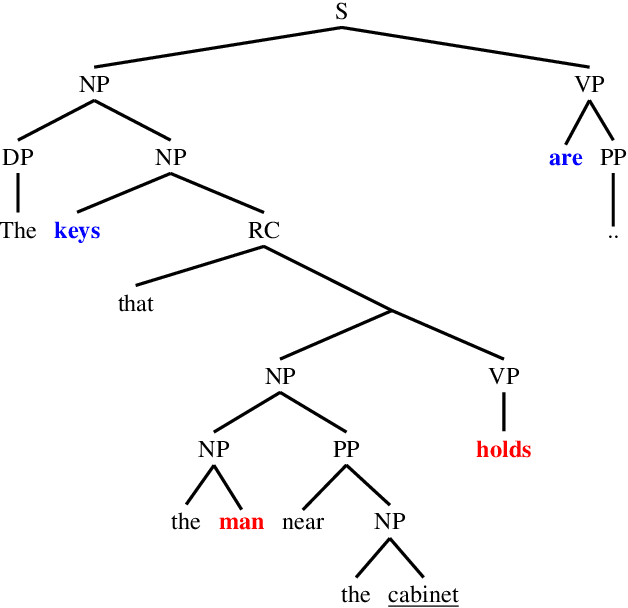
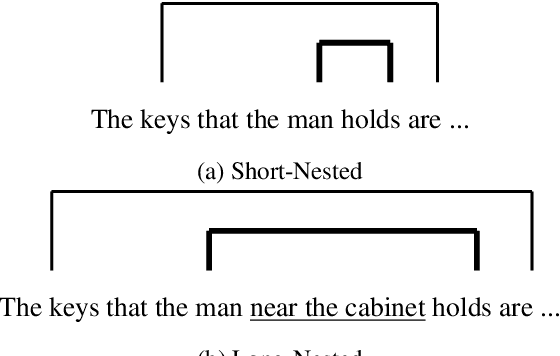
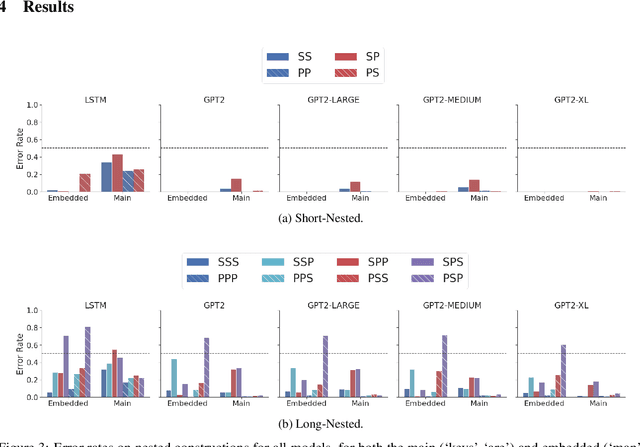
Recursive processing is considered a hallmark of human linguistic abilities. A recent study evaluated recursive processing in recurrent neural language models (RNN-LMs) and showed that such models perform below chance level on embedded dependencies within nested constructions -- a prototypical example of recursion in natural language. Here, we study if state-of-the-art Transformer LMs do any better. We test four different Transformer LMs on two different types of nested constructions, which differ in whether the embedded (inner) dependency is short or long range. We find that Transformers achieve near-perfect performance on short-range embedded dependencies, significantly better than previous results reported for RNN-LMs and humans. However, on long-range embedded dependencies, Transformers' performance sharply drops below chance level. Remarkably, the addition of only three words to the embedded dependency caused Transformers to fall from near-perfect to below-chance performance. Taken together, our results reveal Transformers' shortcoming when it comes to recursive, structure-based, processing.
Can RNNs learn Recursive Nested Subject-Verb Agreements?
Jan 06, 2021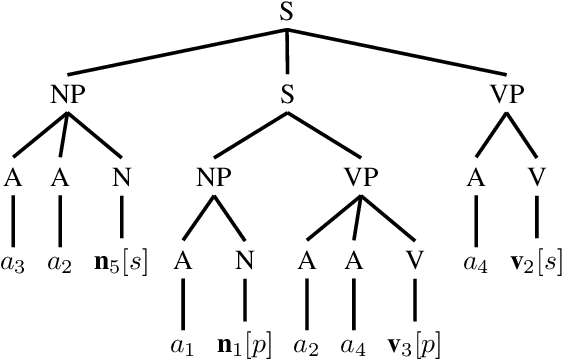
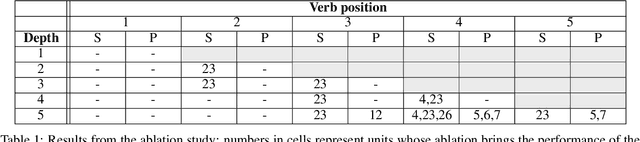
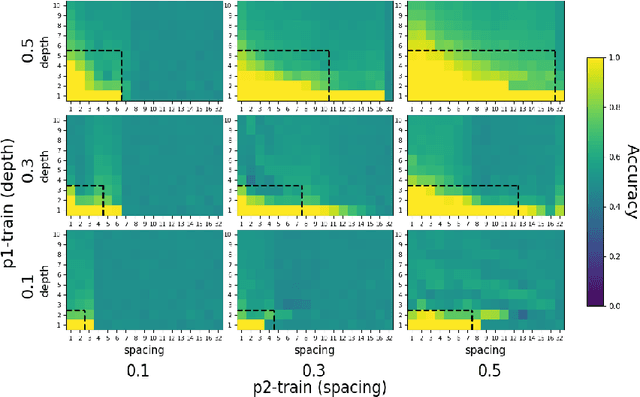
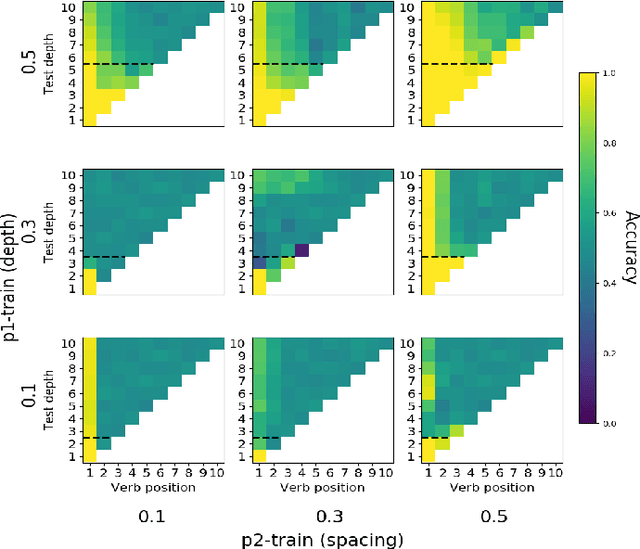
One of the fundamental principles of contemporary linguistics states that language processing requires the ability to extract recursively nested tree structures. However, it remains unclear whether and how this code could be implemented in neural circuits. Recent advances in Recurrent Neural Networks (RNNs), which achieve near-human performance in some language tasks, provide a compelling model to address such questions. Here, we present a new framework to study recursive processing in RNNs, using subject-verb agreement as a probe into the representations of the neural network. We trained six distinct types of RNNs on a simplified probabilistic context-free grammar designed to independently manipulate the length of a sentence and the depth of its syntactic tree. All RNNs generalized to subject-verb dependencies longer than those seen during training. However, none systematically generalized to deeper tree structures, even those with a structural bias towards learning nested tree (i.e., stack-RNNs). In addition, our analyses revealed primacy and recency effects in the generalization patterns of LSTM-based models, showing that these models tend to perform well on the outer- and innermost parts of a center-embedded tree structure, but poorly on its middle levels. Finally, probing the internal states of the model during the processing of sentences with nested tree structures, we found a complex encoding of grammatical agreement information (e.g. grammatical number), in which all the information for multiple words nouns was carried by a single unit. Taken together, these results indicate how neural networks may extract bounded nested tree structures, without learning a systematic recursive rule.