 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARC-AGI-2: A New Challenge for Frontier AI Reasoning Systems
May 17, 2025The Abstraction and Reasoning Corpus for Artificial General Intelligence (ARC-AGI), introduced in 2019, established a challenging benchmark for evaluating the general fluid intelligence of artificial systems via a set of unique, novel tasks only requiring minimal prior knowledge. While ARC-AGI has spurred significant research activity over the past five years, recent AI progress calls for benchmarks capable of finer-grained evaluation at higher levels of cognitive complexity. We introduce ARC-AGI-2, an upgraded version of the benchmark. ARC-AGI-2 preserves the input-output pair task format of its predecessor, ensuring continuity for researchers. It incorporates a newly curated and expanded set of tasks specifically designed to provide a more granular signal to assess abstract reasoning and problem-solving abilities at higher levels of fluid intelligence. To contextualize the difficulty and characteristics of ARC-AGI-2, we present extensive results from human testing, providing a robust baseline that highlights the benchmark's accessibility to human intelligence, yet difficulty for current AI systems. ARC-AGI-2 aims to serve as a next-generation tool for rigorously measuring progress towards more general and human-like AI capabilities.
ARC Prize 2024: Technical Report
Dec 05, 2024



As of December 2024, the ARC-AGI benchmark is five years old and remains unbeaten. We believe it is currently the most important unsolved AI benchmark in the world because it seeks to measure generalization on novel tasks -- the essence of intelligence -- as opposed to skill at tasks that can be prepared for in advance. This year, we launched ARC Prize, a global competition to inspire new ideas and drive open progress towards AGI by reaching a target benchmark score of 85\%. As a result, the state-of-the-art score on the ARC-AGI private evaluation set increased from 33\% to 55.5\%, propelled by several frontier AGI reasoning techniques including deep learning-guided program synthesis and test-time training. In this paper, we survey top approaches, review new open-source implementations, discuss the limitations of the ARC-AGI-1 dataset, and share key insights gained from the competition.
KerasCV and KerasNLP: Vision and Language Power-Ups
May 31, 2024
We present the Keras domain packages KerasCV and KerasNLP, extensions of the Keras API for Computer Vision and Natural Language Processing workflows, capable of running on either JAX, TensorFlow, or PyTorch. These domain packages are designed to enable fast experimentation, with a focus on ease-of-use and performance. We adopt a modular, layered design: at the library's lowest level of abstraction, we provide building blocks for creating models and data preprocessing pipelines, and at the library's highest level of abstraction, we provide pretrained ``task" models for popular architectures such as Stable Diffusion, YOLOv8, GPT2, BERT, Mistral, CLIP, Gemma, T5, etc. Task models have built-in preprocessing, pretrained weights, and can be fine-tuned on raw inputs. To enable efficient training, we support XLA compilation for all models, and run all preprocessing via a compiled graph of TensorFlow operations using the tf.data API. The libraries are fully open-source (Apache 2.0 license) and available on GitHub.
Efficient Graph-Friendly COCO Metric Computation for Train-Time Model Evaluation
Jul 21, 2022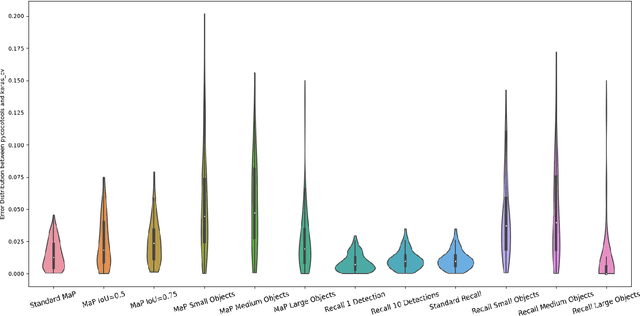
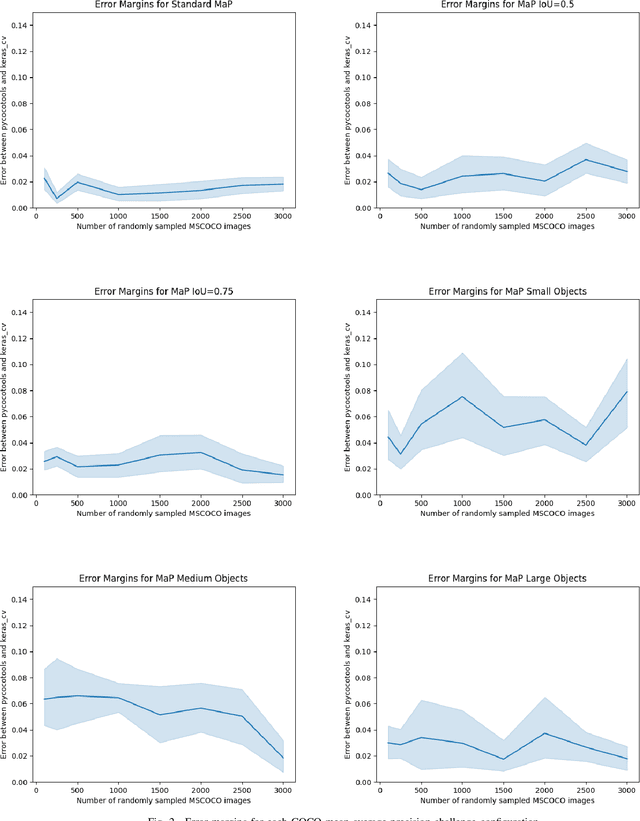
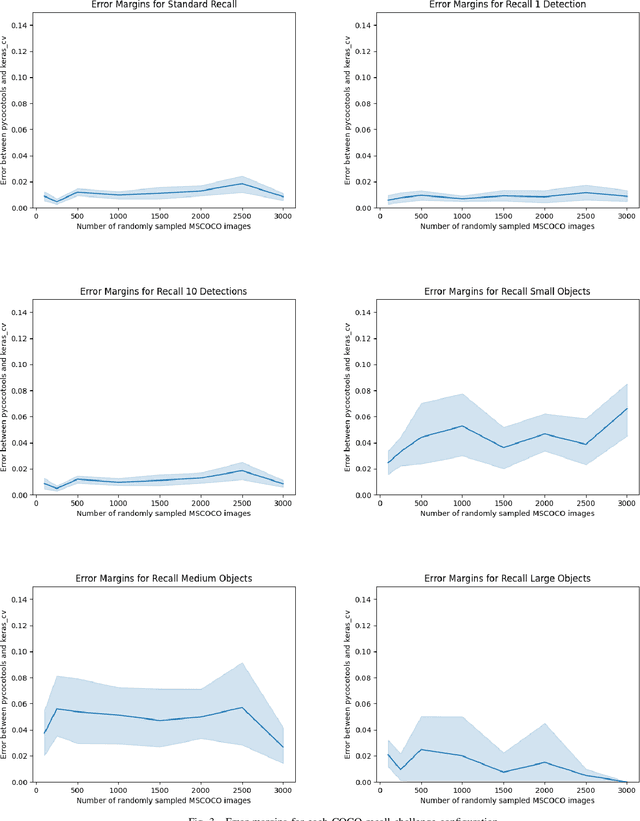
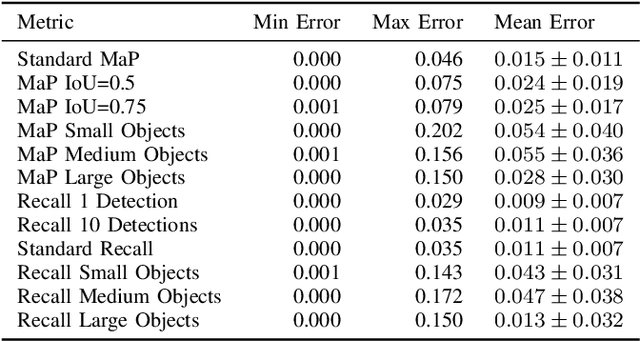
Evaluating the COCO mean average precision (MaP) and COCO recall metrics as part of the static computation graph of modern deep learning frameworks poses a unique set of challenges. These challenges include the need for maintaining a dynamic-sized state to compute mean average precision, reliance on global dataset-level statistics to compute the metrics, and managing differing numbers of bounding boxes between images in a batch. As a consequence, it is common practice for researchers and practitioners to evaluate COCO metrics as a post training evaluation step. With a graph-friendly algorithm to compute COCO Mean Average Precision and recall, these metrics could be evaluated at training time, improving visibility into the evolution of the metrics through training curve plots, and decreasing iteration time when prototyping new model versions. Our contributions include an accurate approximation algorithm for Mean Average Precision, an open source implementation of both COCO mean average precision and COCO recall, extensive numerical benchmarks to verify the accuracy of our implementations, and an open-source training loop that include train-time evaluation of mean average precision and recall.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Tensor2Tensor for Neural Machine Translation
Mar 16, 2018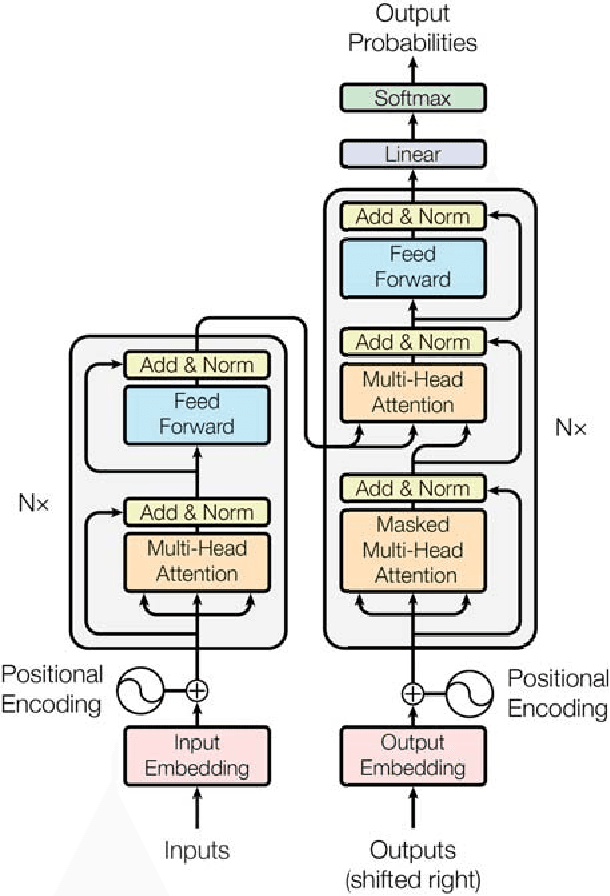
Tensor2Tensor is a library for deep learning models that is well-suited for neural machine translation and includes the reference implementation of the state-of-the-art Transformer model.
Depthwise Separable Convolutions for Neural Machine Translation
Jun 16, 2017
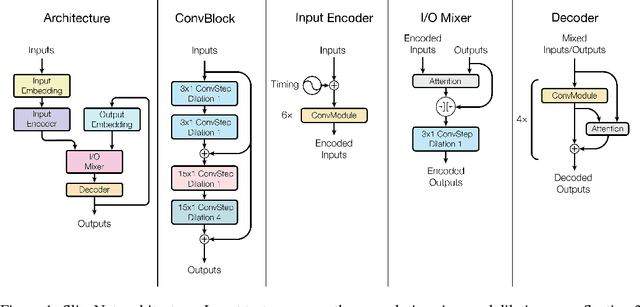
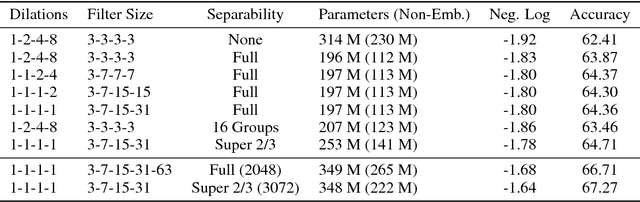
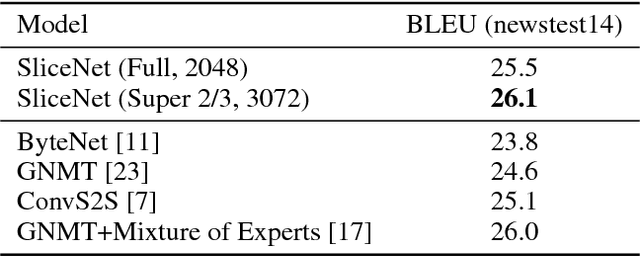
Depthwise separable convolutions reduce the number of parameters and computation used in convolutional operations while increasing representational efficiency. They have been shown to be successful in image classification models, both in obtaining better models than previously possible for a given parameter count (the Xception architecture) and considerably reducing the number of parameters required to perform at a given level (the MobileNets family of architectures). Recently, convolutional sequence-to-sequence networks have been applied to machine translation tasks with good results. In this work, we study how depthwise separable convolutions can be applied to neural machine translation. We introduce a new architecture inspired by Xception and ByteNet, called SliceNet, which enables a significant reduction of the parameter count and amount of computation needed to obtain results like ByteNet, and, with a similar parameter count, achieves new state-of-the-art results. In addition to showing that depthwise separable convolutions perform well for machine translation, we investigate the architectural changes that they enable: we observe that thanks to depthwise separability, we can increase the length of convolution windows, removing the need for filter dilation. We also introduce a new "super-separable" convolution operation that further reduces the number of parameters and computational cost for obtaining state-of-the-art results.
DeepMath - Deep Sequence Models for Premise Selection
Jan 26, 2017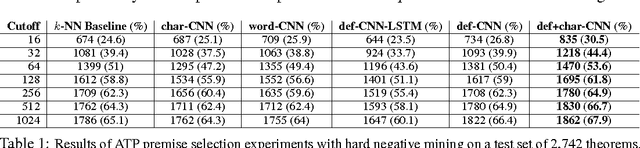
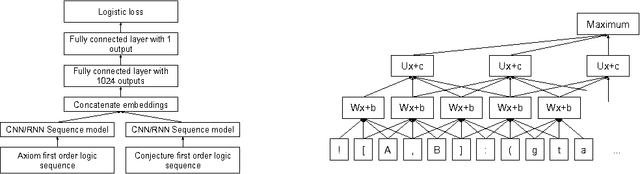
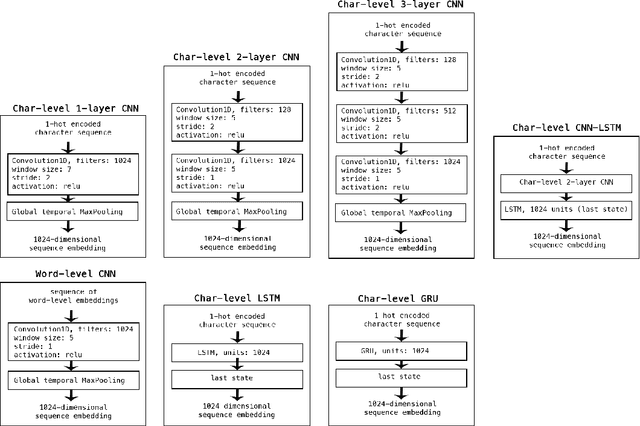
We study the effectiveness of neural sequence models for premise selection in automated theorem proving, one of the main bottlenecks in the formalization of mathematics. We propose a two stage approach for this task that yields good results for the premise selection task on the Mizar corpus while avoiding the hand-engineered features of existing state-of-the-art models. To our knowledge, this is the first time deep learning has been applied to theorem proving on a large scale.