 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopical-Chat: Towards Knowledge-Grounded Open-Domain Conversations
Aug 23, 2023



Building socialbots that can have deep, engaging open-domain conversations with humans is one of the grand challenges of artificial intelligence (AI). To this end, bots need to be able to leverage world knowledge spanning several domains effectively when conversing with humans who have their own world knowledge. Existing knowledge-grounded conversation datasets are primarily stylized with explicit roles for conversation partners. These datasets also do not explore depth or breadth of topical coverage with transitions in conversations. We introduce Topical-Chat, a knowledge-grounded human-human conversation dataset where the underlying knowledge spans 8 broad topics and conversation partners don't have explicitly defined roles, to help further research in open-domain conversational AI. We also train several state-of-the-art encoder-decoder conversational models on Topical-Chat and perform automated and human evaluation for benchmarking.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Alexa Conversations: An Extensible Data-driven Approach for Building Task-oriented Dialogue Systems
Apr 19, 2021
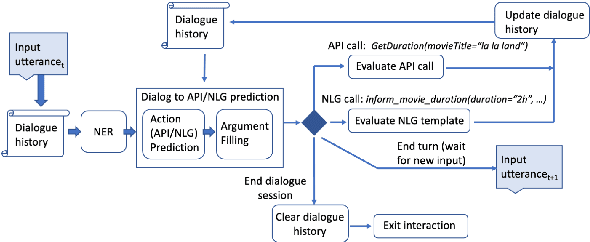

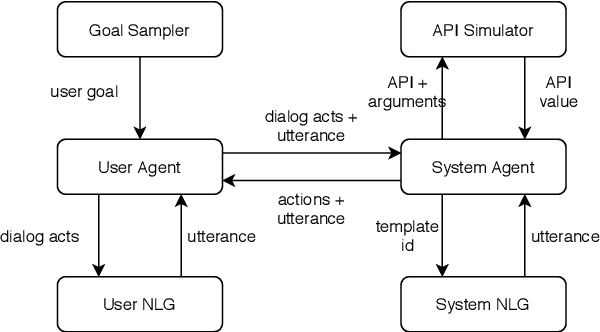
Traditional goal-oriented dialogue systems rely on various components such as natural language understanding, dialogue state tracking, policy learning and response generation. Training each component requires annotations which are hard to obtain for every new domain, limiting scalability of such systems. Similarly, rule-based dialogue systems require extensive writing and maintenance of rules and do not scale either. End-to-End dialogue systems, on the other hand, do not require module-specific annotations but need a large amount of data for training. To overcome these problems, in this demo, we present Alexa Conversations, a new approach for building goal-oriented dialogue systems that is scalable, extensible as well as data efficient. The components of this system are trained in a data-driven manner, but instead of collecting annotated conversations for training, we generate them using a novel dialogue simulator based on a few seed dialogues and specifications of APIs and entities provided by the developer. Our approach provides out-of-the-box support for natural conversational phenomena like entity sharing across turns or users changing their mind during conversation without requiring developers to provide any such dialogue flows. We exemplify our approach using a simple pizza ordering task and showcase its value in reducing the developer burden for creating a robust experience. Finally, we evaluate our system using a typical movie ticket booking task and show that the dialogue simulator is an essential component of the system that leads to over $50\%$ improvement in turn-level action signature prediction accuracy.
Towards Coherent and Engaging Spoken Dialog Response Generation Using Automatic Conversation Evaluators
May 02, 2019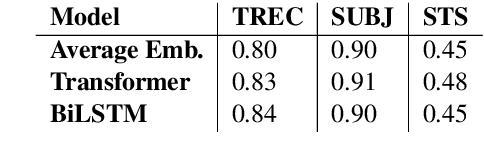
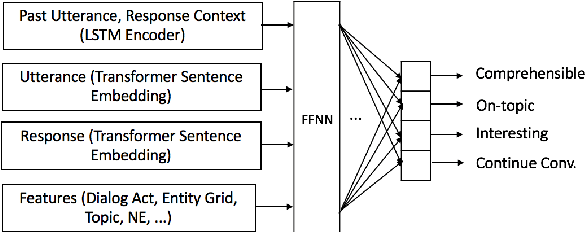
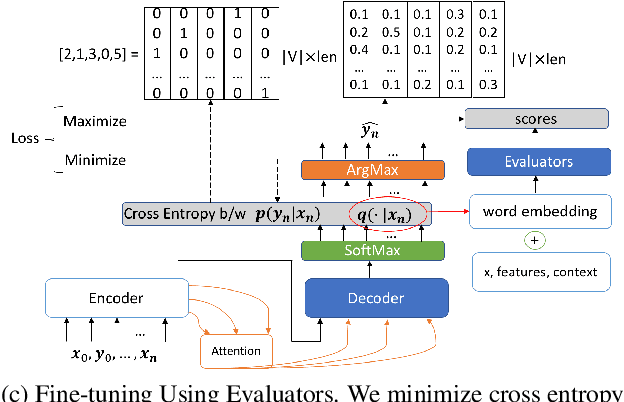

Encoder-decoder based neural architectures serve as the basis of state-of-the-art approaches in end-to-end open domain dialog systems. Since most of such systems are trained with a maximum likelihood(MLE) objective they suffer from issues such as lack of generalizability and the generic response problem, i.e., a system response that can be an answer to a large number of user utterances, e.g., "Maybe, I don't know." Having explicit feedback on the relevance and interestingness of a system response at each turn can be a useful signal for mitigating such issues and improving system quality by selecting responses from different approaches. Towards this goal, we present a system that evaluates chatbot responses at each dialog turn for coherence and engagement. Our system provides explicit turn-level dialog quality feedback, which we show to be highly correlated with human evaluation. To show that incorporating this feedback in the neural response generation models improves dialog quality, we present two different and complementary mechanisms to incorporate explicit feedback into a neural response generation model: reranking and direct modification of the loss function during training. Our studies show that a response generation model that incorporates these combined feedback mechanisms produce more engaging and coherent responses in an open-domain spoken dialog setting, significantly improving the response quality using both automatic and human evaluation.
Natural Language Generation at Scale: A Case Study for Open Domain Question Answering
Mar 19, 2019
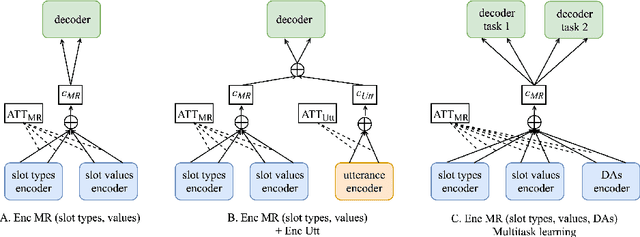
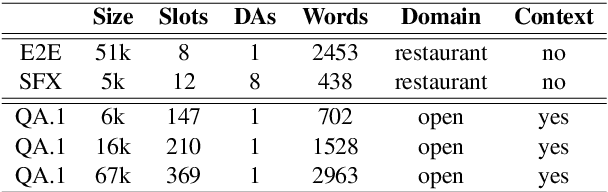

Current approaches to Natural Language Generation (NLG) focus on domain-specific, task-oriented dialogs (e.g. restaurant booking) using limited ontologies (up to 20 slot types), usually without considering the previous conversation context. Furthermore, these approaches require large amounts of data for each domain, and do not benefit from examples that may be available for other domains. This work explores the feasibility of statistical NLG for conversational applications with larger ontologies, which may be required by multi-domain dialog systems as well as open-domain knowledge graph based question answering (QA). We focus on modeling NLG through an Encoder-Decoder framework using a large dataset of interactions between real-world users and a conversational agent for open-domain QA. First, we investigate the impact of increasing the number of slot types on the generation quality and experiment with different partitions of the QA data with progressively larger ontologies (up to 369 slot types). Second, we explore multi-task learning for NLG and benchmark our model on a popular NLG dataset and perform experiments with open-domain QA and task-oriented dialog. Finally, we integrate conversation context by using context embeddings as an additional input for generation to improve response quality. Our experiments show the feasibility of learning statistical NLG models for open-domain contextual QA with larger ontologies.
Advancing the State of the Art in Open Domain Dialog Systems through the Alexa Prize
Dec 27, 2018
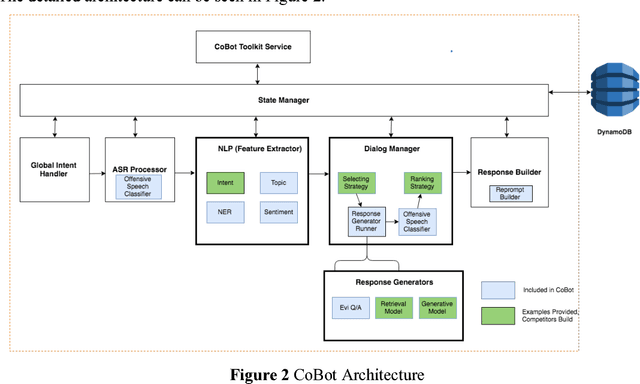
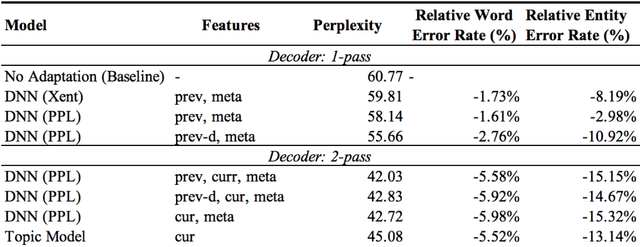
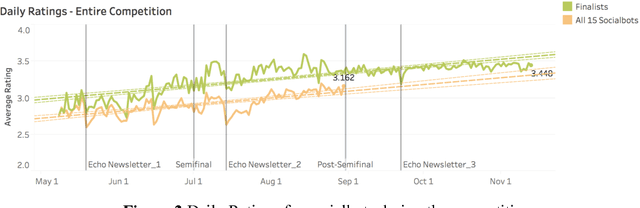
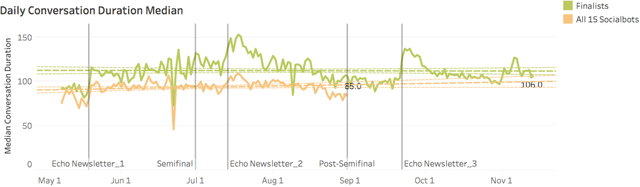
Building open domain conversational systems that allow users to have engaging conversations on topics of their choice is a challenging task. Alexa Prize was launched in 2016 to tackle the problem of achieving natural, sustained, coherent and engaging open-domain dialogs. In the second iteration of the competition in 2018, university teams advanced the state of the art by using context in dialog models, leveraging knowledge graphs for language understanding, handling complex utterances, building statistical and hierarchical dialog managers, and leveraging model-driven signals from user responses. The 2018 competition also included the provision of a suite of tools and models to the competitors including the CoBot (conversational bot) toolkit, topic and dialog act detection models, conversation evaluators, and a sensitive content detection model so that the competing teams could focus on building knowledge-rich, coherent and engaging multi-turn dialog systems. This paper outlines the advances developed by the university teams as well as the Alexa Prize team to achieve the common goal of advancing the science of Conversational AI. We address several key open-ended problems such as conversational speech recognition, open domain natural language understanding, commonsense reasoning, statistical dialog management, and dialog evaluation. These collaborative efforts have driven improved experiences by Alexa users to an average rating of 3.61, the median duration of 2 mins 18 seconds, and average turns to 14.6, increases of 14%, 92%, 54% respectively since the launch of the 2018 competition. For conversational speech recognition, we have improved our relative Word Error Rate by 55% and our relative Entity Error Rate by 34% since the launch of the Alexa Prize. Socialbots improved in quality significantly more rapidly in 2018, in part due to the release of the CoBot toolkit.
Detecting Offensive Content in Open-domain Conversations using Two Stage Semi-supervision
Nov 30, 2018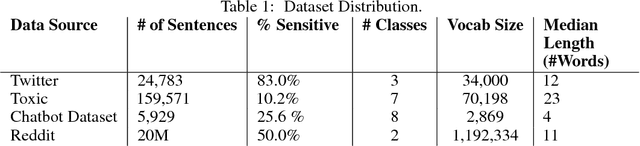
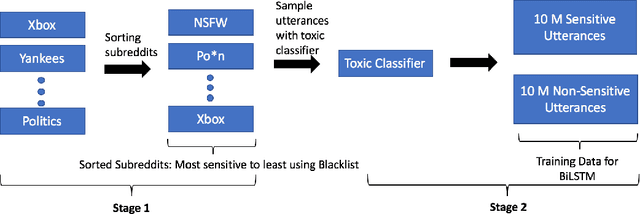
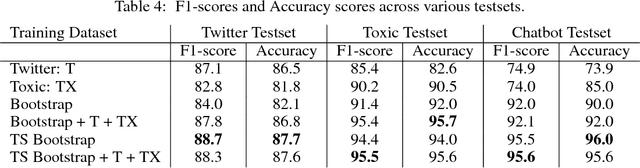
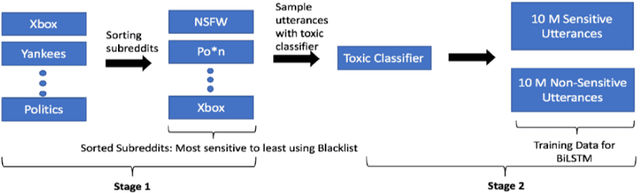
As open-ended human-chatbot interaction becomes commonplace, sensitive content detection gains importance. In this work, we propose a two stage semi-supervised approach to bootstrap large-scale data for automatic sensitive language detection from publicly available web resources. We explore various data selection methods including 1) using a blacklist to rank online discussion forums by the level of their sensitiveness followed by randomly sampling utterances and 2) training a weakly supervised model in conjunction with the blacklist for scoring sentences from online discussion forums to curate a dataset. Our data collection strategy is flexible and allows the models to detect implicit sensitive content for which manual annotations may be difficult. We train models using publicly available annotated datasets as well as using the proposed large-scale semi-supervised datasets. We evaluate the performance of all the models on Twitter and Toxic Wikipedia comments testsets as well as on a manually annotated spoken language dataset collected during a large scale chatbot competition. Results show that a model trained on this collected data outperforms the baseline models by a large margin on both in-domain and out-of-domain testsets, achieving an F1 score of 95.5% on an out-of-domain testset compared to a score of 75% for models trained on public datasets. We also showcase that large scale two stage semi-supervision generalizes well across multiple classes of sensitivities such as hate speech, racism, sexual and pornographic content, etc. without even providing explicit labels for these classes, leading to an average recall of 95.5% versus the models trained using annotated public datasets which achieve an average recall of 73.2% across seven sensitive classes on out-of-domain testsets.
Contextual Topic Modeling For Dialog Systems
Oct 19, 2018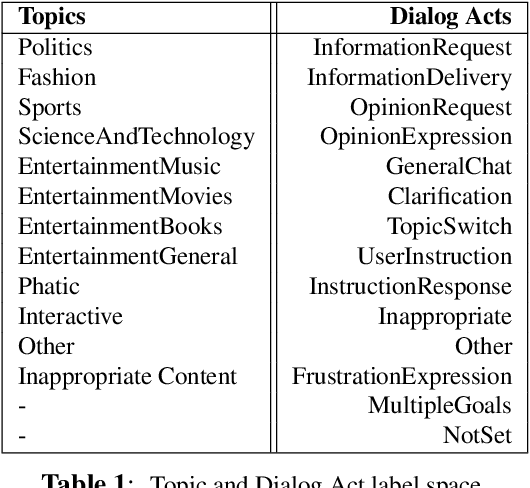
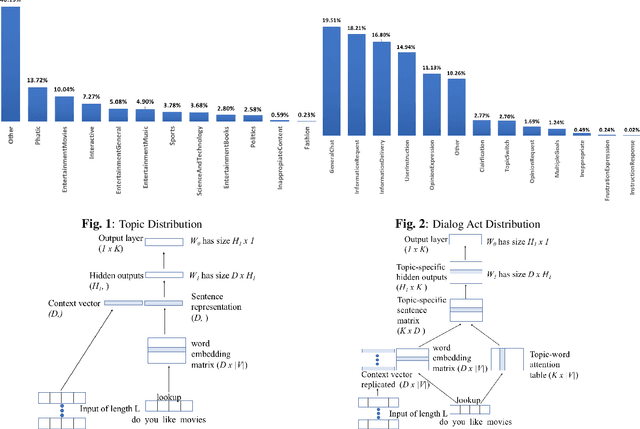

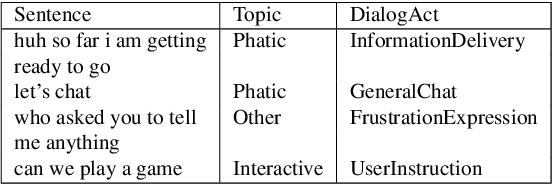
Accurate prediction of conversation topics can be a valuable signal for creating coherent and engaging dialog systems. In this work, we focus on context-aware topic classification methods for identifying topics in free-form human-chatbot dialogs. We extend previous work on neural topic classification and unsupervised topic keyword detection by incorporating conversational context and dialog act features. On annotated data, we show that incorporating context and dialog acts leads to relative gains in topic classification accuracy by 35% and on unsupervised keyword detection recall by 11% for conversational interactions where topics frequently span multiple utterances. We show that topical metrics such as topical depth is highly correlated with dialog evaluation metrics such as coherence and engagement implying that conversational topic models can predict user satisfaction. Our work for detecting conversation topics and keywords can be used to guide chatbots towards coherent dialog.
On Evaluating and Comparing Conversational Agents
Jan 11, 2018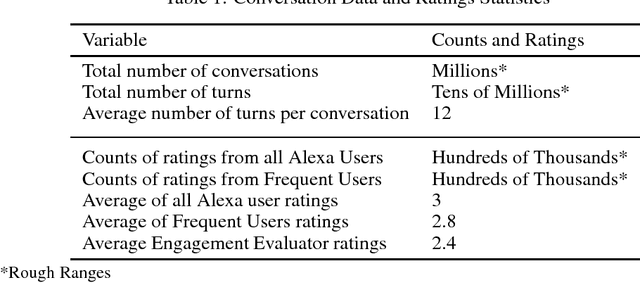
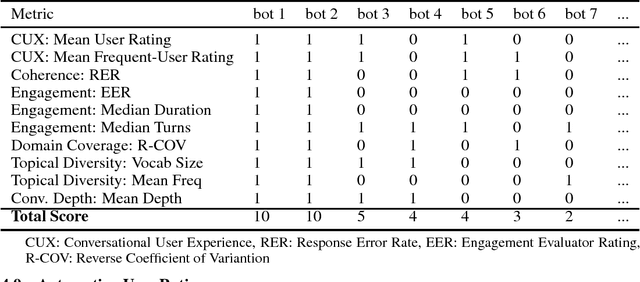
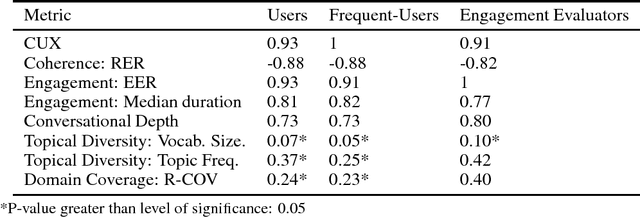

Conversational agents are exploding in popularity. However, much work remains in the area of non goal-oriented conversations, despite significant growth in research interest over recent years. To advance the state of the art in conversational AI, Amazon launched the Alexa Prize, a 2.5-million dollar university competition where sixteen selected university teams built conversational agents to deliver the best social conversational experience. Alexa Prize provided the academic community with the unique opportunity to perform research with a live system used by millions of users. The subjectivity associated with evaluating conversations is key element underlying the challenge of building non-goal oriented dialogue systems. In this paper, we propose a comprehensive evaluation strategy with multiple metrics designed to reduce subjectivity by selecting metrics which correlate well with human judgement. The proposed metrics provide granular analysis of the conversational agents, which is not captured in human ratings. We show that these metrics can be used as a reasonable proxy for human judgment. We provide a mechanism to unify the metrics for selecting the top performing agents, which has also been applied throughout the Alexa Prize competition. To our knowledge, to date it is the largest setting for evaluating agents with millions of conversations and hundreds of thousands of ratings from users. We believe that this work is a step towards an automatic evaluation process for conversational AIs.
* 10 pages, 5 tables. NIPS 2017 Conversational AI workshop. http://alborz-geramifard.com/workshops/nips17-Conversational-AI/Main.html
Conversational AI: The Science Behind the Alexa Prize
Jan 11, 2018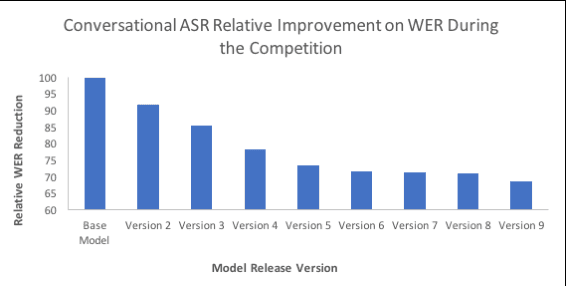
Conversational agents are exploding in popularity. However, much work remains in the area of social conversation as well as free-form conversation over a broad range of domains and topics. To advance the state of the art in conversational AI, Amazon launched the Alexa Prize, a 2.5-million-dollar university competition where sixteen selected university teams were challenged to build conversational agents, known as socialbots, to converse coherently and engagingly with humans on popular topics such as Sports, Politics, Entertainment, Fashion and Technology for 20 minutes. The Alexa Prize offers the academic community a unique opportunity to perform research with a live system used by millions of users. The competition provided university teams with real user conversational data at scale, along with the user-provided ratings and feedback augmented with annotations by the Alexa team. This enabled teams to effectively iterate and make improvements throughout the competition while being evaluated in real-time through live user interactions. To build their socialbots, university teams combined state-of-the-art techniques with novel strategies in the areas of Natural Language Understanding, Context Modeling, Dialog Management, Response Generation, and Knowledge Acquisition. To support the efforts of participating teams, the Alexa Prize team made significant scientific and engineering investments to build and improve Conversational Speech Recognition, Topic Tracking, Dialog Evaluation, Voice User Experience, and tools for traffic management and scalability. This paper outlines the advances created by the university teams as well as the Alexa Prize team to achieve the common goal of solving the problem of Conversational AI.
* 18 pages, 5 figures, Alexa Prize Proceedings Paper (https://developer.amazon.com/alexaprize/proceedings), Alexa Prize University Competition to advance Conversational AI